Kafka ISR and AR HW 、 LEO
相信大家已经对 kafka 的基本概念已经有一定的了解了,下面直接来分析一下 ISR 和 AR 的概念。
0|1ISR and AR
简单来说,分区中的所有副本统称为 AR (Assigned Replicas)。所有与leader副本保持一定程度同步的副本(包括leader副本在内)组成 ISR (In Sync Replicas)。 ISR 集合是 AR 集合的一个子集。消息会先发送到leader副本,然后follower副本才能从leader中拉取消息进行同步。同步期间,follow副本相对于leader副本而言会有一定程度的滞后。前面所说的 ”一定程度同步“ 是指可忍受的滞后范围,这个范围可以通过参数进行配置。于leader副本同步滞后过多的副本(不包括leader副本)将组成 OSR (Out-of-Sync Replied)由此可见,AR = ISR + OSR。正常情况下,所有的follower副本都应该与leader 副本保持 一定程度的同步,即AR=ISR,OSR集合为空。
0|1ISR 的伸缩性
leader副本负责维护和跟踪 ISR 集合中所有follower副本的滞后状态,当follower副本落后太多或失效时,leader副本会把它从 ISR 集合中剔除。如果 OSR 集合中所有follower副本“追上”了leader副本,那么leader副本会把它从 OSR 集合转移至 ISR 集合。默认情况下,当leader副本发生故障时,只有在 ISR 集合中的follower副本才有资格被选举为新的leader,而在 OSR 集合中的副本则没有任何机会(不过这个可以通过配置来改变)。
HW 、 LEO
HW 、 LEO 等概念和上一篇文章所说的 ISR有着紧密的关系,如果不了解 ISR 可以先看下ISR相关的介绍。
HW (High Watermark)俗称高水位,它标识了一个特定的消息偏移量(offset),消费者只能拉取到这个offset之前的消息。
下图表示一个日志文件,这个日志文件中只有9条消息,第一条消息的offset(LogStartOffset)为0,最有一条消息的offset为8,offset为9的消息使用虚线表示的,代表下一条待写入的消息。日志文件的 HW 为6,表示消费者只能拉取offset在 0 到 5 之间的消息,offset为6的消息对消费者而言是不可见的。

LEO (Log End Offset),标识当前日志文件中下一条待写入的消息的offset。上图中offset为9的位置即为当前日志文件的 LEO,LEO 的大小相当于当前日志分区中最后一条消息的offset值加1.分区 ISR 集合中的每个副本都会维护自身的 LEO ,而 ISR 集合中最小的 LEO 即为分区的 HW,对消费者而言只能消费 HW 之前的消息。
下面具体分析一下 ISR 集合和 HW、LEO的关系。
假设某分区的 ISR 集合中有 3 个副本,即一个 leader 副本和 2 个 follower 副本,此时分区的 LEO 和 HW 都分别为 3 。消息3和消息4从生产者出发之后先被存入leader副本。
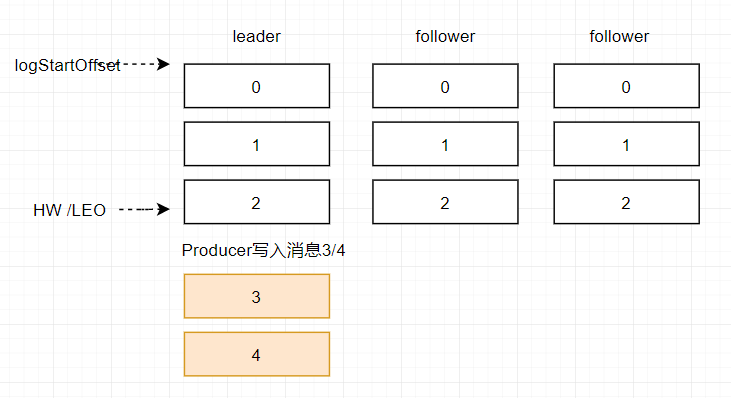
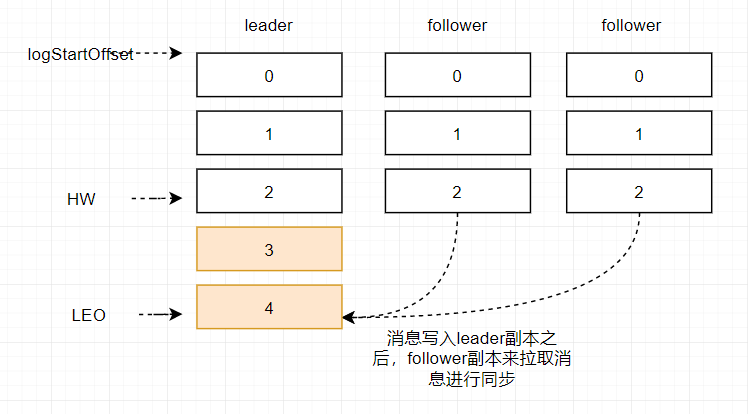
在消息被写入leader副本之后,follower副本会发送拉取请求来拉取消息3和消息4进行消息同步。
在同步过程中不同的副本同步的效率不尽相同,在某一时刻follower1完全跟上了leader副本而follower2只同步了消息3,如此leader副本的LEO为5,follower1的LEO为5,follower2的LEO 为4,那么当前分区的HW取最小值4,此时消费者可以消费到offset0至3之间的消息。
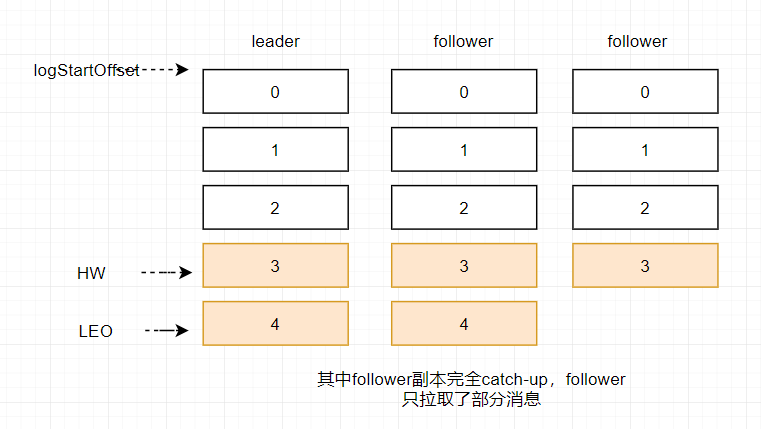
当所有副本都成功写入消息3和消息4之后,整个分区的HW和LEO都变为5,因此消费者可以消费到offset为4的消息了。
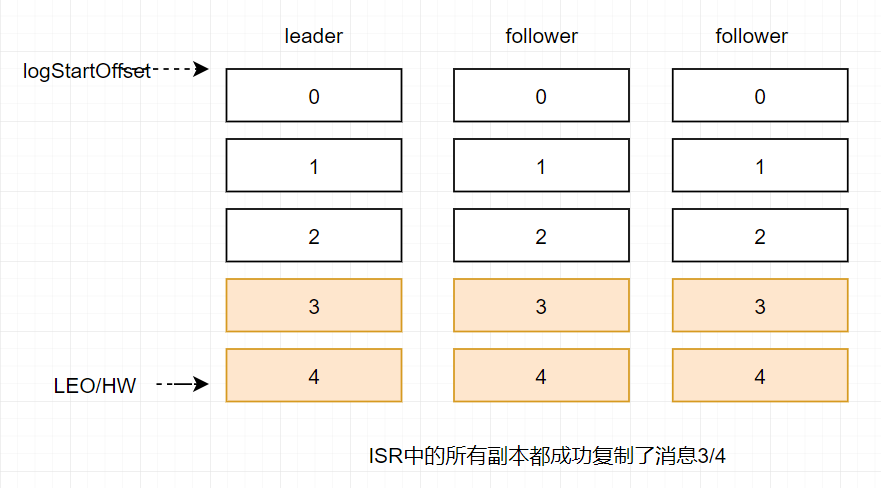
由此可见kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制。事实上,同步复制要求所有能工作的follower副本都复制完,这条消息才会被确认已成功提交,这种复制方式极大的影响了性能。而在异步复制的方式下,follower副本异步的从leader副本中复制数据,数据只要被leader副本写入就会被认为已经成功提交。在这种情况下,如果follower副本都还没有复制完而落后于leader副本,然后leader副本宕机,则会造成数据丢失。kafka使用这种ISR的方式有效的权衡了数据可靠性和性能之间的关系。
转载自:https://www.cnblogs.com/yoke/p/11486200.html
https://www.cnblogs.com/yoke/p/11486196.html
Kafka ISR and AR HW 、 LEO的更多相关文章
- Kafka中的HW、LEO、LSO等分别代表什么?
HW . LEO 等概念和上一篇文章所说的 ISR有着紧密的关系,如果不了解 ISR 可以先看下ISR相关的介绍. HW (High Watermark)俗称高水位,它标识了一个特定的消息偏移量(of ...
- Kafka集群安装部署、Kafka生产者、Kafka消费者
Storm上游数据源之Kakfa 目标: 理解Storm消费的数据来源.理解JMS规范.理解Kafka核心组件.掌握Kakfa生产者API.掌握Kafka消费者API.对流式计算的生态环境有深入的了解 ...
- 评分模型的检验方法和标准通常有:K-S指标、交换曲线、AR值、Gini数等。例如,K-S指标是用来衡量验证结果是否优于期望值,具体标准为:如果K-S大于40%,模型具有较好的预测功能,发展的模型具有成功的应用价值。K-S值越大,表示评分模型能够将“好客户”、“坏客户”区分开来的程度越大。
评分模型的检验方法和标准通常有:K-S指标.交换曲线.AR值.Gini数等.例如,K-S指标是用来衡量验证结果是否优于期望值,具体标准为:如果K-S大于40%,模型具有较好的预测功能,发展的模型具有成 ...
- 第1节 kafka消息队列:11、kafka的数据不丢失机制,以及kafka-manager监控工具的使用;12、课程总结
12.kafka如何保证数据的不丢失 12.1生产者如何保证数据的不丢失 kafka的ack机制:在kafka发送数据的时候,每次发送消息都会有一个确认反馈机制,确保消息正常的能够被收到 如果是同步模 ...
- 第1节 kafka消息队列:2、kafka的架构介绍以及基本组件模型介绍
3.kafka的架构模型 1.producer:消息的生产者,主要是用于生产消息的.主要是接入一些外部的数据源,从外部获取数据,比如说我们可以从flume获取数据,还可以通过ftp传入数据等,还可以通 ...
- 【原创】大数据基础之Kafka(1)简介、安装及使用
kafka2.0 http://kafka.apache.org 一 简介 Kafka® is used for building real-time data pipelines and strea ...
- Kafka主题体系架构-复制、故障转移和并行处理
本文讨论了Kafka主题的体系架构,讨论了如何将分区用于故障转移和并行处理. Kafka主题,日志和分区 Kafka将主题存储在日志中.主题日志分为多个分区.Kafka将日志的分区分布在多个服务器或磁 ...
- 第1节 kafka消息队列:3、4、kafka的安装以及命令行的管理使用
6.kafka的安装 5.1三台机器安装zookeeper 注意:安装zookeeper之前一定要确保三台机器时钟同步 */1 * * * * /usr/sbin/ntpdate us.pool.nt ...
- ASP.NET Aries JSAPI 文档说明:AR.Form、AR.Combobox
AR.Form 文档 1:对象或属性: 名称 类型 说明 data 属性 编辑页根据主键请求回来的数据 method 属性 用于获取数据的函数指向,默认值Get objName 属性 用于拦截form ...
随机推荐
- 12 IO流(九)——装饰流 BufferedInputStream/OutputStream
我们按功能可以将IO流分为节点流与处理流 节点流:可以直接从数据源或目的地读写数据 处理流(装饰流):不直接连接到数据源或目的地,是其他流(必须包含节点流)进行封装.目的主要是简化操作和提高性能. B ...
- mysql_select 多表查询
一.等值连接 原理:将多张单表组成一张逻辑大表 语法: select * from 表A,表B where 表A.主键=表B.外键 and 查询条件 select * from 表A,表B ...
- 3.NioEventLoop的启动和执行
NioEventLoop启动和执行 NioEventLoop启动 在服务端启动的代码中,我们看到netty在注册和绑定时,判断了当前线程是否是NioEventLoop线程.如果不是, 则将这些操作包装 ...
- LOJ2026 JLOI/SHOI2016 成绩比较 组合、容斥
传送门 感觉自己越来越愚钝了qwq 先考虑从\(n-1\)个人里安排恰好\(k\)个人被碾压,然后再考虑如何分配分数,两者乘起来得到答案. 对于第一部分,可以考虑容斥:设\(f_i\)表示\(i\)个 ...
- java8之lambda表达式(默认方法)
[推荐]2019 Java 开发者跳槽指南.pdf(吐血整理)>>> 许多开发语言都将函数表达式集成到了其集合库中.这样比循环方式所需的代码更少,并且更加容易理解.以下面的循环为例: ...
- JDBC使用8.0驱动包连接mysql设置时区serverTimezone
驱动包用的是新版 mysql-connector-java-8.0.16.jar新版的驱动类改成了com.mysql.cj.jdbc.Driver新版驱动连接url也有所改动I.指定时区 如果不设置时 ...
- Linux中su和sudo的用法整理
一.为什么会有su和sudo命令? 主要是因为在实际工作当中需要在Linux不同用户之间进行切换.root用户权限最高很多时候需要root用户才能执行一些关键命令.所以需要临时切换为root用户.工作 ...
- BUAAOO-Final-Summary
目录 总结本单元两次作业的架构设计 总结自己在四个单元中架构设计及OO方法理解的演进 总结自己在四个单元中测试理解与实践的演进 总结自己的课程收获 立足于自己的体会给课程提三个具体改进建议 两次架构设 ...
- thinkPHP5.0 使用PHPExcel导出Excel文件
首先下载PHPExcel类.网上很多,自行下载. 我下载的跟composer下载的不太一样.我下载的是 下载存放目录.jpg 而composer下载的是: composer下载.jpg 本篇使 ...
- ORACLE主键ID的生成
转自:https://blog.csdn.net/yh_zeng2/article/details/83477880 一般常用的方法有两种,使用Sequence和使用SYS_GUID(); 方法一 ...