HDFS内存配置
下图是HDFS的架构:
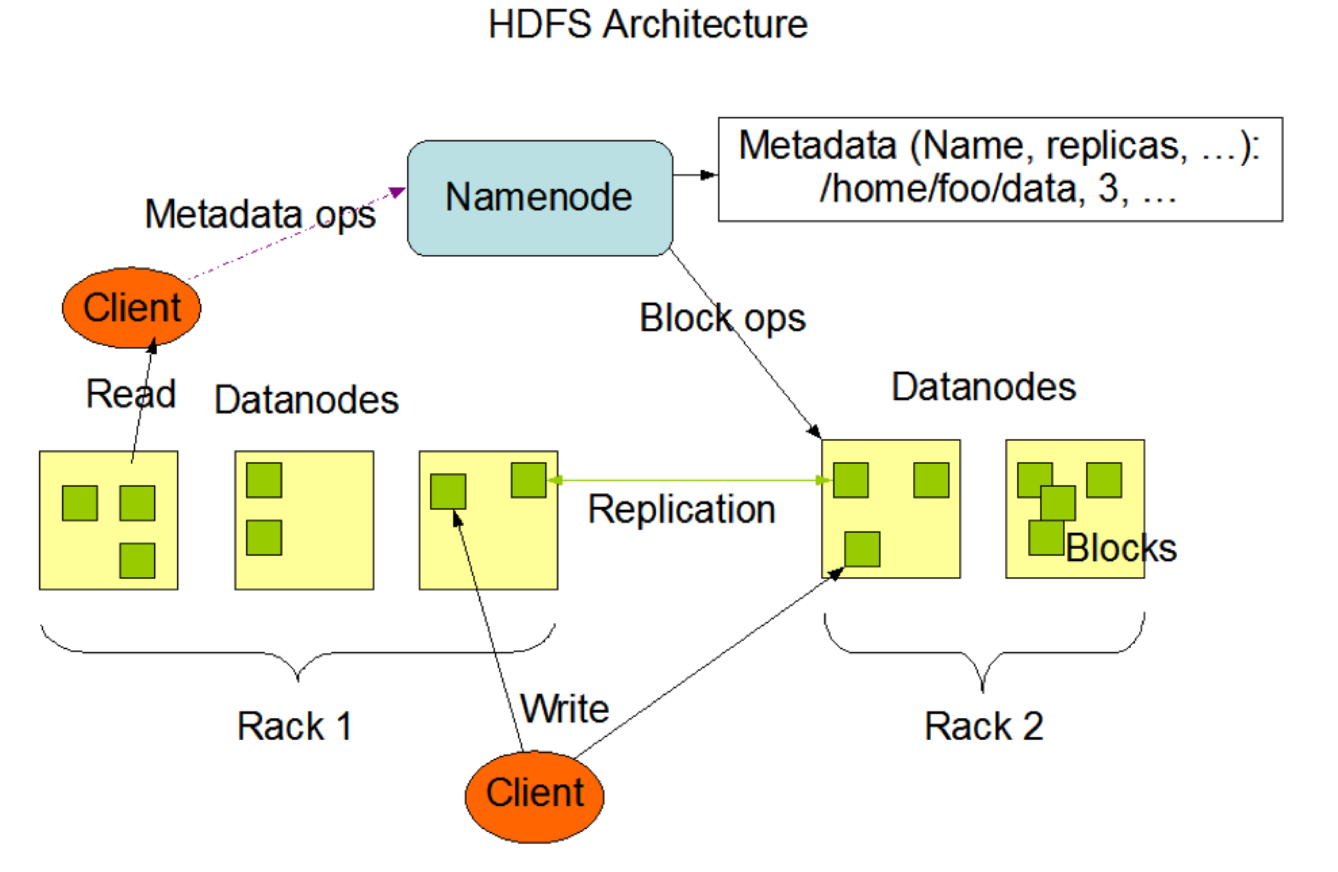
从上图中可以知道,HDFS包含了NameNode、DataNode以及Client三个角色,当我们的HDFS没有配置HA的时候,那还有一个角色就是SecondaryNameNode,这四个角色都是基于JVM之上的Java进程。既然是Java进程,那我们肯定可以调整这四个角色使用的内存的大小。接下来我们就详细来看下怎么配置HDFS每个角色的内存
我们这里说配置的内存主要还是指JVM的堆内存
默认的内存配置
NameNode
当启动我们在视频课程中搭建好HDFS集群后,我们可以在master上通过如下的命令来查看NameNode和SecondaryNameNode这两个进程占用的堆内存:
## 在master机器上执行
ps -ef | grep NameNode
得到的结果如下:
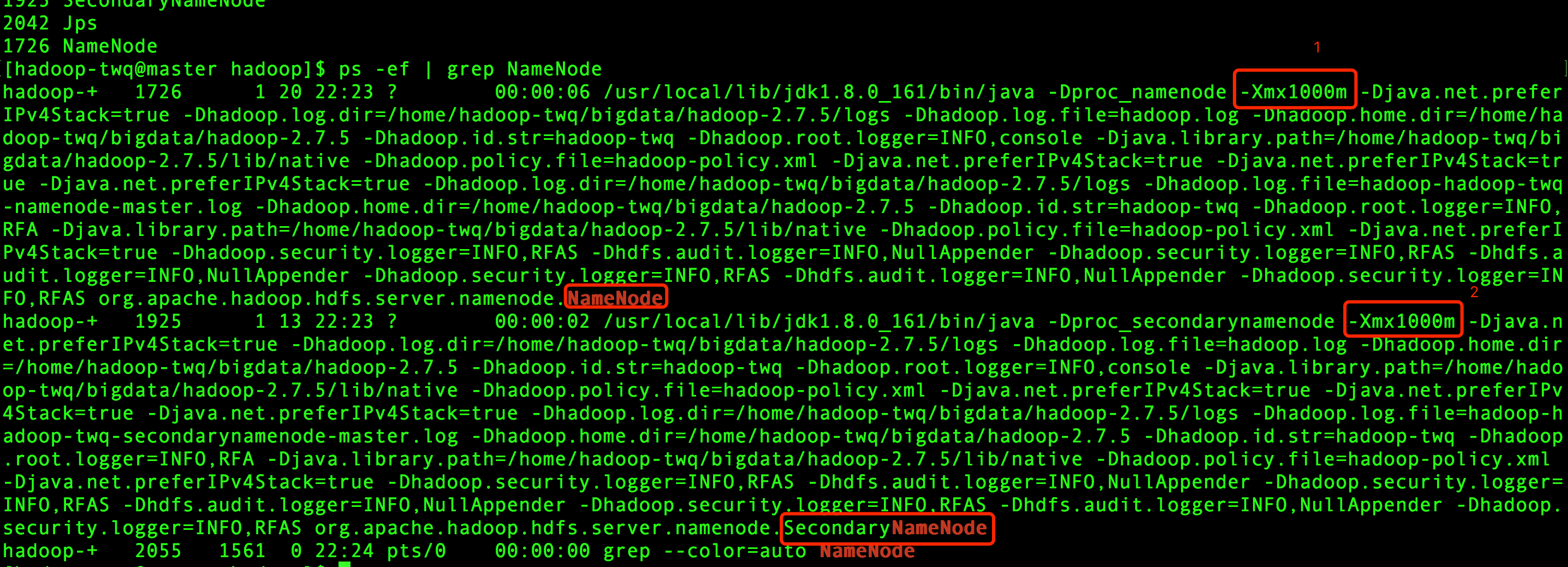
上图中第1处的-Xmx1000m表示NameNode的堆内存是1000M
上图中第2处的-Xmx1000m表示SecondaryNameNode的堆内存是1000M
DataNode
我们可以通过如下的命令来查看slave1和slave2上的DataNode占用的堆内存:
ps -ef | grep DataNode
得到的结果如下:


从上图可以看出,两个slave上的DataNode的堆内存都是1000M
Client
当我们执行下面命令的时候:
hadoop fs -ls /
其实也是启动一个名字为FsShell的Java进程,如下图:
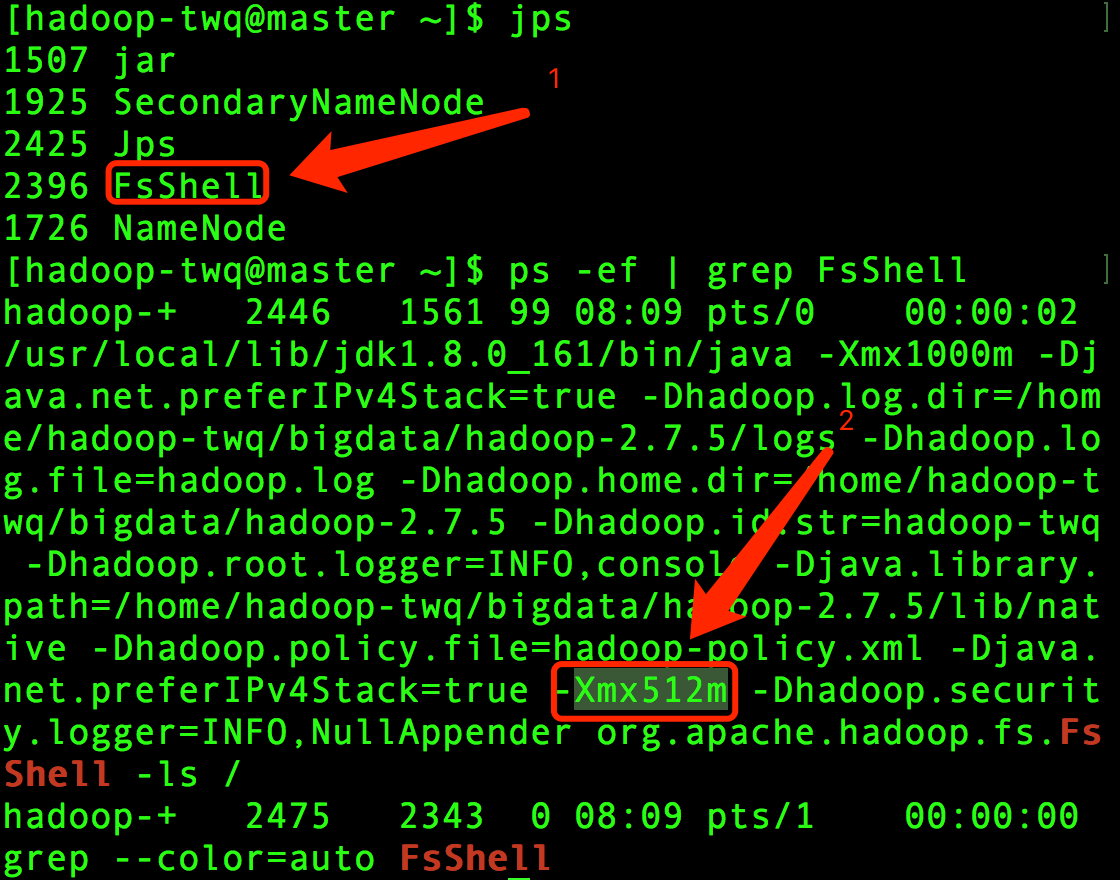
这个FsShell进程就是一个Client进程,这个Client进程的默认堆内存是512M
结论
- HDFS集群中的角色(NameNode、SecondaryNameNode、DataNode)的默认的堆内存大小都是
1000M - Client进程的堆内存大小是
512M
如何配置内存
要想知道如何配置每个角色的内存,我们首先需要搞明白上面默认的内存配置是在哪里配置的。
这些默认的配置都是在Hadoop的安装目录下的配置目录下文件hadoop-env.sh中,即/home/hadoop-twq/bigdata/hadoop-2.7.5/etc/hadoop/hadoop-env.sh
在hadoop-env.sh文件中有几个和内存相关的配置:
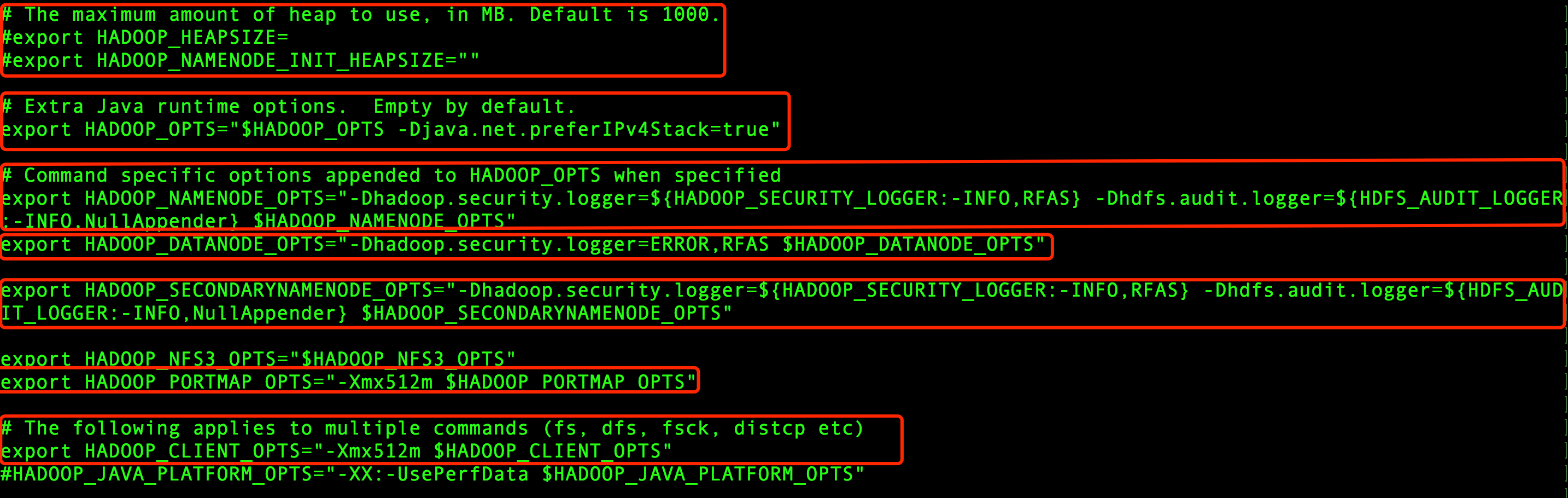
我们按照上图从上往下,分别仔细看下
# The maximum amount of heap to use, in MB. Default is 1000.
#export HADOOP_HEAPSIZE=
#export HADOOP_NAMENODE_INIT_HEAPSIZE=""
HADOOP_HEAPSIZE:表示HDFS中所有角色的最大堆内存,默认是1000M,这个也就是我们所有HDFS角色进程的默认堆内存大小
HADOOP_NAMENODE_INIT_HEAPSIZE:表示NameNode的初始化堆内存大小,默认也是1000M。
# Extra Java runtime options. Empty by default.
export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true"
HADOOP_OPTS: 表示HDFS所有角色的JVM参数设置,对于HDFS所有角色的通用的JVM参数可以通过这个配置来设置。默认的话是空的配置
# Command specific options appended to HADOOP_OPTS when specified
export HADOOP_NAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER
:-INFO,NullAppender} $HADOOP_NAMENODE_OPTS"
HADOOP_NAMENODE_OPTS:针对NameNode的特殊的JVM参数的配置,默认只设置hadoop.security.logger和hdfs.audit.logger两个日志级别信息参数
export HADOOP_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS $HADOOP_DATANODE_OPTS"
HADOOP_DATANODE_OPTS:针对DataNode的特殊的JVM参数的配置,默认只设置hadoop.security.logger日志级别信息参数
export HADOOP_SECONDARYNAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUD
IT_LOGGER:-INFO,NullAppender} $HADOOP_SECONDARYNAMENODE_OPTS"
HADOOP_SECONDARYNAMENODE_OPTS:针对SecondaryNameNode的特殊的JVM参数的配置,默认只设置hadoop.security.logger和hdfs.audit.logger两个日志级别信息参数
export HADOOP_PORTMAP_OPTS="-Xmx512m $HADOOP_PORTMAP_OPTS"
HADOOP_PORTMAP_OPTS:这个是在HDFS格式化时需要的JVM配置,也就是执行hdfs namenode -format时的JVM配置
# The following applies to multiple commands (fs, dfs, fsck, distcp etc)
export HADOOP_CLIENT_OPTS="-Xmx512m $HADOOP_CLIENT_OPTS"
HADOOP_CLIENT_OPTS:表示HDFS客户端命令启动的JVM的参数配置,这里配置的JVM的堆内存的大小为512M。这个配置是针对客户端命令(比如fs, dfs, fsck, distcp等)的JVM堆内存配置
NameNode、DataNode以及Client进程堆内存的配置方式
NameNode、DataNode以及Client进程堆内存是在hadoop-env.sh中的配置HADOOP_NAMENODE_OPTS、HADOOP_DATANODE_OPTS以及HADOOP_CLIENT_OPTS配置的
所以我们如果想配置NameNode的堆内存可以有两种方式:
## 第一种方式
export HADOOP_NAMENODE_INIT_HEAPSIZE="20480M" ## 第二种方式
export HADOOP_NAMENODE_OPTS="-Xms20480M -Xmx20480M -Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOO
P_NAMENODE_OPTS"
如果我们想配置DataNode的堆内存可以有以下两种方式:
## 第一种方式
export HADOOP_HEAPSIZE=2048M ## 第二种方式,这种方式会覆盖掉上面第一种方式的配置
export HADOOP_DATANODE_OPTS="-Xms2048M -Xmx2048M -Dhadoop.security.logger=ERROR,RFAS $HADOOP_DATANODE_OPTS"
如果我们想配置Client的堆内存可以有如下方式:
export HADOOP_CLIENT_OPTS="-Xmx1024m $HADOOP_CLIENT_OPTS"
HDFS内存配置的更多相关文章
- 第6章 HDFS HA配置
目录 6.1 hdfs-site.xml文件配置 6.2 core-site.xml文件配置 6.3 启动与测试 6.4 结合ZooKeeper进行自动故障转移 在Hadoop 2.0.0之前,一个H ...
- STL库的内存配置器(allocator)
正在学习中,如果有错,还请多多指教,根据不断的理解,会进行更改,更改之前的样子都会保留下来,记录错误是最大的进步,嗯嗯! 具有次配置力的SGI空间配置器(SGI是STL的一种版本,也有其他的版本) 这 ...
- eclipse启动时虚拟机初始内存配置
eclipse启动时虚拟机初始内存配置: -Xms256M -Xmx512M -XX:PermSize=256m -XX:MaxPermSize=512m
- JBOSS最大连接数配置和jvm内存配置
一.调整JBOSS最大连接数. 配置deploy/jboss-web.deployer/server.xml文件 . <Connector port="80 ...
- SQLServer—系统中的内存配置
前言: 本文讲述32位和64位系统中的内存配置,在SQLServer 2005/2008中,DBA们往往尝试开启AWE来限制内存.但是,在SQLServer2012以后,这个选项将被弃用,所以不能使用 ...
- STL内存配置器
一.STL内存配置器的总体设计结构 1.两级内存配置器:SGI-STL中设计了两级的内存配置器,主要用于不同大小的内存分配需求,当需要分配的内存大小大于128bytes时, 使用第一级配置器,否则使用 ...
- 第十七章——配置SQLServer(2)——32位和64位系统中的内存配置
原文:第十七章--配置SQLServer(2)--32位和64位系统中的内存配置 前言: 本文讲述32位和64位系统中的内存配置,在SQLServer 2005/2008中,DBA们往往尝试开启AWE ...
- SGI STL内存配置器存在内存泄漏吗?
阅读了SGI的源码后对STL很是膜拜,很高质量的源码,从中学到了很多.温故而知新!下文中所有STL如无特殊说明均指SGI版本实现. STL 内存配置器 STL对内存管理最核心部分我觉得是其将C++对象 ...
- Tomcat和JDK的内存配置
1.jvm内存管理机制: 1)堆(Heap)和非堆(Non-heap)内存 按照官方的说法:"Java 虚拟机具有一个堆,堆是运行时数据区域,所有类实例和数组的内存均从此处分配.堆是在 Ja ...
随机推荐
- php_mvc实现步骤六
shop34-1-目录布局 存在项目的根目录 shop34 框架代码与应用程序代码划分 框架代码: 在各个应用程序间可以通用的代码. 应用程序代码: 当前项目的业务逻辑实现的代码. 分别创建两个子目录 ...
- docker+k8s基础篇四
Docker+K8s基础篇(四) pod控制器 A:pod控制器类型 ReplicaSet控制器 A:ReplicaSet控制器介绍 B:ReplicaSet控制器的使用 Deployment控制器 ...
- [转帖]FastDFS图片服务器单机安装步骤
FastDFS图片服务器单机安装步骤 https://www.cnblogs.com/yuesf/p/11847103.html 前面已经讲 一张图秒懂微服务的网络架构,通过此文章可以了解FastDF ...
- 前端 html篇
web开发本质: html是一个标准,规定了大家怎么写网页 1.浏览器输入网址回车发生了什么事 1. 浏览器 给服务端 发送了一个消息2. 服务端拿到消息3. 服务端返回消息4. 浏览器展示页面 se ...
- win7系统的CMD窗口切换目录--小计
经常使用win7系统的CMD窗口,需要切换到工作目录,方法如下: 1. Win + R 2. 在命令行输入 cmd 出现如下: C:\Users\admin> 3. 在以上输入 D: (表示切换 ...
- Unity的学习笔记(XLua的初学用法并在lua中使用unity周期函数)
自己最近也在研究怎么用lua控制UI,然后看着网上介绍,决定选用XLua,毕竟TX爸爸出的,有人维护,自己琢磨着怎么用,于是弄出来一个能用的作为记录. 当然,XLua主要是用于热更新,我自己是拿来尝试 ...
- SQL Server中,常用的全局变量
在SQL Server中,全局变量是一种特殊类型的变量,服务器将维护这些变量的值.全局变量以@@前缀开头,不必进行声明,它们属于系统定义的函数.下表就是SQL Server中一些常用的全局变量. 全局 ...
- Eclipse开发环境(一):下载和安装
一.Eclipse下载及安装 1. 下载 进入官网https://www.eclipse.org/,点击 IDE & Tools 选择Java EE 选择Luna Packages 选择Win ...
- 机器码-字节码-CLR-JIT-托管代码-非托管代码-unsafe-GC-fixed
0. 机器码 直接由机器码对应平台的CPU执行的指令集, 因此无法在其他指令集的CPU上运行. 无法跨平台. 由本地代码编译得到. (托管代码通过JIT生成) 1. 字节码 即 bytecode 是一 ...
- 【转载】 C#使用Math.PI常量来表示圆周率
在C#中计算圆形面积的时候,我们时常会用到圆周率这个变量,圆周率我们一般定义为十进制decimal类型变量,圆周率的值为3.1415926535等一个近似值,其实在C#的数值计算类Math类中,有专门 ...