[转帖]【ZOOKEEPER系列】Paxos、Raft、ZAB
【ZOOKEEPER系列】Paxos、Raft、ZAB
ZOOKEEPER系列
Paxos、Raft、ZAB
- Paxos算法
莱斯利·兰伯特(Leslie Lamport)这位大牛在1990年提出的一种基于消息传递且具有高度容错特性的一致性算法。如果你不知道这个人,那么如果你发表过Paper,就一定用过Latex,也是这位大牛的创作,
具体背景直接维基百科就可以,不深入讲解,直接讲Paxos算法。
分布式系统对fault tolorence 的一般解决方案是state machine replication。准确的描述Paxos应该是state machine replication的共识(consensus)算法。
Leslie Lamport写过一篇Paxos made simple的paper,没有一个公式,没有一个证明,这篇文章显然要比Leslie Lamport之前的关于Paxos的论文更加容易理解,但是,这篇文章是助于理解的,只到理解这一个层面是不够的。
在Leslie Lamport 的论文中,主要讲了三个Paxos算法
1. Basic Paxos
2. Multi Paxos
3. Fast Paxos
那么我们应该先从Basic Paxos学起
在Basic paxos算法中,分为4种角色:
Client: 系统外部角色,产生议题者,像民众
Proposer :接收议题请求,像集群提出议题(propose),并在冲突发生时,起到冲突调节的作用,像议员
Acceptor:提议的投票者和决策者,只有在形成法定人数(一般是majority多数派)时,提议才会被最终接受,像国会
Learner:最终提议的接收者,backup,对集群的已执行没有什么影响,像记录员

- 客户端给出一个提议,Proposer接收
- Proposer提交法案给Acceptor
- Acceptor把结果给Proposer,
- Proposer告诉Acceptor 议题已经被全部通过了,请求通过
- Acceptor 通过议题告诉Acceptor 和Learner,议题通过
- Learner返回给客户端,你的议题被通过了
这是一个正常的通过的情况

- 客户端给出一个提议,Proposer接收
- Proposer提交法案给Acceptor
- Acceptor把结果给Proposer,其中有一个Acceptor没有通过
- Proposer告诉Acceptor 议题已经被大多数通过了,请求通过
- Acceptor 通过议题告诉Acceptor 和Learner,议题通过
- Learner返回给客户端,你的议题被通过了

- 客户端给出一个提议,Proposer接收
- Proposer提交法案给Acceptor
- Acceptor把结果给Proposer,全部通过
- Proposer节点挂掉了,这个时候议案不会被通过
- 选举新的Proposer(leader)
- 新的Proposer提交2号法案给Acceptor
- Acceptor把结果给Proposer,全部通过
- Acceptor 通过议题告诉Acceptor 和Learner,议题通过
- Learner返回给客户端,你的议题被通过了
潜在问题
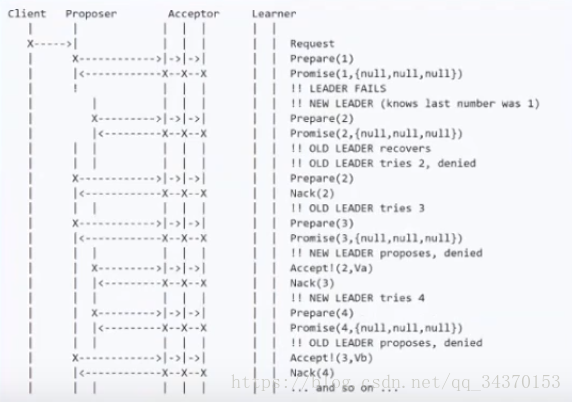
就是在新旧的leader在争抢通过法案,旧的leader法案被pass后,新的leader法案在提交,准备阶段,这个时候旧的leader发现自己的法案被pass了,然后提出一个新的法案,序号加1,Acceptor看到这个法案是最新的,那新的leader发来的法案就被pass掉了,来看旧的leader发来的法案,这个时候新的leader发现自己的法案被pass了,也回在序号上加1,然后提交申请,Acceptor看到新的leader才是最新的法案,把旧的leader法案pass了,这个时候就会发生活锁现象,实际上都是一个法案,但是最后导致机器无线循环
Basic Paxos问题
难实现,效率低(两轮RPC)、活锁
- Multi Paxos
新概念,Leader:唯一的proposer,所有的请求都需要经过此Leader
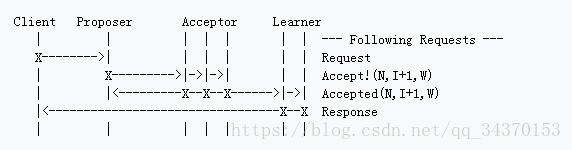
首先先做一下Proposer的Leader选举
Proposer提出的议案,所有的Acceptor需要通过
这个时候就有些像我们所说的一些模式了
Multi Paxos 还做了一个简化操作 如下图

首先servers先竞选leader,2.3步骤,选举好leader,选举好leader后,leader的每一个法案或者议题,都要被通过,然后返回给Client更像我们现实当中的流程了
raft 简化版的Multi Paxos
划分了三个子问题- Leader Electtion
- Log Replication
- Safety
重定义了三个角色
- eader
- Fllower
- Candidate
这个解释的非常明白
原理动画解释:https://http://thesecretlivesofdata.com/raft/
这个是怎样选举的leader,某个节点宕机了怎么解决的详细动画演示
场景测试:http://raft.github.io
Candidate是一个中间状态,Candidate的状态才能够竞选Leader
机器之间与leader之间发送心跳,其中心跳包里可以夹杂着具体的业务数据,每个节点都有自己的超时的时间,每次心跳发送过来了,超时的时钟会重新刷新加载重新走超时,如果真正的超时了那么,就会重新竞选Leader
如果出现网络分区的话怎么办?
一般来说,分布式的机器都是奇数的,那么出现脑裂,一定会有多于一般的机器和少于一半的机器,Raft执行Accept的时候,在大多数机器,也就是半数以上机器通过后,才会执行通过,那么就会出现,两个小集群都会接收到propose,但是数量少的集群没有大多数通过,也就不会执行Accept,数量多的集群会执行Accept,所以不会出现重复执行的脑裂问题。
一致性并不能代表一定是正确的
三个可能的结果:
- 成功
- 失败
- unknown
Client 向Server 发送请求 Leader 向Follower 发送同步日志,此时集群中有三个节点失败,2个节点存活,那么应该是什么样的情况?
会写入记录,但是不会提交执行,因为5个机器,最少三个是多数情况,现在只有两个几点存活,那么不会执行Accept操作
如果集群中的leader发送follower请求,共5台机器,3台宕机,这个时候不是多数派的情况,不会执行请求,但是会记录请求,这个时候leader挂掉,启动其他3台已经宕机的follower,这时,会重新选举leader,然后新的leader会发送新的请求给follower,此时,大多数机器同意,事务被执行,但是上一个leader发送的请求会被覆盖掉,这个时候事务发生丢失现象,所以Raft会存在这样的问题,但是整个系统的一致性和共识是没有问题的。
- ZAB算法
基本与Raft相同,在一些名词叫起来是有区别的
ZAB将Leader的一个生命周期叫做epoch,而Raft称之为term
实现上也有些许不同,如raft保证日志的连续性,心跳是Leader向Follower发送,而ZAB方向与之相反
暂时先讲这么多吧,有时间再进行补充
[转帖]【ZOOKEEPER系列】Paxos、Raft、ZAB的更多相关文章
- Paxos、ZAB、RAFT协议
这三个都是分布式一致性协议,ZAB基于Paxos修改后用于ZOOKEEPER协议,RAFT协议出现在ZAB协议之后,与ZAB差不多,也有很大区别. 1. Paxos 分布式节点分为3种角色, Prop ...
- 【分布式】Zookeeper与Paxos
一.前言 在学习了Paxos在Chubby中的应用后,接下来学习Paxos在开源软件Zookeeper中的应用. 二.Zookeeper Zookeeper是一个开源的分布式协调服务,其设计目标是将那 ...
- 从Paxos到ZooKeeper-二、ZooKeeper和Paxos
ZooKeeper为分布式应用提供了高效且可靠的分布式协调服务,提供了诸如tong'yi统一命名服务.配置管理和分布式锁等分布式的基础服务.在解决分布式数据一致性方面,ZooKeeper并没有直接采用 ...
- 【Zookeeper系列】ZooKeeper一致性原理(转)
原文链接:https://www.cnblogs.com/sunddenly/p/4138580.html 一.ZooKeeper 的实现 1.1 ZooKeeper处理单点故障 我们知道可以通过Zo ...
- 【Zookeeper系列】ZooKeeper管理分布式环境中的数据(转)
原文地址:https://www.cnblogs.com/sunddenly/p/4092654.html 引言 本节本来是要介绍ZooKeeper的实现原理,但是ZooKeeper的原理比较复杂,它 ...
- ZooKeeper系列(7):ZooKeeper一致性原理
一.ZooKeeper 的实现 1.1 ZooKeeper处理单点故障 我们知道可以通过ZooKeeper对分布式系统进行Master选举,来解决分布式系统的单点故障,如图所示. 图 1.1 ZooK ...
- ZooKeeper系列(5):管理分布式环境中的数据
引言 本节本来是要介绍ZooKeeper的实现原理,但是ZooKeeper的原理比较复杂,它涉及到了paxos算法.Zab协议.通信协议等相关知 识,理解起来比较抽象所以还需要借助一些应用场景,来帮我 ...
- Zookeeper一致性协议原理Zab
ZooKeeper为高可用的一致性协调框架,自然的ZooKeeper也有着一致性算法的实现,ZooKeeper使用的是ZAB协议作为数据一致性的算法, ZAB(ZooKeeper Atomic Bro ...
- Zookeeper 系列(一)基本概念
Zookeeper 系列(一)基本概念 https://www.cnblogs.com/wuxl360/p/5817471.html 一.分布式协调技术 在给大家介绍 ZooKeeper 之前先来给大 ...
随机推荐
- rundeck配置salt-api
Rundeck 安装: 系统: # cat /etc/issue CentOS release 6.7 (Final) 内核: # uname -r -.el6.x86_64 IP 地址: 172.1 ...
- [RN] React Native 使用精美图标库react-native-vector-icons
React Native 使用精美图标库react-native-vector-icons 一.安装依赖 npm install --save react-native-vector-icons // ...
- [Cqoi2016]K远点对 K-Dtree
4520: [Cqoi2016]K远点对 链接 bzoj 思路 用K-Dtree求点的最远距离. 求的时候顺便维护一个大小为2k的小根堆. 不知道为啥一定会对. 代码 #include <bit ...
- 中国大学生计算机系统与程序设计竞赛 CCF-CCSP-2016 选座( ticket_chooser )
选座( ticket_chooser ) 不会正解,欢迎讨论 //60分 #include<cstdio> #define max(a,b) (a)>(b)?a:b #define ...
- luoguP1118 [USACO06FEB]数字三角形`Backward Digit Su`… 题解
一上午都在做有关搜索的题目,,, 看到这题之后就直接开始爆搜 结果只有70分, 其余的点硬生生的就是那么WA了. 我的天哪~ 70分代码: #include<iostream> #incl ...
- Linux下的零拷贝
Reference: https://segmentfault.com/a/1190000011989008 零拷贝是什么? 维基百科对“零拷贝”是这样描述的: "Zero-copy&qu ...
- 关于finalize()
finalize()是Object中的方法,当垃圾回收器将要回收对象所占内存之前被调用,即当一个对象被虚拟机宣告死亡时会先调用它finalize()方法,让此对象处理它生前的最后事情(这个对象可以趁这 ...
- 如何实现大麦场在线选座 svg js
本实例来源于此网站,内有Demo,可查看 <!DOCTYPE html> <html lang="en"> <head> <meta ch ...
- webgestalt 通路富集分析
http://www.webgestalt.org/ 通路富集分析 参考 http://www.sci666.com.cn/9596.html
- proxmox之cloud-init
Cloud-Init支持 Cloud-Init是事实上的多分发包,它处理虚拟机实例的早期初始化.使用Cloud-Init,可以在虚拟机管理程序端配置网络设备和ssh密钥.当VM首次启动时,VM内的Cl ...