集合之LinkedList源码分析
转载请注明出处:http://www.cnblogs.com/qm-article/p/8903893.html
一、介绍
在介绍该源码之前,先来了解一下链表,接触过数据结构的都知道,有种结构叫链表,当然链表也分多种,如常见的单链表、双链表等,单链表结构如下图所示(图来自百度)
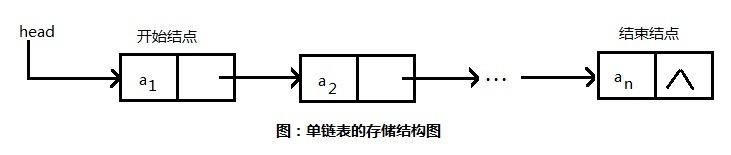
有一个头结点指着下一个节点的位置,a1节点又存储着a2节点的内存位置....,这样就构成了一个单链表形式,下面看一下双链表的结构
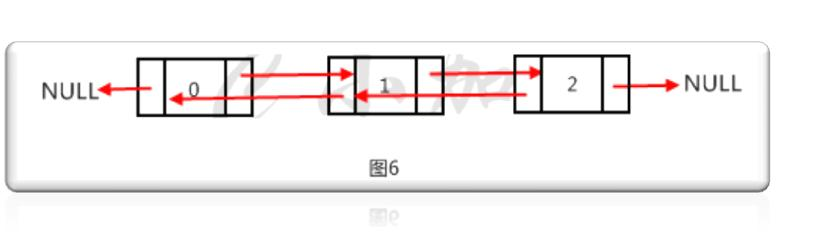
相比于单链表结构,双链表的每个节点多存储了一个数据,就是它的前一个节点的内存地址,链表和数组的区别如下
1、链表的内存不一定是连续的,而数组的内存地址一定是连续的
2、链表的增删操作快,数组的查询操作快。
3、数组一旦开辟了内存地址,基本上大小是固定的,而链表的大小却不固定。
而这篇博文所介绍的java类就是一个链表式结构,而且是一个双向链表,下面呢,就围绕着它的使用来进行分析,说起一个数据结构的操作,无非就是增删改查,接下来来看下该类的源码设计
二、链表设计
如果不先看源码,让我们自己来设计一个功能相对简单的双向链表,那思路该如何,学过面向对象的应该很快就知道,要设计链表,而链表又是由每个节点构成,那么就设计一个内部节点类,让它来表示每个节点,属性呢,按照常规操作,那肯定有该节点值,该节点的前一个节点,该节点的下一个节点,再配上该类的构造函数,如下面的代码
private static class Node{//为了简单,这里没使用泛型,仅以int型代表该节点值得类型
int val;
Node pre;
Node next;
public Node(int val, Node pre, Node next) {
super();
this.val = val;
this.pre = pre;
this.next = next;
}
}
很简单,一个内部类设计完成,考虑完每个节点后,那接下来肯定是考虑整个链,那肯定要写一个类,该类含有内部类Node,至于属性,因为这是双链表,那肯定有头结点,尾节点,还有链表的长度所以很容易就得到下面这段代码
public class LinkedList {
private Node first;//头结点
private Node last;//尾节点
private Node size;//链表长度
private static class Node{
int val;
Node pre;
Node next;
public Node(int val, Node pre, Node next) {
super();
this.val = val;
this.pre = pre;
this.next = next;
}
}
}
既然我们设计出来这个类,那肯定是要用它,用一个数据结构,就像前面说的,就是增删改查。
2.1、增加
这里只是简单的介绍下,增加过程。对于增加节点,可以大致分为这几类
1、在原头结点前增加节点
2、在原尾节点前增加节点
3、在头结点和尾节点之间增加节点
其中的2和3,相信诸位都见得多,那对于1怎么进行处理呢,继续看下去
1、若我们是第一次增加,此时头结点和尾节点都是null,那么很简单,直接用增加的节点去同时赋给头结点和尾节点
2、若不是第一次增加,我们要把结点添加到头结点之前,首先呢,肯定要获取头结点,具体逻辑如下。
public void addHeadNode(Node node){
//将头结点引用赋给临时节点,避免直接操作first变量
Node temp = first;
if(temp == null){//表示第一次添加
first = node;//
last = node;//头结点都为null,那last节点肯定也为null,所以同时赋值给尾节点
}else{
temp.pre = node;//将原头结点的pre指针指向添加节点
node.next = temp;//将添加节点的next指针执行原头结点,
first = node;//将添加节点赋给头结点 ,2
}
size++;//链表长度+1;
}
对于以上代码,标记1和2的两行代码其实可以合并的。这里为了好判别,就区分开来了
那对于类型2,原理和类型1差不多,不做过多解释,代码,如下
public void addLastNode(Node node){
Node temp = last;//临时节点
if(temp == null){//第一次添加
first = node;
last = node;
}else{
temp.next = node;//将原尾节点next指针执行添加节点
node.pre = temp;//将添加节点的pre指针执行原尾节点
last = node;//将添加节点设为尾节点
}
size++;//链表长度+1
}
对于类型三,相比1和2,要稍微复杂一点,不过其实也差不多,将该种类型拟作类型2,无非就是后面多了节点,语言好像描述不太清楚,大家清楚那个意思就行,如下面这个逻辑
有链表a->b->c->d,(额!这个是双向链表,表达式没体现出来),闲杂要在b和c直接插入节点e,那么肯定是用一个临时变量来替换c节点,如f=b.next,以此来保证该节点不被丢失,千万不能直接b.next=e,这样会丢失c后面的节点。之后就基本和类型2一样,最后再做一个e.next = f,f,pre = e,保证节点的通畅性。代码如下
//preNode代表要在该节点后插入node节点
public void add(Node preNode,Node node){
//这里不作校验,(本来是要做些preNode是不是不·存在或啥的校验)
Node nextNode = preNode.next;
//下面这两行代码是用来preNode和node节点的连通性
preNode.next = node;
node.pre = preNode; //这两行代码是保证node节点和nextNode节点的连通性
node.next = nextNode;
nextNode.pre = node; size++;
}
2.2、删除
那对于链表的删除操作呢,也可以类似增加一样,把它分成三类
1、删除原有的头结点,并返回删除节点值。
2、删除原有的尾节点,并返回删除节点值。
3、删除头结点和尾节点之间的某一个节点值。
原理和增加类似,不过多叙述,直接上代码
//删除头结点
public int deleteFirstNode(){
Node temp = first;
int oldVal = temp.val;
Node next = temp.next;
if(temp == null){//说明该链表没有节点
throw new RuntimeException("the class do not have head node");
}
first = next;
first.pre = null;
if(next == null){//若条件满足,则表示链表只有一个节点,即first==last为true;
last = null;
}else{
temp = null;
}
size--;
return oldVal;
} //删除尾节点
public int deleteLastNode(){
Node temp = last;
int oldVal = last.val;
Node pre = temp.pre;
if(temp == null){//说明该链表没有节点
throw new RuntimeException("the class do not have last node");
}
last = pre;//把原尾节点的前一个节点作为尾节点
if(pre == null){//只有一个节点
first = null;
}else{
temp = null;
}
size--;
return oldVal;
} //删除头结点和尾节点之间的某个节点,pre为node节点的前一个节点
//这里也不考虑一些特殊情况,也就是删除节点一定在两节点之间
public int delete(Node pre,Node node){
int oldVal = node.val;
Node next = node.next;
//构建node前后节点之间的连通性
pre.next = next;
next.pre = pre; node = null;
return oldVal;
}
2.3、修改
这个操作,很简单,找到该节点,将该节点值设为新值即可,寻找过程不像数组那样可以直接定位下标,这个寻找过程要做链表的遍历操作,代码如下
1 //true代表设值成功,false为设值失败
public boolean set(int oldVal,int newVal){
Node temp = first;
while(temp != null){
if(temp.val == oldVal){
temp.val = newVal;
return true;
}
temp = temp.next;
}
return false;
}
2.4、查找
查找和修改类似,只是少了设值这一操作,代码如下
//返回查找的节点
public Node find(int val){
Node temp = first;
while(temp != null){
if(temp.val == val){
return temp;
}
temp = temp.next;
}
return null;
}
其实细心的可以发现,要是相同值怎么办,说实话,在这里只会查找到距离头结点最近的节点,若是用了泛型,则可以对泛型里的类型重写hash和equals方法来尽量保证唯一性。
--------------------------------------------------------------------------------------------------------------------分界线-------------------------------------------------------------------------------------------------------------------------------------------------------------
上面叙述了一大堆关于自己实现双向链表的操作,那下面来看看jdk源码怎么实现的。
三、源码分析
关于源码分析,对于和前面设计类似的原理,避免啰里啰嗦,就一笔带过
3.1、增加
关于LinkedList的增加方法,有多个增加
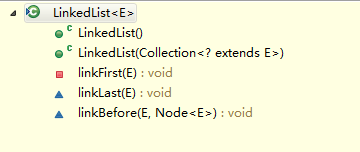

如左图,第一个和第二个是该类的构造函数,后面三个方法的作用域是private、protected、protected,作用分别为,
1、在头结点前增加节点
代码也很比较简洁,和之前设计的代码类似,不过多叙述,原理类似,至于modCount的作用,请翻阅之前的一篇博客集合之ArrayList的源码分析
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
2、在尾节点后增加节点
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
3、在头结点和尾节点之间添加节点
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
至于右图,是该类暴露给其他类中使用的。但最后都调用了上述三个方法之一来完成增加操作
经常使用的add(E)方法是默认添加在尾节点后的,
对于add(int,E)方法要注意一下,按照我们正常猜想,先是直接遍历该链表,找到某个节点,在该节点之后插入新节点,但是!!!,这里并不是这样的,它是类似数组那样直接在某个位置插入,别慌,先来贴下代码
public void add(int index, E element) {
checkPositionIndex(index);//检查index的正确性
if (index == size)//即在尾节点后插入
linkLast(element);
else
linkBefore(element, node(index));//注意这里的node(int)方法
}
11 Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
可以看到node方法里的操作,相比之前直接从头结点遍历链表的效率要高一点,有点类似折半查找,找到对应的节点,之后操作类似
3.2、删除
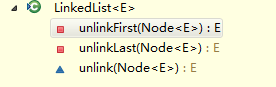

和增加方法一样,左图的三个删除方法是核心,右边的删除是暴露给其他方法中使用的,原理和前面说的类似,其中右图最后两个方法是怕有两个相同的obj,所以分了下类,从头结点开始找,和从尾节点开始找,找到了即删除。
其中remove()默认的也是移除头节点
3.3、修改

该类只有这一个方法,
其中也是先利用node方法查找index对应的节点,然后设值。并返回
3.4、查询
其中get(int)也是利用了node方法来查找对应的node节点
3.5、小结
对于LinkedList的其他方法,这里不作介绍,我们平时用该类也是围绕着增删改查来用,所以这里只介绍这四类。
4、和ArrayList的比较
一、它们的数据结构不一样,ArrayList的结构是数组,LinkedList的结构是链表,所有它们的内存地址排序不一样,一个是连续的,一个非连续
二、理论上,ArrayList的长度最大为Integer.MAX_VALUE,而链表的长度理论上无上限
三、ArrayList的增删慢,查询快,LinkedList的增删快,查询慢,两者恰好相反
四、两者都可以添加null元素,且都可以添加相同元素
五、两者都有线程安全性问题
5、最后
对于该类,我认为只需要了解它内部的增删改查原理,它的数据结构,它和ArrayList的区别即可。
若有不足或错误之处,还望诸位指正
集合之LinkedList源码分析的更多相关文章
- Java集合之LinkedList源码分析
概述 LinkedLIst和ArrayLIst一样, 都实现了List接口, 但其内部的数据结构不同, LinkedList是基于链表实现的(从名字也能看出来), 随机访问效率要比ArrayList差 ...
- 死磕 java集合之LinkedList源码分析
问题 (1)LinkedList只是一个List吗? (2)LinkedList还有其它什么特性吗? (3)LinkedList为啥经常拿出来跟ArrayList比较? (4)我为什么把LinkedL ...
- Java8集合框架——LinkedList源码分析
java.util.LinkedList 本文的主要目录结构: 一.LinkedList的特点及与ArrayList的比较 二.LinkedList的内部实现 三.LinkedList添加元素 四.L ...
- Java 集合之LinkedList源码分析
1.介绍 链表是数据结构中一种很重要的数据结构,一个链表含有一个或者多个节点,每个节点处理保存自己的信息之外还需要保存上一个节点以及下一个节点的指针信息.通过链表的表头就可以访问整个链表的信息.Jav ...
- Java集合干货——LinkedList源码分析
前言 在上篇文章中我们对ArrayList对了详细的分析,今天我们来说一说LinkedList.他们之间有什么区别呢?最大的区别就是底层数据结构的实现不一样,ArrayList是数组实现的(具体看上一 ...
- java集合系列之LinkedList源码分析
java集合系列之LinkedList源码分析 LinkedList数据结构简介 LinkedList底层是通过双端双向链表实现的,其基本数据结构如下,每一个节点类为Node对象,每个Node节点包含 ...
- Java入门系列之集合LinkedList源码分析(九)
前言 上一节我们手写实现了单链表和双链表,本节我们来看看源码是如何实现的并且对比手动实现有哪些可优化的地方. LinkedList源码分析 通过上一节我们对双链表原理的讲解,同时我们对照如下图也可知道 ...
- ArrayList 和 LinkedList 源码分析
List 表示的就是线性表,是具有相同特性的数据元素的有限序列.它主要有两种存储结构,顺序存储和链式存储,分别对应着 ArrayList 和 LinkedList 的实现,接下来以 jdk7 代码为例 ...
- 死磕 java集合之DelayQueue源码分析
问题 (1)DelayQueue是阻塞队列吗? (2)DelayQueue的实现方式? (3)DelayQueue主要用于什么场景? 简介 DelayQueue是java并发包下的延时阻塞队列,常用于 ...
随机推荐
- Leetcode 5——Median of Two Sorted Arrays
题目: There are two sorted arrays nums1 and nums2 of size m and n respectively. Find the median of the ...
- C语言第八次作业
一.PTA实验作业 题目1:统计一行文本的单词个数 1.本题PTA提交列表 2.设计思路 // 一个非空格和一个空格代表一个单词 char str[1000]: 存放一行文本 定义 I,j=0:用作循 ...
- 2017-2018-1 1623 bug终结者 冲刺003
bug终结者 冲刺003 by 王旌含 今日任务:优化界面布局,提供图片素材 需求 app图标.主界面图.主界面中按钮图:选择关卡图.关卡按键图:游戏中的小人.箱子.地板.墙.目的地:方向按钮:重置按 ...
- day9
Alpha冲刺Day9 一:站立式会议 今日安排: 经过为期5天的冲刺,基本完成企业人员模块的开发.因第三方机构与企业存在委托的关系.第三方人员对于风险的自查.风险列表的展示以及自查风险的统计展示(包 ...
- iOS极光推送SDK的使用流程
一.极光推送简介 极光推送是一个端到端的推送服务,使得服务器端消息能够及时地推送到终端用户手机上,整合了iOS.Android和WP平台的统一推送服务.使用起来方便简单,已于集成,解决了原生远程推送繁 ...
- Huginn实现自动通过slack推送豆瓣高分电影
博客搬迁至https://blog.wangjiegulu.com RSS订阅:https://blog.wangjiegulu.com/feed.xml 原文链接:https://blog.wang ...
- 关于 Ubuntu Linux 16.04中文版的 root 权限及桌面登录问题
新接触 Ubuntu 的朋友大多会因为安装中没有提示设置 root 密码而不太清楚是什么原因. 起初 Ubuntu 团队希望安装尽可能的简单. 不使用 root , 在安装期间的两个用户交互步骤可以省 ...
- SQL SERVER 游标的使用
首先,关于什么是游标大家可以看看这篇文章,介绍得非常详细!! SQL Server基础之游标 下面是我自己的应用场景-- 有个需求,需要把数据库表里面某一个字段的值设为随机不重复的值. 表是这样的: ...
- Hey,man,are you ok? -- 关于心跳、故障监测、lease机制
电话之于短信.微信的一个很大的不同点在于,前者更加及时,有更快速直接的反馈:而后面两个虽然称之为instant message,但经常时发出去了就得等对方回复,等多久是不确定的.打电话能明确知道对方在 ...
- AJAX使用说明书
AJAX简介 什么是AJAX AJAX(Asynchronous Javascript And XML)翻译成中文就是“异步Javascript和XML”.即使用Javascript语言与服务器进行异 ...