14、master原理与源码分析
一、主备切换机制原理剖析
1、图解
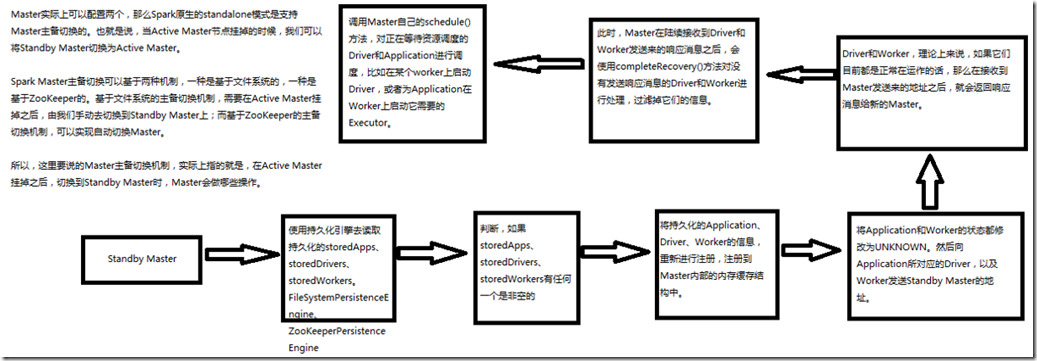
Master实际上可以配置两个,那么Spark原生的standalone模式是支持Master主备切换的。也就是说,当Active Master节点挂掉时,可以将StandBy master节点切换
为Active Master。
Spark Master主备切换可以基于两种机制,一种是基于文件系统的,一种是基于Zookeeper的。基于文件系统的主备切换机制,需要在Active Master挂掉之后,由我们
手动切换到StandBy Master上;而基于Zookeeper的主备切换机制,可以自动实现切换Master。
所以这里说的主备切换机制,实际上指的是在Active Master挂掉之后,切换到StandBy Master时,Master会执行的操作。
首先,StandBy Master会使用持久化引擎去读取持久化的storedApps,storedDrivers,storedWorkers。持久化引擎有两种:
FileSystemPersistenceEngine和ZookeeperPersistentEngine。读取出来后,会进行判断,如果storedApps,storedDrivers,storedWorkers有任何一个是非空的,
继续向下执行,去启动master恢复机制,将持久化的Application,Driver,Worker信息重新进行注册,注册到Master内部的缓存结构中。注册完之后,
将Application和Worker的状态修改为UNKNOWN,然后向Application所对应的Driver,以及Worker发送StandBy Master的地址。Driver和Worker,理论上来说,
如果它们目前都在正常运行的话,那么在接收到Master发送来的地址之后,就会返回相应消息给新的Master。此时,Master在陆续接收到Driver和Worker发送
来的响应消息后,会使用completeRecovery()方法对没有发送响应消息的Driver和Worker进行处理,过滤掉它们的信息。最后,调用Master自己的schedule()方法,
对正在等待资源调度的Driver和Application进行调度,比如在某个worker上启动Driver,或者为Application在Worker上启动它需要的Executor。
2、部分源码
###master.scala中的completeRecovery方法:
/*
* 完成Master的主备切换
*/
def completeRecovery() {
// Ensure "only-once" recovery semantics using a short synchronization period.
synchronized {
if (state != RecoveryState.RECOVERING) { return }
state = RecoveryState.COMPLETING_RECOVERY
}
/*
* 将Application和worker,过滤出来目前的状态还是UNKNOW的
* 然后遍历,分别调用removeWorker和finishApplication方法,
* 对可能已经出故障,或者甚至已经死掉的Application和Worker,进行清理
*/
// Kill off any workers and apps that didn't respond to us.
workers.filter(_.state == WorkerState.UNKNOWN).foreach(removeWorker)
apps.filter(_.state == ApplicationState.UNKNOWN).foreach(finishApplication)
// Reschedule drivers which were not claimed by any workers
drivers.filter(_.worker.isEmpty).foreach { d =>
logWarning(s"Driver ${d.id} was not found after master recovery")
if (d.desc.supervise) {
logWarning(s"Re-launching ${d.id}")
relaunchDriver(d)
} else {
removeDriver(d.id, DriverState.ERROR, None)
logWarning(s"Did not re-launch ${d.id} because it was not supervised")
}
}
state = RecoveryState.ALIVE
schedule()
logInfo("Recovery complete - resuming operations!")
}
二、注册机制原理剖析与源码分析
1、图解
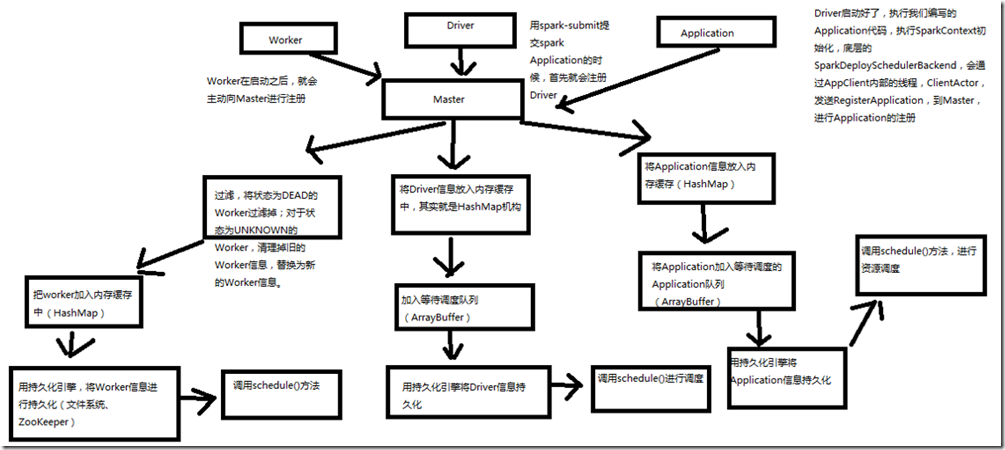
master 的注册流程:
1 worker.
当worker 启动之后,就会主动的向master 进行注册。 master接收到worker的注册请求之后,会将状态为DEAD的worker过滤掉。对于状态为UNKNOWN的worker 节点清理掉worker的信息替换为新的worker节点。 把worker 的注册信息写入到内存缓存中(hashmap) 用持久化引擎,将worker 信息进行持久化(文件系统,zookeeper) 调用schedule()方法; 2.Driver
用spark-submit 提交Application 首先会注册Driver 将Driver 信息写入到内存中 加入等待调度队列 用持久化引擎将driver信息写入到 文件系统/zookeeper 调用schedule()方法,进行资源调度; Driver 启动好了之后 执行编写的application代码 执行 Sparkcontext 初始化 底层的 SparkDeploySchedulerBackend 会通过ClientActor
发送RegisterApplication,到master进行Application 注册。 将Application 信息写入内存。 将application 写入对面。 调用持久化将application 写入到文件系统/zookeeper
2、master.scala中的Application注册原理代码分析
case RegisterApplication(description) => {
//如果master的状态是standby,就是当前的这个master,是standby master,
//而不是Active Master,那么,当Application来请求注册时,会忽略请求。
if (state == RecoveryState.STANDBY) {
// ignore, don't send response
} else {
logInfo("Registering app " + description.name)
//用ApplicationDescription信息,创建ApplicationInfo
val app = createApplication(description, sender)
//注册Application
//将Application加入缓存中,并将Application加入等待调度的队列中-waitingApps
registerApplication(app)
logInfo("Registered app " + description.name + " with ID " + app.id)
//使用持久化引擎,将Application进行持久化
persistenceEngine.addApplication(app)
//反向,向SparkDeploySchedulerBackend的APPClient的ClientActor,发送消息,也就是RegisterApplication
sender ! RegisteredApplication(app.id, masterUrl)
schedule()
}
三、状态改变机制源码分析
1、Driver状态改变
###Master.scala
case DriverStateChanged(driverId, state, exception) => {
state match {
// 如果Driver的状态是错误、完成、杀死、失败,就移除Driver
case DriverState.ERROR | DriverState.FINISHED | DriverState.KILLED | DriverState.FAILED =>
removeDriver(driverId, state, exception)
case _ =>
throw new Exception(s"Received unexpected state update for driver $driverId: $state")
}
// 删除driver
def removeDriver(driverId: String, finalState: DriverState, exception: Option[Exception]) {
//用Scala高阶函数find()根据driverId,查找到driver
drivers.find(d => d.id == driverId) match {
case Some(driver) =>
logInfo(s"Removing driver: $driverId")
//将driver将内存缓存中删除
drivers -= driver
if (completedDrivers.size >= RETAINED_DRIVERS) {
val toRemove = math.max(RETAINED_DRIVERS / 10, 1)
completedDrivers.trimStart(toRemove)
}
//将driver加入到已经完成的completeDrivers
completedDrivers += driver
//从持久化引擎中删除driver
persistenceEngine.removeDriver(driver)
//设置driver状态设置为完成
driver.state = finalState
driver.exception = exception
//从worker中遍历删除传入的driver
driver.worker.foreach(w => w.removeDriver(driver))
//重新调用schedule
schedule()
case None =>
logWarning(s"Asked to remove unknown driver: $driverId")
}
}
2、Executor状态改变
###org.apache.spark.deploy.master/Master.scala
case ExecutorStateChanged(appId, execId, state, message, exitStatus) => {
// 找到Executor对应的Application,然后再反过来通过Application内部的Executor缓存获取Executor信息
val execOption = idToApp.get(appId).flatMap(app => app.executors.get(execId))
execOption match {
case Some(exec) => {
// 如果有值
val appInfo = idToApp(appId)
exec.state = state
if (state == ExecutorState.RUNNING) { appInfo.resetRetryCount() }
// 向driver同步发送ExecutorUpdated消息
exec.application.driver ! ExecutorUpdated(execId, state, message, exitStatus)
// 判断,如果Executor完成了
if (ExecutorState.isFinished(state)) {
// Remove this executor from the worker and app
logInfo(s"Removing executor ${exec.fullId} because it is $state")
// 从Application缓存中移除Executor
appInfo.removeExecutor(exec)
// 从运行Executor的Worker的缓存中移除Executor
exec.worker.removeExecutor(exec)
// 判断 如果Executor的退出状态是非正常的
val normalExit = exitStatus == Some(0)
// Only retry certain number of times so we don't go into an infinite loop.
if (!normalExit) {
// 判断Application当前的重试次数,是否达到了最大值,最大值是10
// 也就是说,Executor反复调度都是失败,那么认为Application也失败了
if (appInfo.incrementRetryCount() < ApplicationState.MAX_NUM_RETRY) {
// 重新进行调度
schedule()
} else {
// 否则,进行移除Application操作
val execs = appInfo.executors.values
if (!execs.exists(_.state == ExecutorState.RUNNING)) {
logError(s"Application ${appInfo.desc.name} with ID ${appInfo.id} failed " +
s"${appInfo.retryCount} times; removing it")
removeApplication(appInfo, ApplicationState.FAILED)
}
}
}
}
}
case None =>
logWarning(s"Got status update for unknown executor $appId/$execId")
}
}
###removeApplication()方法:
def removeApplication(app: ApplicationInfo, state: ApplicationState.Value) {
if (apps.contains(app)) {
logInfo("Removing app " + app.id)
//从application队列(hashset)中删除当前application
apps -= app
idToApp -= app.id
actorToApp -= app.driver
addressToApp -= app.driver.path.address
if (completedApps.size >= RETAINED_APPLICATIONS) {
val toRemove = math.max(RETAINED_APPLICATIONS / 10, 1)
completedApps.take(toRemove).foreach( a => {
appIdToUI.remove(a.id).foreach { ui => webUi.detachSparkUI(ui) }
applicationMetricsSystem.removeSource(a.appSource)
})
completedApps.trimStart(toRemove)
}
//加入已完成的application队列
completedApps += app // Remember it in our history
//从当前等待运行的application队列中删除当前APP
waitingApps -= app
// If application events are logged, use them to rebuild the UI
rebuildSparkUI(app)
for (exec <- app.executors.values) {
//停止executor
exec.worker.removeExecutor(exec)
exec.worker.actor ! KillExecutor(masterUrl, exec.application.id, exec.id)
exec.state = ExecutorState.KILLED
}
app.markFinished(state)
if (state != ApplicationState.FINISHED) {
//从driver中删除application
app.driver ! ApplicationRemoved(state.toString)
}
//从持久化引擎中删除application
persistenceEngine.removeApplication(app)
//从新调度任务
schedule()
// Tell all workers that the application has finished, so they can clean up any app state.
//告诉所有的worker,APP已经启动完成了,所以他们可以清空APP state
workers.foreach { w =>
w.actor ! ApplicationFinished(app.id)
}
}
}
四、资源调度算法原理剖析与源码分析
1、剖析
首先判断,master状态不是ALIVE的话,直接返回,也就是说,standby master是不会进行Application等资源调度的; 首先调度Driver
只有用yarn-cluster模式提交的时候,才会注册driver,因为standalone和yarn-client模式,都会在本地直接启动driver,而不会来注册driver,就更不可能让master来调度driver了; Application的调度机制
首先,Application的调度算法有两种,一种是spreadOutApps,另一种是非spreadOutApps,默认是spreadOutApps; 通过spreadOutApps这种算法,其实会将每个Application,要启动的Executor,都平均分布到各个worker上去; 比如有20个cpu core要分配,有10个worker,那么实际上会循环两遍worker,每次循环,给每个worker分配一个core,最后每个worker分配了两个core; 所以,比如,spark-submit里,配置的是要10个executor,每个要2个core,那么总共是20个core,但这种算法下,其实总共只会启动2个executor,每个有10个core; 非spreadOutApps调度算法,将每一个application,尽可能少的分配到Worker上去,这种算法和spreadOutApps算法正好相反,每个application都尽可能分配到尽量
少的worker上去; 比如总共有10个worker,每个有10个core,Application总共要分配20个core,
那么其实只会分配到两个worker上,每个worker都占满10个core,那么其余的application,就只能分配到下一个worker了;
2、源码
###org.apache.spark.deploy.master/Master.scala
private def schedule() {
// 首先判断,master状态不是ALIVE的话,直接返回
// 也就是说,standby master是不会进行Application等资源调度的
if (state != RecoveryState.ALIVE) { return }
// First schedule drivers, they take strict precedence over applications
// Randomization helps balance drivers
// Random.shuffle的原理,就是对传入的集合的元素进行随机的打乱
// 取出了Workers中所有之前注册上来的worker,进行过滤,必须状态位ALIVE的worker
// 对状态为ALIVE的worker,调用Random.shuffle方法进行随机的打乱
val shuffledAliveWorkers = Random.shuffle(workers.toSeq.filter(_.state == WorkerState.ALIVE))
// 拿到worker数量
val numWorkersAlive = shuffledAliveWorkers.size
var curPos = 0
// 首先调度Driver
// 只有用yarn-cluster模式提交的时候,才会注册driver,因为standalone和yarn-client模式,都会在本地直接启动driver,而
// 不会来注册driver,就更不可能让master来调度driver了
// driver调度机制
// 遍历waitingDrivers ArrayBuffer
for (driver <- waitingDrivers.toList) { // iterate over a copy of waitingDrivers
// We assign workers to each waiting driver in a round-robin fashion. For each driver, we
// start from the last worker that was assigned a driver, and continue onwards until we have
// explored all alive workers.
var launched = false
var numWorkersVisited = 0
// while的条件 numWorkersVisited小于numWorkersAlive 只要还有活着的worker没有遍历到,就继续遍历
// 而且当前这个driver还没有被启动,也就是launched为false
while (numWorkersVisited < numWorkersAlive && !launched) {
val worker = shuffledAliveWorkers(curPos)
numWorkersVisited += 1
// 如果当前这个worker的空闲内存量大于等于driver需要的内存
// 并且worker的空闲cpu数量大于等于driver所需要的CPU数量
if (worker.memoryFree >= driver.desc.mem && worker.coresFree >= driver.desc.cores) {
// 启动driver
launchDriver(worker, driver)
// 将driver从waitingDrivers队列中移除
waitingDrivers -= driver
// launched设置为true
launched = true
}
// 将指针指向下一个worker
curPos = (curPos + 1) % numWorkersAlive
}
}
// Right now this is a very simple FIFO scheduler. We keep trying to fit in the first app
// in the queue, then the second app, etc.
// Application的调度机制
// 首先,Application的调度算法有两种,一种是spreadOutApps,另一种是非spreadOutApps
// 默认是spreadOutApps
if (spreadOutApps) {
// Try to spread out each app among all the nodes, until it has all its cores
// 首先,遍历waitingApps中的ApplicationInfo,并且过滤出Application还有需要调度的core的Application
for (app <- waitingApps if app.coresLeft > 0) {
// 从worker中过滤出状态为ALIVE的Worker
// 再次过滤出可以被Application使用的Worker,Worker剩余内存数量大于等于Application的每一个Actor需要的内存数量,而且该Worker没有运行过该Application对应的Executor
// 将Worker按照剩余cpu数量倒序排序
val usableWorkers = workers.toArray.filter(_.state == WorkerState.ALIVE)
.filter(canUse(app, _)).sortBy(_.coresFree).reverse
val numUsable = usableWorkers.length
// 创建一个空数组,存储要分配给每个worker的cpu数量
val assigned = new Array[Int](numUsable) // Number of cores to give on each node
// 获取到底要分配多少cpu,取app剩余要分配的cpu的数量和worker总共可用cpu数量的最小值
var toAssign = math.min(app.coresLeft, usableWorkers.map(_.coresFree).sum)
// 通过这种算法,其实会将每个Application,要启动的Executor,都平均分布到各个worker上去
// 比如有20个cpu core要分配,有10个worker,那么实际上会循环两遍worker,每次循环,给每个worker分配一个core,最后每个worker分配了两个core
// 所以,比如,spark-submit里,配置的是要10个executor,每个要2个core,那么总共是20个core,但这种算法下,其实总共只会启动2个executor,每个有10个core
// while条件,只要 要分配的cpu,还未分配完,就继续循环
var pos = 0
while (toAssign > 0) {
// 每一个Worker,如果空闲的cpu数量大于已经分配出去的cpu数量,也就是说worker还有可分配的cpu
if (usableWorkers(pos).coresFree - assigned(pos) > 0) {
// 将总共要分配的cpu数量-1,因为这里已经决定在这个worker上分配一个cpu了
toAssign -= 1
// 给这个worker分配的cpu数量,加1
assigned(pos) += 1
}
// 指针移动到下一个worker
pos = (pos + 1) % numUsable
}
// Now that we've decided how many cores to give on each node, let's actually give them
// 给每个worker分配完Application要求的cpu core之后 遍历worker
for (pos <- 0 until numUsable) {
// 只要判断之前给这个worker分配到了core
if (assigned(pos) > 0) {
// 那么就在worker上启动Executor
// 首先,在Application内部缓存结构中,添加Executor,并且创建ExecutorDesc对象,其中封装了,给这个Executor分配多少个cpu core
// 这里,spark 1.3.0版本的Executor启动的内部机制
// 在spark-submit脚本中,可以指定要多少个Executor,每个Executor需要多少个cpu,多少内存
// 那么基于spreadOutApps机制,实际上,最终,Executor的实际数量,以及每个Executor的cpu,可能与配置是不一样的
// 因为我们这里是基于总的cpu来分配的,就是说,比如要求3个Executor,每个要三个cpu,有9个worker,每个有1个cpu
// 那么根据这种算法,会给每个worker分配一个core,然后给每个worker启动一个Executor
// 最后会启动9个Executor,每个Executor有一个cpu core
val exec = app.addExecutor(usableWorkers(pos), assigned(pos))
// 在worker上启动Executor
launchExecutor(usableWorkers(pos), exec)
// 将application的状态设置为RUNNING
app.state = ApplicationState.RUNNING
}
}
}
} else {
// Pack each app into as few nodes as possible until we've assigned all its cores
// 非spreadOutApps调度算法,将每一个application,尽可能少的分配到Worker上去
// 这种算法和spreadOutApps算法正好相反,每个application都尽可能分配到尽量少的worker上去
// 比如总共有10个worker,每个有10个core,Application总共要分配20个core
// 那么其实只会分配到两个worker上,每个worker都占满10个core,那么其余的application,就只能分配到下一个worker了
// 遍历worker,并且状态为ALIVE。还有空闲空间的worker
for (worker <- workers if worker.coresFree > 0 && worker.state == WorkerState.ALIVE) {
// 遍历application,并且是还有需要分配的core的application
for (app <- waitingApps if app.coresLeft > 0) {
// 判断,如果当前这个worker可以被application使用
if (canUse(app, worker)) {
// 取worker剩余cpu数量,与application要分配的cpu数量的最小值
val coresToUse = math.min(worker.coresFree, app.coresLeft)
// 如果worker剩余cpu为0,那么就不分配了
if (coresToUse > 0) {
// 给application添加一个executor
val exec = app.addExecutor(worker, coresToUse)
// 在worker上启动executor
launchExecutor(worker, exec)
// 将application的状态设置为RUNNING
app.state = ApplicationState.RUNNING
}
}
}
}
}
}
###launchExecutor()方法
def launchExecutor(worker: WorkerInfo, exec: ExecutorDesc) {
logInfo("Launching executor " + exec.fullId + " on worker " + worker.id)
// 将Executor加入worker内部的缓存
worker.addExecutor(exec)
// 向worker的actor发送LaunchExecutor消息
worker.actor ! LaunchExecutor(masterUrl,
exec.application.id, exec.id, exec.application.desc, exec.cores, exec.memory)
// 向Executor对应的application对应的driver,发送ExecutorAdded消息
exec.application.driver ! ExecutorAdded(
exec.id, worker.id, worker.hostPort, exec.cores, exec.memory)
}
canUse()方法
def canUse(app: ApplicationInfo, worker: WorkerInfo): Boolean = {
worker.memoryFree >= app.desc.memoryPerSlave && !worker.hasExecutor(app)
}
14、master原理与源码分析的更多相关文章
- ConcurrentHashMap实现原理及源码分析
ConcurrentHashMap实现原理 ConcurrentHashMap源码分析 总结 ConcurrentHashMap是Java并发包中提供的一个线程安全且高效的HashMap实现(若对Ha ...
- HashMap和ConcurrentHashMap实现原理及源码分析
HashMap实现原理及源码分析 哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表, ...
- OpenCV学习笔记(27)KAZE 算法原理与源码分析(一)非线性扩散滤波
http://blog.csdn.net/chenyusiyuan/article/details/8710462 OpenCV学习笔记(27)KAZE 算法原理与源码分析(一)非线性扩散滤波 201 ...
- (转)ReentrantLock实现原理及源码分析
背景:ReetrantLock底层是基于AQS实现的(CAS+CHL),有公平和非公平两种区别. 这种底层机制,很有必要通过跟踪源码来进行分析. 参考 ReentrantLock实现原理及源码分析 源 ...
- 【转】HashMap实现原理及源码分析
哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景极其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表,而HashMap的实现原理也常常出 ...
- 【OpenCV】SIFT原理与源码分析:DoG尺度空间构造
原文地址:http://blog.csdn.net/xiaowei_cqu/article/details/8067881 尺度空间理论 自然界中的物体随着观测尺度不同有不同的表现形态.例如我们形 ...
- 《深入探索Netty原理及源码分析》文集小结
<深入探索Netty原理及源码分析>文集小结 https://www.jianshu.com/p/239a196152de
- HashMap实现原理及源码分析之JDK8
继续上回HashMap的学习 HashMap实现原理及源码分析之JDK7 转载 Java8源码-HashMap 基于JDK8的HashMap源码解析 [jdk1.8]HashMap源码分析 一.H ...
- 【OpenCV】SIFT原理与源码分析:关键点描述
<SIFT原理与源码分析>系列文章索引:http://www.cnblogs.com/tianyalu/p/5467813.html 由前一篇<方向赋值>,为找到的关键点即SI ...
随机推荐
- 2.Vue 获取企业微信的Code并把Code发送的后台进行验证
1 . 在企业微信配置请求的页面写入下面代码 mounted() { //获取微信请求的的Code let code = this.$route.query.code; if (code) { thi ...
- 网页包抓取工具Fiddler工具简单设置
当下载好fiddler软件后首先通过以下简单设置,或者有时候fiddler抓取不了浏览器资源了.可以通过以下设置. 设置完成后重启软件.打开网络看看有没有抓取到包.
- angular异步获取数据后在ngOnInit中无法获取,显示undefined解决办法
两种方法 1 通过*ngif动态加载要数据渲染的dom 2 通过路由导航resolve 第一种感觉太麻烦了,要是一个页面请求多个接口,那就不得不写多个*ngif,本人还是更倾向与第二种发法 具体步骤: ...
- PHP写的简单数字验证码
用PHP写的随机生成的5位数字验证码 $yzm = ""; for($i=0;$i<5;$i++) { $a = rand(0,9); $yzm.= $a; } echo $ ...
- 浅谈React编程思想
React是Facebook推出的面向视图层开发的一个框架,用于解决大型应用,包括如何很好地管理DOM结构,是构建大型,快速Web app的首选方式. React使用JavaScript来构建用户界面 ...
- JAVA - Windows下JDK默认安装的配置参数
JDK版本1.8 JAVA_HOME C:\Program Files\Java\jdk1.8.0_60 CLASSPATH .;%%JAVA_HOME%%\lib;%%JAVA_HOME%%\lib ...
- Swift枚举的全用法
鉴于昨天开会部门会议讨论的时候,发现有些朋友对枚举的用法还是存在一些疑问,所以就写下这个文章,介绍下Swift下的枚举的用法. 基本的枚举类型 来,二话不说,我们先贴一个最基本的枚举: enum Mo ...
- 输入web网站点击之后发生的事情
(1)用户在浏览器(客户端)里输入或者点击一个连接: (2)浏览器向服务器发送HTTP请求: (3)服务器处理请求,如果查询字符串或者请求体里含有参数,服务器也会把这些参数信息考虑进去: (4)服务器 ...
- 交叉编译openssl1.1.1a
交叉编译openssl1.1.1a的时候遇到的问题,记录一下,方便下次查找 一.下载源码 1.打开openssl官网,下载openssl-1.1.1.tar.gz源码包. 2.执行下面的命令解压源 ...
- git学习记录--标签随笔
创建标签: 命令git tag <name>用于新建一个标签,默认为HEAD,也可以指定一个commit id: git tag -a <tagname> -m "b ...