pandas之数据处理操作
1、pandas对缺失数据的处理
我们的数据缺失通常有两种情况:
1、一种就是空,None等,在pandas是NaN(和np.nan一样)
解决方法:
判断数据是否为NaN:pd.isnull(df),pd.notnull(df)
处理方式1:删除NaN所在的行列dropna (axis=0, how='any', inplace=False)
处理方式2:填充数据,t.fillna(t.mean()),t.fiallna(t.median()),t.fillna(0)
2、另一种是我们让其为0,蓝色框中
解决方法:
step1、处理为0的数据:t[t==0]=np.nan 当然并不是每次为0的数据都需要处理 计算平均值等情况,nan是不参与计算的,但是0会
step2、然后在对nan进行操作
注意:fiillna(t.mean())填充只针对该nan的列的平均值进行填充
2、常用的统计方法
df["name"].unique()#获取不重复的列表数据
df["name"].mean()#取平均值
df["name"].max()#取最大值
df["name"].min()#取最小值
df["name"].argmin()#取最小值位置
df["name"].argman()#取最大值位置
df["name"].median()#取中位数
3、pandas 实现one hot编码方式
1、重新构造一个全为0的数组,行名为分类,长度为原数据长度
zeros_df = pd.DataFrame(np.zeros((df.shape[0],len(cate_list))),columns=cate_list)
2、如果某一条数据中分类出现过,就让它由0变为1
方式1:
for cate in cate_list:
zeros_df[cate][df["title"].str.contains(cate)]=1

方式2:
for i in range(df.shape[0]):
zeros_df.loc[i][temp_list[i][0]] = 1
方式3:
cate_list = [i[0] for i in temp_list]
df["cate"] = pd.DataFrame(np.array(cate_list).reshape((df.shape[0],1)))
4、数据合并Join和Merge
Join :默认情况下它是把行索引相同的数据合并在一起
print '使用默认的左连接\r\n',data.join(data1) #这里可以看出自动屏蔽了data中没有的index=e 那一行的数据
print '使用右连接\r\n',data.join(data1,how="right") #这里出自动屏蔽了data1中没有index=c,d的那行数据;等价于data1.join(data)
print '使用内连接\r\n',data.join(data1,how='inner')
print '使用全外连接\r\n',data.join(data1,how='outer') Merge:按照指定的列把数据按照一定方式合并在一起
print "单个列名做为内链接的连接键\r\n",merge(data,data1,on="name",suffixes=('_a','_b'))
print "多列名做为内链接的连接键\r\n",merge(data,data2,on=("name","id"))
print '不指定on则以两个DataFrame的列名交集做为连接键\r\n',merge(data,data2) #这里使用了id与name #使用右边的DataFrame的行索引做为连接键
##设置行索引名称
indexed_data1=data1.set_index("name")
print "使用右边的DataFrame的行索引做为连接键\r\n",merge(data,indexed_data1,left_on='name',right_index=True)
print '左外连接\r\n',merge(data,data1,on="name",how="left",suffixes=('_a','_b'))
print '左外连接1\r\n',merge(data1,data,on="name",how="left")
print '右外连接\r\n',merge(data,data1,on="name",how="right")
data3=DataFrame([{"mid":0,"mname":'lxh','cs':10},{"mid":101,"mname":'xiao','cs':40},{"mid":102,"mname":'hua2','cs':50}]) #当左右两个DataFrame的列名不同,当又想做为连接键时可以使用left_on与right_on来指定连接键
print "使用left_on与right_on来指定列名字不同的连接键\r\n",merge(data,data3,left_on=["name","id"],right_on=["mname","mid"])
example :
# coding=utf-8
import numpy as np
import pandas as pd def merge():
"""
merge使用
:return:
"""
data1 = pd.DataFrame(np.arange(24).reshape(4,6),columns=list("abcdef"))
data2 = pd.DataFrame(np.arange(24).reshape(4,6),columns=list("avwxyz"))
data1.iloc[2,0] = 100
print(data1)
print(data2) #inner连接 ,选取两边都存在的值,即取交集
print(pd.merge(data1,data2,on=["a","a"])) # 右连接,以data2为主表,如果data1表中没有data2对应的数据,则置为NaN
print(pd.merge(data1,data2,on=["a","a"],how="right")) data1 = pd.DataFrame(np.arange(24).reshape(4,6),columns=list("abcdef"))
data2 = pd.DataFrame(np.arange(24).reshape(4,6),columns=list("qvwxyz"))
data1.iloc[2,0] = 100
print(data1)
print(data2) #如果两个表的列名称不对应,则使用left_on 与right_on一起使用,两个必须一起使用,反之,如果列名对应,则使用on
print(pd.merge(data1,data2,left_on=["a"],right_on=["q"])) #左表以"a"作为连接主键,右表以"q"连接 return None def join():
"""
join使用:行合并
如果存在相同的列名,则不能使用,只能使用merge
:return:
"""
data1 = pd.DataFrame(np.arange(24).reshape(4, 6), columns=list("abcdef"))
data2 = pd.DataFrame(np.arange(12).reshape(3, 4), columns=list("wxyz"))
data1.iloc[3,0]=100
print(data1)
print(data2)
print(data1.join(data2)) #直接将两个数据进行行添加
print(data1.join(data2,how="right")) #以右表为主连接表
print(data1.join(data2, how="left")) #以左表为主连接表
return None def concat():
"""
concat使用:全连接方式
:return:
"""
data1 = pd.DataFrame(np.arange(24).reshape(4, 6), columns=list("abcdef"))
data2 = pd.DataFrame(np.arange(12).reshape(3, 4), columns=list("wxyz"))
data1.iloc[3, 0] = 100
print(data1)
print(data2)
frame = [data1,data2]
print(pd.concat(frame)) #全连接 print(pd.concat(frame,keys=["h","i"])) #指定行索引 return None if __name__ == '__main__':
#merge()
#join()
concat()
5、分组与聚合
grouped = df.groupby(by="columns_name")
grouped是一个DataFrameGroupBy对象,是可迭代的
grouped中的每一个元素是一个元组,元组里面是(索引(分组的值),分组之后的DataFrame)
获取分组之后的某一部分数据:
df.groupby(by=["Country","State/Province"])["Country"].count()
对某几列数据进行分组:
df["Country"].groupby(by=[df["Country"],df["State/Province"]]).count()
分组方式(t1,t2结果一样):
t1 = df[["Country"]].groupby(by=[df["Country"],df["State/Province"]]).count()
t2 = df.groupby(by=["Country","State/Province"])[["Country"]].count()
DataFrameGroupBy对象方法:

6、索引与复合索引
a)简单的索引操作:
获取index:df.index
指定index :df.index = ['x','y']
重新设置index : df.reindex(list("abcedf"))
指定某一列作为index :df.set_index("Country",drop=False)
返回index的唯一值:df.set_index("Country").index.unique() b)Series复合索引

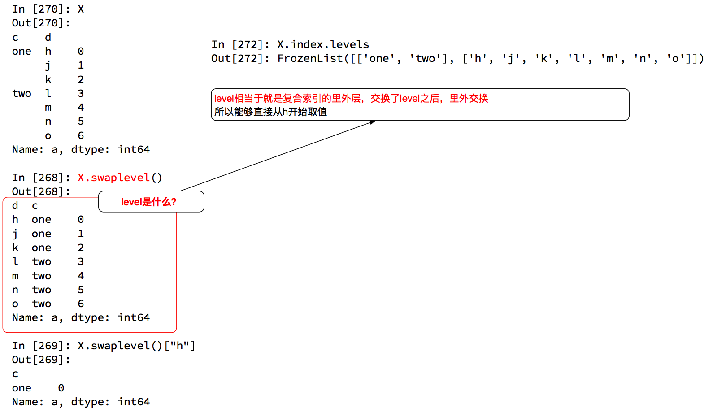
c)DataFrame复合索引

pandas之数据处理操作的更多相关文章
- pandas | 使用pandas进行数据处理——DataFrame篇
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是pandas数据处理专题的第二篇文章,我们一起来聊聊pandas当中最重要的数据结构--DataFrame. 上一篇文章当中我们介绍了 ...
- pandas的apply操作
pandas的apply操作类似于Scala的udf一样方便,假设存在如下dataframe: id_part pred pred_class v_id 0 d [0.722817, 0.650064 ...
- Pandas缺失数据处理
Pandas缺失数据处理 Pandas用np.nan代表缺失数据 reindex() 可以修改 索引,会返回一个数据的副本: df1 = df.reindex(index=dates[0:4], co ...
- Pandas的基础操作(一)——矩阵表的创建及其属性
Pandas的基础操作(一)——矩阵表的创建及其属性 (注:记得在文件开头导入import numpy as np以及import pandas as pd) import pandas as pd ...
- python数据结构:pandas(2)数据操作
一.Pandas的数据操作 0.DataFrame的数据结构 1.Series索引操作 (0)Series class Series(base.IndexOpsMixin, generic.NDFra ...
- Pandas的拼接操作
pandas的拼接操作 pandas的拼接分为两种: 级联:pd.concat, pd.append 合并:pd.merge, pd.join import pandas as pd import n ...
- (四)pandas的拼接操作
pandas的拼接操作 #重点 pandas的拼接分为两种: 级联:pd.concat, pd.append 合并:pd.merge, pd.join 0. 回顾numpy的级联 import num ...
- 数据分析05 /pandas的高级操作
数据分析05 /pandas的高级操作 目录 数据分析05 /pandas的高级操作 1. 替换操作 2. 映射操作 3. 运算工具 4. 映射索引 / 更改之前索引 5. 排序实现的随机抽样/打乱表 ...
- pandas 写csv 操作
pandas 写csv 操作 def show_history(self): df = pd.DataFrame() df['Time'] = pd.Series(self.time_hist) df ...
随机推荐
- 06-【servletconfig、servletContext 】
ServletConfig.ServletContext 1.ServletConfig获取web.xml中的配置信息:java代码: @Override public void init(Servl ...
- 转载 如何使用批处理 动态改变path实现改变JDK版本
http://www.cnblogs.com/xdp-gacl/p/5209386.html 1 @echo off 2 3 rem --- Base Config 配置JDK的安装目录 --- 4 ...
- 基础简单DP
状态比较容易表示,转移方程比较好想,问题比较基本常见 递推.背包.LIS(最长递增序列),LCS(最长公共子序列) HDU 2048 数塔 由上往下推 状态数太多(100!) 可以由下往上推: d ...
- 关于first-class object的解释
关于first-class object的解释 定义,什么是编程语言的第一等公民? In computer science, a programming language is said to hav ...
- 【线段树哈希】「Balkan OI 2016」Haker
1A海星 题目大意 给你一个长度为 $n$ ,由小写字母构成的字符串 $S$ 和 $Q$ 个操作,每个操作是以下 3 种之一: 1 x y k :询问当前字符串从位置 $x$ 到 $y$ 的子串与从位 ...
- css实现单行、多行文本超出显示省略号
前言:项目中我们经常遇到这种需求,需要对单行.多行文本超出显示为省略号.这篇文章主要总结了小编解决此问题的方法,有不足之处欢迎大家指正. 单行文本省略 .ellipsis-line { border: ...
- 路由传参 -vue
参数接收 param参数 => /: => 接收参数:this.$route.params.id query参数 => ? => 接收参数:this.$route.que ...
- Linux根目录下各目录文件类型及各项缩写全称
bin(binary) :常见linux命令.系统所有用户命令目录文件dev(device) : 设备驱动存储目录文件media: 多媒体及挂载目录proc (process):进程信息文件sbin( ...
- php类知识---命名空间
<?php #命名空间namespace用来解决类的命名冲突,和引用问题 namespace trainingplan1; class mycoach { public function tra ...
- nginx静态资源服务
静态文件 动态文件 需要算法,函数封装后,返回给浏览器端的 静态资源的服务场景----CDN 异步I/O-----效果不明显 tcp_nopush 注意,须在sendfile开启的前提下 技术思想: ...