Redis cluster的核心原理分析
一、节点间的内部通信机制
1、基础通信原理
(1)redis cluster节点间采取gossip协议进行通信
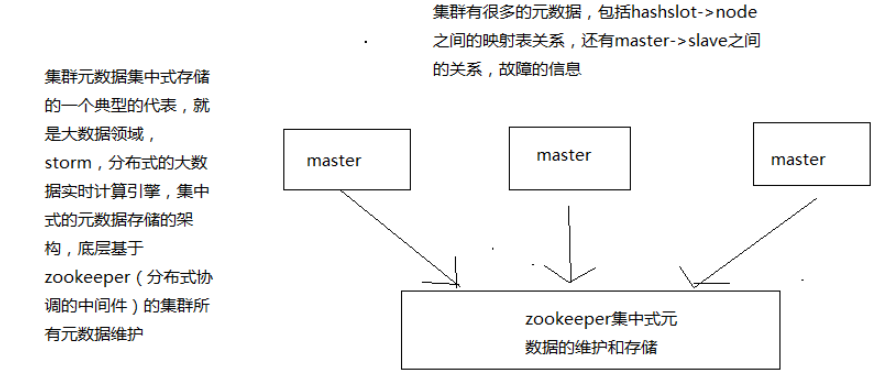
跟集中式不同,不是将集群元数据(节点信息,故障,等等)集中存储在某个节点上,而是互相之间不断通信,保持整个集群所有节点的数据是完整的
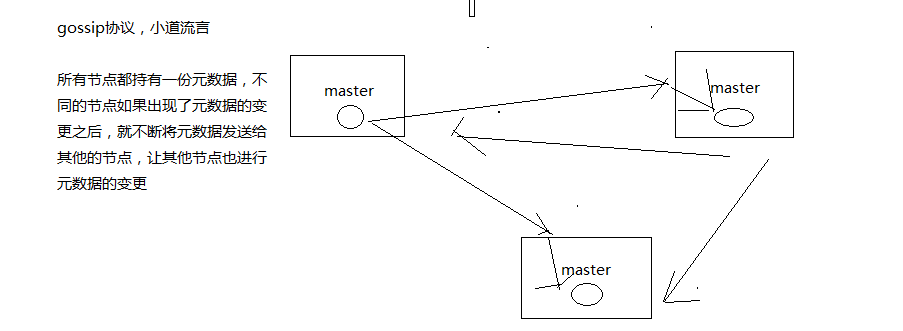
维护集群的元数据用得,集中式,一种叫做gossip
集中式:好处在于,元数据的更新和读取,时效性非常好,一旦元数据出现了变更,立即就更新到集中式的存储中,其他节点读取的时候立即就可以感知到;
不好在于,所有的元数据的跟新压力全部集中在一个地方,可能会导致元数据的存储有压力
gossip:好处在于,元数据的更新比较分散,不是集中在一个地方,更新请求会陆陆续续,打到所有节点上去更新,有一定的延时,降低了压力;
缺点,元数据更新有延时,可能导致集群的一些操作会有一些滞后
我们刚才做reshard,去做另外一个操作,会发现说,configuration error,达成一致
(2)10000端口
每个节点都有一个专门用于节点间通信的端口,就是自己提供服务的端口号+10000,比如7001,那么用于节点间通信的就是17001端口
每隔节点每隔一段时间都会往另外几个节点发送ping消息,同时其他几点接收到ping之后返回pong
(3)交换的信息
故障信息,节点的增加和移除,hash slot信息,等等
2、gossip协议
gossip协议包含多种消息,包括ping,pong,meet,fail,等等
meet: 某个节点发送meet给新加入的节点,让新节点加入集群中,然后新节点就会开始与其他节点进行通信
redis-trib.rb add-node
其实内部就是发送了一个gossip meet消息,给新加入的节点,通知那个节点去加入我们的集群
ping: 每个节点都会频繁给其他节点发送ping,其中包含自己的状态还有自己维护的集群元数据,互相通过ping交换元数据
每个节点每秒都会频繁发送ping给其他的集群,ping,频繁的互相之间交换数据,互相进行元数据的更新
pong: 返回ping和meet,包含自己的状态和其他信息,也可以用于信息广播和更新
fail: 某个节点判断另一个节点fail之后,就发送fail给其他节点,通知其他节点,指定的节点宕机了
3、ping消息深入
ping很频繁,而且要携带一些元数据,所以可能会加重网络负担
每个节点每秒会执行10次ping,每次会选择5个最久没有通信的其他节点
当然如果发现某个节点通信延时达到了cluster_node_timeout / 2,那么立即发送ping,避免数据交换延时过长,落后的时间太长了
比如说,两个节点之间都10分钟没有交换数据了,那么整个集群处于严重的元数据不一致的情况,就会有问题
所以cluster_node_timeout可以调节,如果调节比较大,那么会降低发送的频率
每次ping,一个是带上自己节点的信息,还有就是带上1/10其他节点的信息,发送出去,进行数据交换
至少包含3个其他节点的信息,最多包含总节点-2个其他节点的信息
二、面向集群的jedis内部实现原理
开发,jedis,redis的java client客户端,redis cluster,jedis cluster api
jedis cluster api与redis cluster集群交互的一些基本原理
1、基于重定向的客户端
redis-cli -c,自动重定向
(1)请求重定向
客户端可能会挑选任意一个redis实例去发送命令,每个redis实例接收到命令,都会计算key对应的hash slot
如果在本地就在本地处理,否则返回moved给客户端,让客户端进行重定向
cluster keyslot mykey,可以查看一个key对应的hash slot是什么
用redis-cli的时候,可以加入-c参数,支持自动的请求重定向,redis-cli接收到moved之后,会自动重定向到对应的节点执行命令
(2)计算hash slot
计算hash slot的算法,就是根据key计算CRC16值,然后对16384取模,拿到对应的hash slot
用hash tag可以手动指定key对应的slot,同一个hash tag下的key,都会在一个hash slot中,比如set mykey1:{100}和set mykey2:{100}
(3)hash slot查找
节点间通过gossip协议进行数据交换,就知道每个hash slot在哪个节点上
2、smart jedis
(1)什么是smart jedis
基于重定向的客户端,很消耗网络IO,因为大部分情况下,可能都会出现一次请求重定向,才能找到正确的节点
所以大部分的客户端,比如java redis客户端,就是jedis,都是smart的
本地维护一份hashslot -> node的映射表,缓存,大部分情况下,直接走本地缓存就可以找到hashslot -> node,不需要通过节点进行moved重定向
(2)JedisCluster的工作原理
在JedisCluster初始化的时候,就会随机选择一个node,初始化hashslot -> node映射表,同时为每个节点创建一个JedisPool连接池
每次基于JedisCluster执行操作,首先JedisCluster都会在本地计算key的hashslot,然后在本地映射表找到对应的节点
如果那个node正好还是持有那个hashslot,那么就ok; 如果说进行了reshard这样的操作,可能hashslot已经不在那个node上了,就会返回moved
如果JedisCluter API发现对应的节点返回moved,那么利用该节点的元数据,更新本地的hashslot -> node映射表缓存
重复上面几个步骤,直到找到对应的节点,如果重试超过5次,那么就报错,JedisClusterMaxRedirectionException
jedis老版本,可能会出现在集群某个节点故障还没完成自动切换恢复时,频繁更新hash slot,频繁ping节点检查活跃,导致大量网络IO开销
jedis最新版本,对于这些过度的hash slot更新和ping,都进行了优化,避免了类似问题
(3)hashslot迁移和ask重定向
如果hash slot正在迁移,那么会返回ask重定向给jedis
jedis接收到ask重定向之后,会重新定位到目标节点去执行,但是因为ask发生在hash slot迁移过程中,所以JedisCluster API收到ask是不会更新hashslot本地缓存
已经可以确定说,hashslot已经迁移完了,moved是会更新本地hashslot->node映射表缓存的
三、高可用性与主备切换原理
redis cluster的高可用的原理,几乎跟哨兵是类似的
1、判断节点宕机
如果一个节点认为另外一个节点宕机,那么就是pfail,主观宕机
如果多个节点都认为另外一个节点宕机了,那么就是fail,客观宕机,跟哨兵的原理几乎一样,sdown,odown
在cluster-node-timeout内,某个节点一直没有返回pong,那么就被认为pfail
如果一个节点认为某个节点pfail了,那么会在gossip ping消息中,ping给其他节点,如果超过半数的节点都认为pfail了,那么就会变成fail
2、从节点过滤
对宕机的master node,从其所有的slave node中,选择一个切换成master node
检查每个slave node与master node断开连接的时间,如果超过了cluster-node-timeout * cluster-slave-validity-factor,那么就没有资格切换成master
这个也是跟哨兵是一样的,从节点超时过滤的步骤
3、从节点选举
哨兵:对所有从节点进行排序,slave priority,offset,run id
每个从节点,都根据自己对master复制数据的offset,来设置一个选举时间,offset越大(复制数据越多)的从节点,选举时间越靠前,优先进行选举
所有的master node开始slave选举投票,给要进行选举的slave进行投票,如果大部分master node(N/2 + 1)都投票给了某个从节点,那么选举通过,那个从节点可以切换成master
从节点执行主备切换,从节点切换为主节点
4、与哨兵比较
整个流程跟哨兵相比,非常类似,所以说,redis cluster功能强大,直接集成了replication和sentinal的功能
1、fork耗时导致高并发请求延时
RDB和AOF的时候,其实会有生成RDB快照,AOF rewrite,耗费磁盘IO的过程,主进程fork子进程
fork的时候,子进程是需要拷贝父进程的空间内存页表的,也是会耗费一定的时间的
一般来说,如果父进程内存有1个G的数据,那么fork可能会耗费在20ms左右,如果是10G~30G,那么就会耗费20 * 10,甚至20 * 30,也就是几百毫秒的时间
info stats中的latest_fork_usec,可以看到最近一次form的时长
redis单机QPS一般在几万,fork可能一下子就会拖慢几万条操作的请求时长,从几毫秒变成1秒
优化思路
fork耗时跟redis主进程的内存有关系,一般控制redis的内存在10GB以内,slave -> master,全量复制
2、AOF的阻塞问题
redis将数据写入AOF缓冲区,单独开一个现场做fsync操作,每秒一次
但是redis主线程会检查两次fsync的时间,如果距离上次fsync时间超过了2秒,那么写请求就会阻塞
everysec,最多丢失2秒的数据
一旦fsync超过2秒的延时,整个redis就被拖慢
优化思路
优化硬盘写入速度,建议采用SSD,不要用普通的机械硬盘,SSD,大幅度提升磁盘读写的速度
3、主从复制延迟问题
主从复制可能会超时严重,这个时候需要良好的监控和报警机制
在info replication中,可以看到master和slave复制的offset,做一个差值就可以看到对应的延迟量
如果延迟过多,那么就进行报警
4、主从复制风暴问题
如果一下子让多个slave从master去执行全量复制,一份大的rdb同时发送到多个slave,会导致网络带宽被严重占用
如果一个master真的要挂载多个slave,那尽量用树状结构,不要用星型结构
5、vm.overcommit_memory
0: 检查有没有足够内存,没有的话申请内存失败
1: 允许使用内存直到用完为止
2: 内存地址空间不能超过swap + 50%
如果是0的话,可能导致类似fork等操作执行失败,申请不到足够的内存空间
cat /proc/sys/vm/overcommit_memory
echo "vm.overcommit_memory=1" >> /etc/sysctl.conf
sysctl vm.overcommit_memory=1
6、swapiness
cat /proc/version,查看linux内核版本
如果linux内核版本<3.5,那么swapiness设置为0,这样系统宁愿swap也不会oom killer(杀掉进程)
如果linux内核版本>=3.5,那么swapiness设置为1,这样系统宁愿swap也不会oom killer
保证redis不会被杀掉
echo 0 > /proc/sys/vm/swappiness
echo vm.swapiness=0 >> /etc/sysctl.conf
7、最大打开文件句柄
ulimit -n 10032 10032
自己去上网搜一下,不同的操作系统,版本,设置的方式都不太一样
8、tcp backlog
cat /proc/sys/net/core/somaxconn
echo 511 > /proc/sys/net/core/somaxconn
redis:持久化、复制(主从架构)、哨兵(高可用,主备切换)、redis cluster(海量数据+横向扩容+高可用/主备切换)
持久化:高可用的一部分,在发生redis集群灾难的情况下(比如说部分master+slave全部死掉了),如何快速进行数据恢复,快速实现服务可用,才能实现整个系统的高可用
复制:主从架构,master -> slave 复制,读写分离的架构,写master,读slave,横向扩容slave支撑更高的读吞吐,读高并发,10万,20万,30万,上百万,QPS,横向扩容
哨兵:高可用,主从架构,在master故障的时候,快速将slave切换成master,实现快速的灾难恢复,实现高可用性
redis cluster:多master读写,数据分布式的存储,横向扩容,水平扩容,快速支撑高达的数据量+更高的读写QPS,自动进行master -> slave的主备切换,高可用
让底层的缓存系统,redis,实现能够任意水平扩容,支撑海量数据(1T+,几十T,10G * 600 redis = 6T),支撑很高的读写QPS(redis单机在几万QPS,10台,几十万QPS),高可用性(给我们每个redis实例都做好AOF+RDB的备份策略+容灾策略,slave -> master主备切换)
1T+海量数据、10万+读写QPS、99.99%高可用性
3、redis的第一套企业级的架构
如果你的数据量不大,单master就可以容纳,一般来说你的缓存的总量在10G以内就可以,那么建议按照以下架构去部署redis
redis持久化+备份方案+容灾方案+replication(主从+读写分离)+sentinal(哨兵集群,3个节点,高可用性)
可以支撑的数据量在10G以内,可以支撑的写QPS在几万左右,可以支撑的读QPS可以上10万以上(随你的需求,水平扩容slave节点就可以),可用性在99.99%
4、redis的第二套企业级架构
多master分布式存储数据,水平扩容
支撑更多的数据量,1T+以上没问题,只要扩容master即可
读写QPS分别都达到几十万都没问题,只要扩容master即可,redis cluster,读写分离,支持不太好,readonly才能去slave上读
支撑99.99%可用性,也没问题,slave -> master的主备切换,冗余slave去进一步提升可用性的方案(每个master挂一个slave,但是整个集群再加个3个slave冗余一下)
Redis cluster的核心原理分析的更多相关文章
- Redis深度历险——核心原理与应用实践
高可用架构」的各位老铁们,你们好!你是否还记得上个月发布的文章中,有两篇深入讲解Redis的文章,分别是和,广大粉丝读者们对这两篇文章整体评价颇高.而我就是这两篇文章的原创作者「老钱」(钱文品),我是 ...
- Redis Cluster 分区实现原理
Redis Cluster本身提供了自动将数据分散到Redis Cluster不同节点的能力,分区实现的关键点问题包括:如何将数据自动地打散到不同的节点,使得不同节点的存储数据相对均匀:如何保证客户端 ...
- Redis有序集内部实现原理分析(二)
Redis技术交流群481804090 Redis:https://github.com/zwjlpeng/Redis_Deep_Read 本篇博文紧随上篇Redis有序集内部实现原理分析,在这篇博文 ...
- Java Reference核心原理分析
本文转载自Java Reference核心原理分析 导语 带着问题,看源码针对性会更强一点.印象会更深刻.并且效果也会更好.所以我先卖个关子,提两个问题(没准下次跳槽时就被问到). 我们可以用Byte ...
- Redis 发布/订阅机制原理分析
Redis 通过 PUBLISH. SUBSCRIBE 和 PSUBSCRIBE 等命令实现发布和订阅功能. 这些命令被广泛用于构建即时通信应用,比如网络聊天室(chatroom)和实时广播.实时 ...
- Redis主从架构核心原理
Redis-Cluster工作原理: redis集群内置了16384个哈希槽,当需要在 Redis 集群中放置一个 key-value 时,redis 先对 key 使用 crc16 算法算出一个结果 ...
- Spring核心原理分析之MVC九大组件(1)
本文节选自<Spring 5核心原理> 1 什么是Spring MVC Spring MVC 是 Spring 提供的一个基于 MVC 设计模式的轻量级 Web 开发框架,本质上相当于 S ...
- 【Redis】跳跃表原理分析与基本代码实现(java)
最近开始看Redis设计原理,碰到一个从未遇见的数据结构:跳跃表(skiplist).于是花时间学习了跳表的原理,并用java对其实现. 主要参考以下两本书: <Redis设计与实现>跳表 ...
- Redis有序集内部实现原理分析
Redis技术交流群481804090 Redis:https://github.com/zwjlpeng/Redis_Deep_Read Redis中支持的数据结构比Memcached要多的多啦,如 ...
随机推荐
- nginx.conf 配置解析之 http配置
官方文档 http://nginx.org/en/docs/参考链接: https://segmentfault.com/a/1190000012672431参考链接: https://segment ...
- planning algorithms chapter 2
planning algorithms chapter 2 :Discrete Planning 离散可行规划导论 问题定义 在离散规划中,状态是"可数"的,有限的. 离散可行规划 ...
- 洛谷P5171 Earthquake
题面 题解 我们先把样例画出来: 看到它是一个减函数感觉很烦,考虑把函数转过来一下: 转过来的函数通过推导可得为: \[ y = \frac abx + \frac {c \bmod a}b \] 于 ...
- html内获取当前文件路径,页面获取当前路径
function getRealPath(){ var curWwwPath = window.document.location.href; var pathName = window.docume ...
- JDBC PreparedStatement Statement
参考:预编译语句(Prepared Statements)介绍,以MySQL为例 1. 背景 本文重点讲述MySQL中的预编译语句并从MySQL的Connector/J源码出发讲述其在Java语言中相 ...
- 代码审计和动态测试——BUUCTF - 高明的黑客
根据题目提示,访问http://2ea746a2-0ecd-449b-896b-e0fb38956134.node1.buuoj.cn/www.tar.gz下载源码 解压之后发现有3002个php文件 ...
- android x86 固件定制
测试提了几个bug 1.系统语言默认设置成中文,否则时间控件显示的内容有问题 2.关闭10分钟不操作自动休眠功能 3.默认关闭虚拟键盘,目的在文本控件点击后,虚拟键盘就会在右下角显示出来,导致物理键盘 ...
- MySQL应用报错:java.sql.SQLException: Lock wait timeout exceeded; try restarting transaction
开发反馈,某业务系统插入一条记录的时候,日志报错,插入失败: ### Error updating database. Cause: java.sql.SQLException: Lock wait ...
- Wordpress 安装或切换不同的版本
如果升级到最新版本的 Wordpress 后,发现有 bug,需要回滚回上一个相对稳定的版本,可以按照如下步骤: 一.到官网下载压缩包 https://wordpress.org/download/r ...
- nodejs相关框架
sails https://sailsjs.com/documentation/concepts koa koa 是由 Express 原班人马打造的,致力于成为一个更小.更富有表现力.更健壮的 ...