HDFS- High Availability
NameNode High Availability
Background
Hadoop2.0.0之前,NameNode存在单点失败(single point of failure (SPOF) )问题(1、NameNode所在的机器挂了;2、NameNode所在的机器需要硬件或者软件上的更新维护)。
新的NameNode需要(1)将namespace image加载到内存(2)replay editlog(3)从datanodes接收到足够的block报告从而离开安全模式;才能重新开始服务。在包含大量文件和Blocks的大的集群中,namenode的冷启动可能需要30min或更久。
Architecture
NameNode HA包含两个NameNode,在任意一个时刻,只有一个NameNode是的状态是Active,另一个是NameNode的状态是Standby,此外还包含ZooKeeper Failover Controller(ZKFC)、ZooKeeper以及共享编辑日志(share edit log)。 Active NameNode负责所有客户端对集群的操作, Standby NameNode作为slave,维护状态信息以便在提供快速的故障转移。
实现HA的流程
(1)集群启动后,一个NameNode处于Active的状态,提供服务,处理客户端和DataNodes的请求,并把修改写到edit log,然后将edit log写到本地和共享编辑日志(NFS、QJM等)。
【共享编辑日志分两种,
1:如果是NFS,那么主、从NameNode访问NFS的一个目录或者共享存储设备,Active Node对namespace的修改记录到edit log中,然后将edit log存储到共享目录中。Standby NameNode将共享目录中的edit log 写到自己的namespace
2:如果是QJM,那么主、从NameNode与一组单独的称为Journal Nodes(JNs)的守护线程进行通信,Active Node将修改记录到大多数(> (N / 2) + 1,N是Journal Nodes的数量),Standby NameNode能够从JNs读到修改并写到自己的namespace中
】
(2)另外一个NameNode处于standby状态,它启动时加载Namespace Image文件,然后周期性地将共享编辑日志写到自己namespace,从而保持与Active NameNode的状态同步。在发生故障转移时,Standby节点需要确保自己已经从共享编辑日志读到了所有的edit log之后,才会变成Active节点。这保证了namespace状态的完全同步。
(3)为了实现Standby NameNode在Active NameNode失败之后能够快速提供服务,每个DataNode需要同时向两个NameNode发送块的位置信息和心跳【块报告(block report)】,因为NameNode启动最费时的工作就是处理所有DataNodes的块报告。为了实现热备,增加ZKFC和ZooKeeper,通过ZK选择主节点,Failover Controller通过RPC让NameNode转换为主或从。
(4)当Active NameNode失败时,Standby NameNode可以很快地接管,因为在Standby NameNode的内存中有最新的状态信息(1)最新的edit log(2)最新的block mapping
高可用的共享存储的两种选择:NFS和QJM
quorum journal manager(QJM)是HDFS专门的实现,唯一的目的就是提供高可用的edit log,是大多数HDFS的推荐选择。
QJM的工作过程:QJM运行一组journal nodes,每个edit必须被写入到majority的journal nodes中。通常,journal nodes的数量是3(至少是3个),因此每个edit必须被写入到至少两个journal nodes,允许一个journal nodes失败。【与ZooKeeper相似,但是QJM不是依赖ZooKeeper实现的】
使用 Fencing(隔离)来防止"split-brain"(脑裂)
Why Fencing?
slow network or a network partition可以触发故障转移,即使之前的Active NameNode仍让在正常运转并且认为它自己仍然是Active NameNode,这时HA就需要确保阻止这样的NameNode继续运行。
两种隔离
(1)通过隔离保证在同一时刻主NameNoel和从NameNode只有一个能够写 共享编辑日志
(2)DataNode隔离:对客户端进行隔离,要确保只有一个NameNode能够响应客户端的请求
对于HA集群来说,同一时刻只能有一个Active NameNode,否则namespace的状态很快就会发散成两个,造成数据丢失以及其他不正确的结果,即"split-brain"。为了防止这种情况发生,对于共享存储必须配置隔离(fencing)方法。在故障转移期间,如果不能判定之前的Active 节点放弃了他的Active状态,隔离处理负责切断切断之前的Active节点对共享编辑存储的访问,这就防止了之前Active节点对namespace的进一步编辑,从而使得新的Active节点能够安全地进行故障转移。(即一旦主NameNode失败,那么共享存储需要立即进行隔离,确保只有一个NameNode能够命令DataNodes。这样做之后,还需要对客户端进行隔离,要确保只有一个NameNode能够响应客户端的请求。让访问从节点的客户端直接失败,然后通过若干次的失败后尝试连接新的NameNode,对客户端的影响是增加一些重试时间,但对应用来说基本感觉不到。)
why QJM recommended?
QJM在同一个时刻只允许一个NameNode写edit log;然而,之前的Active NameNode仍有可能为客户端的旧的读请求服务,此时可以设置SSH fencing命令来杀死NameNode的进程。
由于NFS不可能在同一个时刻只允许一个NameNode向它写数据,因此NFS需要更强的fencing方法,包括:1、revoking the namenode’s access to the shared storage directory (typically by using a vendor-specific NFS command);2、disabling its network port via a remote management command;3、STONITH, or “shoot the other node in the head,” which uses a specialized power distribution unit to forcibly power down the host machine.
Failover Controller
从Active NameNode到Standby NameNode的转换通过Failover Controller实现。Hadoop的FC的默认实现是基于ZooKeeper的,从而确保只有一个Active NameNode。Failover Controller的作用是监控NameNode、操作系统、硬件的健康状态,如果出现NameNode的失败,则进行故障转移。
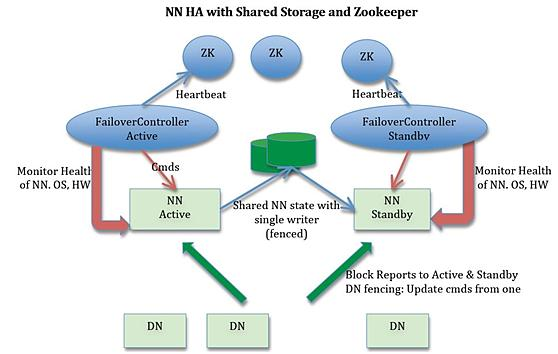
NOTE:HA集群中的Standby NameNode同时为namespace的状态执行检查点(HA上运行Secondary NameNode, CheckpointNode, or BackupNode是错误的)
参考:
(1)《Hadoop The Definitive Guide》
(2)http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-hdfs/HdfsUserGuide.html
HDFS- High Availability的更多相关文章
- HDFS Federation与HDFS High Availability详解
HDFS Federation NameNode在内存中保存文件系统中每个文件和每个数据块的引用关系,这意味着对于一个拥有大量文件的超大集群来说,内存将成为限制系统横向扩展的瓶颈.在2.0发行版本系列 ...
- [HDFS Manual] CH4 HDFS High Availability Using the Quorum Journal Manager
HDFS High Availability Using the Quorum Journal Manager HDFS High Availability Using the Quorum Jour ...
- Configuring HDFS High Availability
Configuring HDFS High Availability 原文请訪问 http://blog.csdn.net/ashic/article/details/47024617,突袭新闻小灵儿 ...
- HDFS High Availability(HA)高可用配置
高可用性(英语:high availability,缩写为 HA) IT术语,指系统无中断地执行其功能的能力,代表系统的可用性程度.是进行系统设计时的准则之一. 高可用性系统意味着系统服务可以更长时间 ...
- HDFS High Availability Using the Quorum Journal Manager
http://hadoop.apache.org/docs/r2.9.0/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.htm ...
- hadoop2.x HDFS HA linux环境搭建
HDFS High Availability Using the Quorum Journal Manager 准备3台机器可以更多 NN DN ZK ZKFC JN RM DM n ...
- hadoop 的HDFS 的 standby namenode无法启动事故处理
standby namenode无法启动 现象:线上使用的2.5.0-cdh5.3.2版本Hadoop,开启了了NameNode HA,HA采用QJM方式.hadoop的集群的namenode的sta ...
- HDFS NameNode HA 部署文档
简介: HDFS High Availability Using the Quorum Journal Manager Hadoop 2.x 中,HDFS 组件有三个角色:NameNode.DataN ...
- 第6章 HDFS HA配置
目录 6.1 hdfs-site.xml文件配置 6.2 core-site.xml文件配置 6.3 启动与测试 6.4 结合ZooKeeper进行自动故障转移 在Hadoop 2.0.0之前,一个H ...
- hadoop权威指南(第四版)要点翻译(4)——Chapter 3. The HDFS(1-4)
Filesystems that manage the storage across a network of machines are called distributed filesystems. ...
随机推荐
- 教你怎么样在大陆直接使用google搜索
一.环境准备 我们需要一个nginx的模块来进行设置,ngx_http_google_filter_module.前提我们是有一个海外的VPS,并且可以访问谷歌,我的VPS是亿速云香港的. 首先先感受 ...
- zabbix自定义key监控memcache状态及其他服务进程
一.在客户端 1.到/usr/loca/zabbix/conf/zabbix_agentd.conf里添加 UserParameter=memcached_stats[*],(echo ...
- Tram
Tram 题目大意:给你一个图,这个图上有n点和边.点上有开关,开关开始指向一条道路,拨动开关可以使开关指向由开关出发的任意一条路径,读入,a,b,求,至少要拨动几次才能从a点走到b点. 注释:n&l ...
- bash下常用快捷键
Ctrl-A 相当于HOME键,用于将光标定位到本行最前面Ctrl-E 相当于End键,即将光标移动到本行末尾Ctrl-B 相当于左箭头键,用于将光标向左移动一格Ctrl-F 相当于右箭头键,用于将光 ...
- 2017-2018-1 Java演绎法 第一周 作业
团队学习:<构建之法> [团队成员]: 学号 姓名 负责工作 20162315 马军 日常统计,项目部分代码 20162316 刘诚昊 项目部分代码,代码质量测试 20162317 袁逸灏 ...
- 项目Beta冲刺第二天
1.昨天的困难,今天解决的进度,以及明天要做的事情 昨天的困难:昨天主要是在确认需求方面花了一些时间,后来终于确认了企业自查风险模块的需求问题 今天解决的进度:根据昨天确认下来的需求,我们基本上完成了 ...
- B-dya6
1.昨天的困难,今天解决的进度,以及明天要做的事情 昨天的困难:在导入导出方面遇到了困难,导出的文件不能直接导入. 今天解决的进度:完成了登录页面的背景设计,并再次测试了整个系统的功能. 明天要做的事 ...
- 201621123062《java程序设计》第七周作业总结
1. 本周学习总结 1.1 思维导图:Java图形界面总结 1.2 可选:使用常规方法总结其他上课内容. 1.布局管理器的具体使用方法 2.事件处理模型及其代码的编写 3.Swing中的常用组件 4. ...
- django搭建web (三) admin.py -- 待续
demo 关于模型myQuestion,myAnswer将在后述博客提及 # -*- coding: utf-8 -*- from __future__ import unicode_literals ...
- SQL的介绍及MySQL的安装
基础篇 - SQL 介绍及 MySQL 安装 SQL的介绍及MySQL的安装 课程介绍 本课程为实验楼提供的 MySQL 实验教程,所有的步骤都在实验楼在线实验环境中完成, ...