通过phoenix导入数据到hbase出错记录
解决方法1
错误如下
-- ::, [hconnection-0x7b9e01aa-shared--pool11069-t114734] WARN org.apache.hadoop.hbase.ipc.CoprocessorRpcChannel - Call failed on IOException
org.apache.hadoop.hbase.exceptions.UnknownProtocolException: org.apache.hadoop.hbase.exceptions.UnknownProtocolException: No registered coprocessor service found for name ServerCachingService in region TABLE_RESULT,\x012019--\x00037104581382,.dcd3d414bc567586049d3c71aa74512d.
at org.apache.hadoop.hbase.regionserver.HRegion.execService(HRegion.java:)
at org.apache.hadoop.hbase.regionserver.RSRpcServices.execServiceOnRegion(RSRpcServices.java:)
at org.apache.hadoop.hbase.regionserver.RSRpcServices.execService(RSRpcServices.java:)
at org.apache.hadoop.hbase.protobuf.generated.ClientProtos$ClientService$.callBlockingMethod(ClientProtos.java:)
at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:)
at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:) at sun.reflect.GeneratedConstructorAccessor81.newInstance(Unknown Source)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:)
at java.lang.reflect.Constructor.newInstance(Constructor.java:)
at org.apache.hadoop.ipc.RemoteException.instantiateException(RemoteException.java:)
at org.apache.hadoop.ipc.RemoteException.unwrapRemoteException(RemoteException.java:)
at org.apache.hadoop.hbase.protobuf.ProtobufUtil.getRemoteException(ProtobufUtil.java:)
at org.apache.hadoop.hbase.protobuf.ProtobufUtil.execService(ProtobufUtil.java:)
at org.apache.hadoop.hbase.ipc.RegionCoprocessorRpcChannel$.call(RegionCoprocessorRpcChannel.java:)
at org.apache.hadoop.hbase.ipc.RegionCoprocessorRpcChannel$.call(RegionCoprocessorRpcChannel.java:)
at org.apache.hadoop.hbase.client.RpcRetryingCaller.callWithRetries(RpcRetryingCaller.java:)
at org.apache.hadoop.hbase.ipc.RegionCoprocessorRpcChannel.callExecService(RegionCoprocessorRpcChannel.java:)
at org.apache.hadoop.hbase.ipc.CoprocessorRpcChannel.callMethod(CoprocessorRpcChannel.java:)
at org.apache.phoenix.coprocessor.generated.ServerCachingProtos$ServerCachingService$Stub.addServerCache(ServerCachingProtos.java:)
at org.apache.phoenix.cache.ServerCacheClient$$.call(ServerCacheClient.java:)
at org.apache.phoenix.cache.ServerCacheClient$$.call(ServerCacheClient.java:)
at org.apache.hadoop.hbase.client.HTable$.call(HTable.java:)
at java.util.concurrent.FutureTask.run(FutureTask.java:)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:)
at java.lang.Thread.run(Thread.java:)
Caused by: org.apache.hadoop.hbase.ipc.RemoteWithExtrasException(org.apache.hadoop.hbase.exceptions.UnknownProtocolException): org.apache.hadoop.hbase.exceptions.UnknownProtocolException: No registered coprocessor service found for name ServerCachingService in region
TABLE_RESULT,\x012019--\x00037104581382,.dcd3d414bc567586049d3c71aa74512d. at org.apache.hadoop.hbase.regionserver.HRegion.execService(HRegion.java:) at org.apache.hadoop.hbase.regionserver.RSRpcServices.execServiceOnRegion(RSRpcServices.java:) at org.apache.hadoop.hbase.regionserver.RSRpcServices.execService(RSRpcServices.java:) at org.apache.hadoop.hbase.protobuf.generated.ClientProtos$ClientService$.callBlockingMethod(ClientProtos.java:) at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:) at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:) at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:)
错误分析:从错误的信息来看,是关于协处理器的错误,可能是region或者表没有使用协处理器。
web界面查看表信息如下
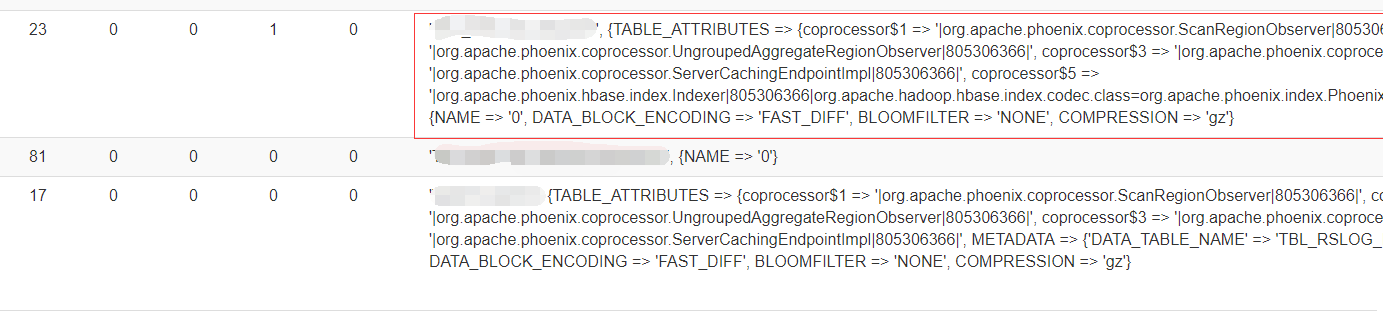
从web信息来看,确实这张表没有相关协处理器的信息,正常通过phoenix创建表以后,都会自带phoenix相关的协处理器信息,如上面红框圈起来的地方,上图有张表(红框下面的这个)却没有,导致phoenix插入数据的时候,由于协处理器问题,导致插入失败,这种情况估计跟二级索引有一定的关系。
解决
修改表属性
# hbase shell
#####添加相关的协处理器信息
hbase(main):005:0> alter 'TABLE_RESULT', { METHOD => 'table_att','coprocessor$1' => '|org.apache.phoenix.coprocessor.ScanRegionObserver|805306366|', 'coprocessor$2' => '|org.apache.phoenix.coprocessor.UngroupedAggregateRegionObserver|805306366|', 'coprocessor$3' => '|org.apache.phoenix.coprocessor.GroupedAggregateRegionObserver|805306366|', 'coprocessor$4' => '|org.apache.phoenix.coprocessor.ServerCachingEndpointImpl|805306366|', 'coprocessor$5' => '|org.apache.phoenix.hbase.index.Indexer|805306366|org.apache.hadoop.hbase.index.codec.class=org.apache.phoenix.index.PhoenixIndexCodec,index.builder=org.apache.phoenix.index.PhoenixIndexBuilder'}
然后通过phoenix导入数据正常。
解决方法2(可能有问题)
从官网或者其他博客搜索到一些解决协处理器的问题,只是借鉴,对我这种情况不起作用
可以全局配置哪些协处理器在 HBase 启动时加载。这可以通过向 hbase-site.xml 配置文件中添加如下配置属性实现:
如下是借鉴其他人的博客:
注意:下面配置属性的值有的是他们自己Java代码实现的,所以,按如下配置加入到hbase的配置文件,在启动的时候会提示找不到相关的协处理器,导致hbase启动失败。
<property>
<name>hbase.coprocessor.master.classes</name>
<value>coprocessor.MasterObserverExample</value>
</property>
<property>
<name>hbase.coprocessor.regionserver.classes</name>
<value>coprocessor.RegionServerObserverExample</value>
</property>
<property>
<name>hbase.coprocessor.region.classes</name>
<value>coprocessor.system.RegionObserverExample, coprocessor.AnotherCoprocessor</value>
</property>
<property>
<name>hbase.coprocessor.user.region.classes</name>
<value>coprocessor.user.RegionObserverExample</value>
</property>
<property>
<name>hbase.coprocessor.wal.classes</name>
<value>coprocessor.WALObserverExample, bar.foo.MyWALObserver</value>
</property>
解决方法3
通过在hbase-site.xml文件中设置参数:
<property>
<name>hbase.coprocessor.abortonerror</name>
<value>false</value>
</property>
并启动region server可以解决,这样就忽略了协处理器出现的错误,保证集群高可用
借鉴:
https://blog.csdn.net/u013709332/article/details/52414999
通过phoenix导入数据到hbase出错记录的更多相关文章
- Hive导入数据到HBase,再与Phoenix映射同步
1. 创建HBase 表 create 'hbase_test','user' 2. 插入数据 put 'hbase_test','111','user:name','jack' put 'hbase ...
- 批量导入数据到HBase
hbase一般用于大数据的批量分析,所以在很多情况下需要将大量数据从外部导入到hbase中,hbase提供了一种导入数据的方式,主要用于批量导入大量数据,即importtsv工具,用法如下: Us ...
- sqlldr导入数据取消回显记录条数
之前在脚本中使用sqlldr导入数据时,如果表的数据量较大的话,会使日志文件变得极大,之后在网上查找了很久,才在一个偶然的机会找到这个参数 silent=all 但是最近发现这样写有个问题,就是加了这 ...
- 用spark导入数据到hbase
集群环境:一主三从,Spark为Spark On YARN模式 Spark导入hbase数据方式有多种 1.少量数据:直接调用hbase API的单条或者批量方法就可以 2.导入的数据量比较大,那就需 ...
- importTSV工具导入数据到hbase
1.建立目标表test,确定好列族信息. create'test','info','address' 2.建立文件编写要导入的数据并上传到hdfs上 touch a.csv vi a.csv 数据内容 ...
- 导入数据到HBase的方式选择
Choosing the Right Import Method If the data is already in an HBase table: To move the data from one ...
- hive向mysql导入数据sqoop命令出错
报错信息: java.lang.Exception: java.io.IOException: java.lang.ClassNotFoundException: info at org.apache ...
- 使用Sqoop从MySQL导入数据到Hive和HBase 及近期感悟
使用Sqoop从MySQL导入数据到Hive和HBase 及近期感悟 Sqoop 大数据 Hive HBase ETL 使用Sqoop从MySQL导入数据到Hive和HBase 及近期感悟 基础环境 ...
- Hbase 学习(十一)使用hive往hbase当中导入数据
我们可以有很多方式可以把数据导入到hbase当中,比如说用map-reduce,使用TableOutputFormat这个类,但是这种方式不是最优的方式. Bulk的方式直接生成HFiles,写入到文 ...
随机推荐
- 2019 同程旅游java面试笔试题 (含面试题解析)
本人5年开发经验.18年年底开始跑路找工作,在互联网寒冬下成功拿到阿里巴巴.今日头条.同程等公司offer,岗位是Java后端开发,因为发展原因最终选择去了同程,入职一年时间了,之前面试了很多家公 ...
- Oracle数据库之四大语言
一.数据定义语言: 1.用于改变数据库结构,包括创建.更改和删除数据库对象: 2.命令: create table :创建 alter table 修改 drop table 删除表 truncate ...
- 一些常用的 Emoji 符号(可直接复制)
表情类
- C#MongDB数据库取某时间段内的数据
BsonDocument bsonDoc = new BsonDocument(); bsonDoc.Add("TimeData", new BsonDocument() { { ...
- 【Oracle RAC】Linux系统Oracle18c RAC安装配置详细记录过程(图文并茂)
本文Oracle 18c GI/RAC on Oracle Linux step-by-step 的安装配置步骤,同时也包含dbca 创建数据库的过程. 1. 关闭SELINUX,防火墙vi /etc ...
- uuid简述
什么是UUID? UUID是Universally Unique Identifier的缩写,它是在一定的范围内(从特定的名字空间到全球)唯一的机器生成的标识符,参考RFC规范-RFC4122. UU ...
- 浅谈Linux下傻瓜式磁盘分区工具cfdisk的使用
对于新手来说,Linux环境下的磁盘分区可能还会存在一些困难.对于熟悉Linux的朋友来说,我们还有fdisk.parted(2TB以上的磁盘分区使用)等磁盘分区工具可以使用.在我们新增磁盘或者在原来 ...
- Javascript技能
Javascript技能 说一说我对 Javascript 这门语言的一些总结(适合前端和后端研发) 基本认识 一些心得 思维脑图的链接(icloud 分享): https://www.icloud. ...
- python coding style guide 的快速落地实践——业内python 编码风格就pep8和谷歌可以认作标准
python coding style guide 的快速落地实践 机器和人各有所长,如coding style检查这种可自动化的工作理应交给机器去完成,故发此文帮助你在几分钟内实现coding st ...
- vs code c/c++编程配置文件
之前的C语言课程老师只讲了C没有接触C++,但是觉得C++挺重要的,而且python和java再去转exe有点麻烦,所以还是学一下C++. 问过朋友推荐了几个IDE,最后他用的是visual stud ...