Oracle Spatial分区应用研究之二:按县分区与按省分区对比测试报告
1、实验目的
在上一轮的实验中,oracle 11g r2版本下,在87县市实验数据的基础上,比较了分表与分区的效率,得出了分区+全局索引效率较高的结论(见上一篇博客)。不过我们尚未比较过不同的分区粒度有什么效率差异。这一轮的实验,着重于以下几个目的:
- 使实验场景更接近真实使用场景——使用oracle 12c,用更大的数据量进行实验。
- 对比分析按县分区与按省分区的查询效率。
- 继续比较本地空间索引与全局空间索引在不同算法下的查询效率。
2、实验数据
实验数据为全国2531个区县,要素总数为46982394。根据不同的数据组织+索引形式,形成了3个不同的实验主体:
- 按县分区+本地空间索引
- 按县分区+全局空间索引
- 按省分区+本地空间索引
3、实验方法
在1:500、1:2000、1:10000、1:25000、1:50000、1:100000比例尺下,随机从全国范围内选择3个样本范围,作为空间查询时的查询范围。将6*3个样本范围分别与3个实验主体进行空间查询运算,记录每次查询的耗时。
空间查询所用的算法仍然同于上一篇博客《Oracle Spatial分区应用研究之一:分表与分区性能对比》中介绍的、适用于分区的3种算法,即part_query、part_query2、part_query3。同时,本次实验中,还将通过并行框架对3种算法进行衍生,得到另外3种算法,标记为part_query_p、part_query2_p、part_query3_p。
因此,对每一个实验主体来说,在每一种比例尺样本下均需要用6种算法来进行查询运算。另外,因为算法执行有先后顺序,后执行的算法由于缓存的原因,会比先执行的算法有优势。为了尽量避免这种干扰,会将算法以不同的执行顺序进行两组实验。
4、实验结果
4.1 第一组实验结果
第一组实验,其算法执行顺序为:
Part_query→Part_query2→Part_query3→Part_query_p→Part_query2_p→Part_query3_p
执行结果如下图:
说明:表中蓝色区域为按县分区+本地空间索引在不同比例尺、不同算法下的查询效率;同理,红色区域代表按县分区+全局空间索引,绿色区域代表按省分区+本地空间索引。黄色斑块表示该行的最小值。

根据黄色斑块坐落的位置,可知:
- 在所有比例尺下,按省分区+本地空间索引效率最高,所有耗时最小的查询均发生在该区域。
- Part_query_p算法的查询效率最高,18个实验样本,耗时最小命中17次。
4.2 第二组实验结果
第二组实验,其算法执行顺序为:
Part_query_p→Part_query2_p→Part_query3_p→Part_query→Part_query2→Part_query3
执行结果如下图:

根据黄色斑块坐落的位置,可知:
- 在所有比例尺下,按省分区+本地空间索引效率最高,所有耗时最小的查询均发生在该区域。
- Part_query算法的查询效率最高,18个实验样本,耗时最小命中18次。
4.3 补充说明
两种实验,分别得出Part_query_p与Part_query算法效率最高的结论。这看似矛盾,实际上正是上文提到的,当算法执行有先后顺序时,会受到缓存的原因。那么对于Part_query_p与Part_query,谁的效率更高呢?
在两组实验中,Part_query_p与Part_query分别是最先执行的算法。分别从两组实验结果中取出Part_query_p与Part_query的实验数据,就可几乎完全排除缓存的影响。
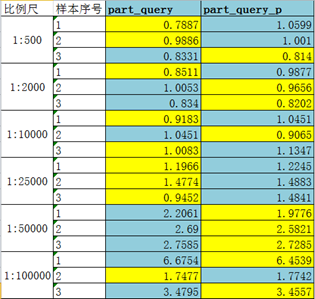
两种算法,各命中9次。说明效率相当。但很明显的是,part_query在大比例尺下(大于1:25000)命中率较高;part_query_p在小比例尺下命中率较高。这与我们的认知一致,即在大任务作业时,并行才会体现优势。
5、实验结论
- Oracle 12c环境下,在要素量为四千万级别时,按省分区+本地空间索引效率较高。
- 采用按省分区+本地空间数据组织方式时,Part_query算法较为高效。
(未完待续)
Oracle Spatial分区应用研究之二:按县分区与按省分区对比测试报告的更多相关文章
- Oracle Spatial分区应用研究之七:同等分区粒度下全局索引优于分区索引的原因分析
1.实验结论 同等分区粒度下,使用分区空间索引进行空间查询,比使用全局空间索引进行查询,对数据字典表的访问次数更多.假设分区数为X,则大概多3X次访问.具体说明见6实验结论. 2.实验目的 在之前的测 ...
- Oracle Spatial分区应用研究之六:全局空间索引下按县分区与按省分区效率差异原因分析
1.实验结论 全局空间索引下,不同分区粒度之所有效率会有不同,差异并不在于SDO_FILTER操作本身,而在于对于数据字典表的访问次数上: 分区越多.表上的lob column越多,对数据字典表的访问 ...
- Oracle Spatial分区应用研究之三:县市省不同分区粒度的效率比较
在<Oracle Spatial分区应用研究之一:分区与分表查询性能对比>中已经说明:按县分区+全局空间索引效率要优于按县分区+本地空间索引,因此在该实验报告中,将不再考虑按县分区+本地空 ...
- Oracle Spatial分区应用研究之五:不同分区粒度+本地空间索引效率对比
1.实验目的 若使用本地空间索引,不同分区粒度将产生不同索引组织,其索引分区个数.大小.R-TREE树结构均不相同.那么,在什么分区粒度下的本地空间索引效率较高呢? 2实验数据 实验数据为全国2531 ...
- Oracle Spatial中的空间索引
转自cryolite原文 Oracle Spatial中的空间索引 Oracle Spatial可对空间数据进行R-tree索引,每个空间图层(Spatial Layer)的空间索引元信息都可以在US ...
- Oracle Spatial 中的弧段及弧相关拓扑错误
1.报告说明 此报告用于验证下列问题: ORACLE SPATIAL 0.05m的最小拓扑容差值是否可以被修改 原始数据通过ARCGIS入库数据精度是否有损失 修改ORACLE SPATIAL图层的最 ...
- Oracle Spatial中SDO_Geometry详细说明[转]
在ArcGIS中通过SDE存储空间数据到Oracle中有多种存储方式,分别有:二进制Long Raw .ESRI的ST_Geometry以及基于Oracle Spatial的SDO_Geometry等 ...
- 细说Oracle数据库与操作系统存储管理二三事
在上大学的时候,学习操作系统感觉特别枯燥,都是些条条框框的知识点,感觉和实际应用的关联不大.发现越是工作以后,在工作中越想深入了解,发现操作系统知识越发重要.在实践中结合理论还是不错的一种学习方法.自 ...
- Oracle数据库基础入门《二》Oracle内存结构
Oracle数据库基础入门<二>Oracle内存结构 Oracle 的内存由系统全局区(System Global Area,简称 SGA)和程序全局区(Program Global Ar ...
随机推荐
- debug版本的DLL调用release版本的DLL引发的一个问题
stl的常用结构有 vector.list.map等. 今天碰到需要在不同dll间传递这些类型的参数,以void*作为转换参数. 比如 DLL2 的接口 add(void*pVoid); 1.在DLL ...
- 通过ip找mac
# coding:utf-8 import os cmd = {'arp': 'arp -a | find "', 'route': 'route PRINT ' } def win_mac ...
- JavaScript Array 對象
JavaScript array 對象 array對象,是用於在單個變量中存儲多個值的一種變量類型. 創建array對象的語法: new array(); new array(size); new a ...
- windows串口编程Win32,PComm串口开发
https://blog.csdn.net/u011430225/article/details/51496456 https://blog.csdn.net/eit520/article/detai ...
- 虚拟机Linux系统ip查询失败问题
当用SSH连接Linux需要ip地址,但是不论是通过ipconfig命令,还是通过ip addr命令都无法获取Linux的ip,通过以下方法成功解决了该问题: 1.点击编辑里面的虚拟网络编辑器出现如下 ...
- High scalability with Fanout and Fastly
转自:http://blog.fanout.io/2017/11/15/high-scalability-fanout-fastly/ Fanout Cloud is for high scale d ...
- NOI 2019 游记
day -1 去报了个到,顺便买了一大堆衣服. 感觉学校饭堂不太行. day 0 上午是开幕式,. 下午是笔试,顺利获得 \(100\) 分. day 1 先看题. 第一题看到 \(At^2+Bt+C ...
- 框架 get 请求乱码
解决方案: 在 tomcat 配置文件中添加 URIEncoding="utf-8"
- vue Uncaught SyntaxError: Unexpected token < 报错
这个问题是因为项目中出现没有闭合的标签,如<img src=""> 需改成<img src="xxx.png"/>
- 欢迎来到地狱 WriteUp(2019暑假CTF第一周misc)
目录 0707,0708,0709 题目地址:欢迎来到地狱 1.地狱伊始.jpg 1.5地狱之声.wav 2.第二层地狱.docx 3.快到终点了.zip 参考 0707,0708,0709 题目地址 ...