GraphQL 入门介绍
写在前面
GraphQL是一种新的API标准,它提供了一种更高效、强大和灵活的数据提供方式。它是由Facebook开发和开源,目前由来自世界各地的大公司和个人维护。GraphQL本质上是一种基于api的查询语言,现在大多数应用程序都需要从服务器中获取数据,这些数据存储可能存储在数据库中,API的职责是提供与应用程序需求相匹配的存储数据的接口。有的人经常把GraphQL和数据库技术相混淆,这是一个误解,GraphQL是api的查询语言,而不是数据库。从这个意义上说,它是数据库无关的,而且可以在使用API的任何环境中有效使用,我们可以理解为GraphQL是基于API之上的一层封装,目的是为了更好,更灵活的适用于业务的需求变化。
GraphQL出现的历史背景
当提起API设计的时候,大家通常会想到SOAP,RESTful等设计方式,从2000年RESTful的理论被提出的时候,在业界引起了很大反响,因为这种设计理念更易于用户的使用,所以便很快的被大家所接受。我们知道REST是一种从服务器公开数据的流行方式。当REST的概念被提及出来时,客户端应用程序对数据的需求相对简单,而开发的速度并没有达到今天的水平。因此REST对于许多应用程序来说是非常适合的。然而在业务越发复杂,客户对系统的扩展性有了更高的要求时,API环境发生了巨大的变化。特别是从下面三个方面在挑战api设计的方式:
1.移动端用户的爆发式增长需要更高效的数据加载
Facebook开发GraphQL的最初原因是移动用户的增加、低功耗设备和松散的网络。GraphQL最小化了需要网络传输的数据量,从而极大地改善了在这些条件下运行的应用程序。
2.各种不同的前端框架和平台
前端框架和平台运行客户端应用程序的异构环境使得我们在构建和维护一个符合所有需求的API变得困难,使用GraphQL每个客户机都可以精确地访问它需要的数据。
3.在不同前端框架,不同平台下想要加快产品快速开发变的越来越难
持续部署已经成为许多公司的标准,快速的迭代和频繁的产品更新是必不可少的。对于REST api,服务器公开数据的方式常常需要修改,以满足客户端的特定需求和设计更改。这阻碍了快速开发实践和产品迭代。
GraphQL的出现不仅仅是针对开发人员的,Facebook在2012年开始在其native mobile apps中使用GraphQL。但有趣的是GraphQL大部分都是在web技术的背景下使用的,并且在native mobile 领域中只得到很少的支持。 Facebook第一次公开谈论GraphQL是在宣布开源计划后不久的2015年React峰会的时候。因为Facebook总是在React的背景下谈GraphQL,所以对于没有React经验的开发人员来说,要理解GraphQL并不是一种仅限于React使用的技术可能还需要一段时间。即便是在这样的背景下诞生的GraphQL依然是一个快速增长的社区 ,事实上GraphQL是一种技术,可以在客户端与API通信的任何地方使用。有趣的是Netflix和Coursera等其他公司都在研究类似的想法以提高API的交互效率。Coursera设想了一种类似的技术,可以让客户指定其数据需求,而Netflix甚至将其解决方案称为Falcor。在GraphQL被开源之后,Coursera完全停止了他们在Falcor上的努力,并转到了GraphQL的学习上。目前已经有很多的公司在使用GraphQL(https://graphql.org/users/)。

GraphQL和RESTful的区别
前面提到GraphQL可以理解为基于RESTful的一种封装,目的在于构建使Client更加易用的服务,可以说GraphQL是更好的RESTful设计。在过去的十多年中,REST已经成为设计web api的标准(虽然只是一个模糊的标准)。它提供了一些很棒的想法,比如无状态服务器和结构化的资源访问。然而REST api表现得过于僵化,无法跟上访问它们的客户的快速变化的需求。 GraphQL的开发是为了应付更多的灵活性和效率,它解决了与REST api交互时开发人员所经历的许多缺点和低效之处。 为了说明在从API获取数据时REST和GraphQL之间的主要区别,让我们考虑一个简单的示例场景:在blog应用程序中,应用程序需要显示特定用户的文章的标题。同一屏幕还显示该用户最后3个关注者的名称。REST和GraphQL如何解决这种情况?
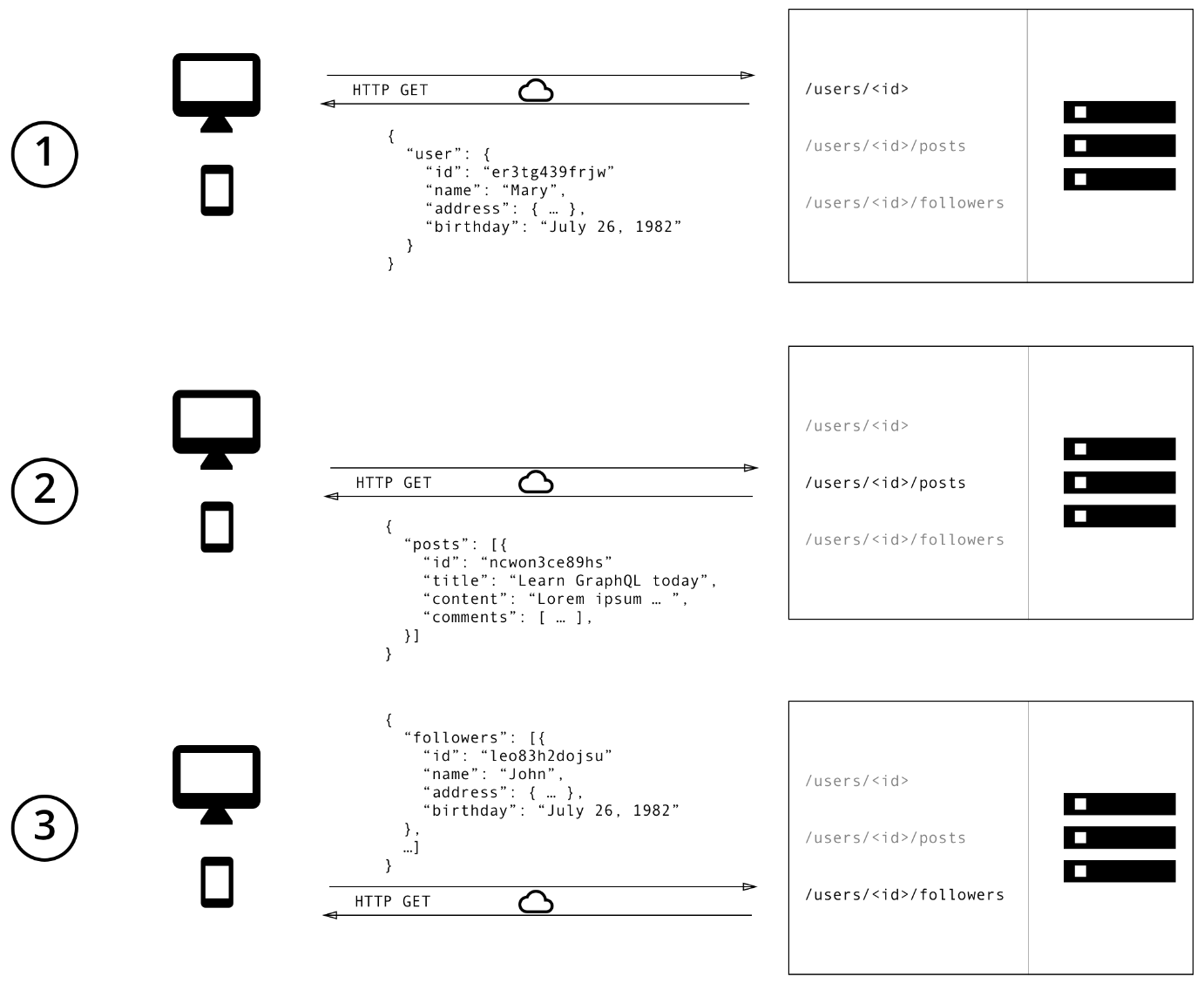
使用REST API来现实时,我们通常可以通过访问多次请求来收集数据。比如在这个示例中,我们可以通过下面的三步来实现:
1. 通过 /user/<id>获取初始用户数据
2. 通过/user/<id>/posts 返回用户的所有帖子
3. 请求/user/<id>/followers,返回每个用户的关注者列表
调用关系如下图所示:
如果用GraphQL的话,我们只需要一次请求就可以完成上述的需求
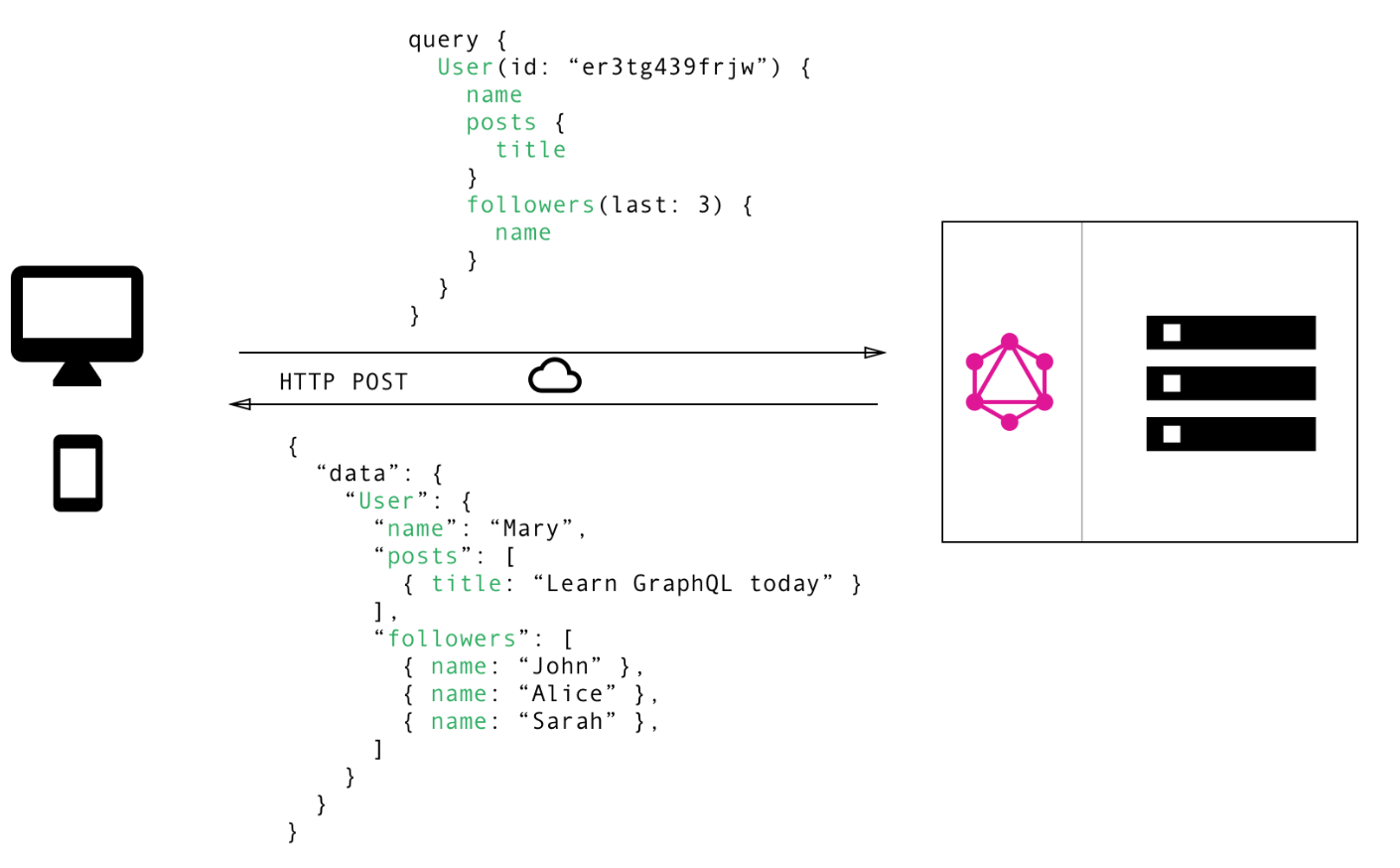
在GraphQL的世界里我们不用多取数据,也不用担心数据取少了,我们只需要按需获取即可。
REST最常见的问题之一是API的返回数据过多或者过少,这是因为客户端下载数据的唯一方法是通过访问返回固定数据结构的endpoint,这就会导致我们设计API非常困难,因为它既要能够为客户提供精确的数据需求,又需要满足不同调用者的需求,这本身就是相互矛盾的。GraphQL的发明者Lee Byron提出了一个很重要的概念: “用图形来思考,而不是endpoint”
通过上述直观展示我们可以得出一下几点:
1. 获取了许多多余的数据
通常情况下我们在调用一个通用API接口时,客户端获取的信息比应用程序中实际需要的要多。例如UI需要显示一个用户列表,而实际上只需要使用他们的名字。在REST API中通常会调用 /user 这个endpoint,并接收一个带有用户数据的JSON数组。但是这个响应可能包含更多关于返回的用户的信息,例如他们的生日或地址,而这些信息对客户来说是无用的,因为它只需要显示用户的名字。
2. 获取的数据少于Client所需要的数据
一般来说数据获取不足意味着某个特定的endpoint 没有提供客户端需要的足够信息,客户端将需要额外的请求来获取它所需要的一切。这可能会升级到客户端需要首先获取列表信息,然后需要对单条数据添加一个额外的请求以获取其他所需的数据,例如考虑其他Client 也需要显示每个用户的最后三个关注者,该API提供了额外的endpoint /user/<userid>/followers,为了能够显示所需的信息,Client 必须向 /users endpoint 发出一个请求,然后点击/user/<user-id>/follwers endpoint 来获取单个用户的follwers信息。
3. 前端的快速产品迭代对API有很大的挑战
REST api的一个常见模式是根据您在应用程序内部的展现逻辑来构造endpoint,这很方便,因为它允许客户端通过访问相应的endpoint获取特定视图的所有所需信息。 这种方法的主要缺点是它不允许前端的快速迭代。对于UI所做的每一个更改,现在都存在比以前更多(或更少)的数据的高风险。因此,需要对后端进行调整,以满足新的数据需求,这会降低生产力并显著降低将用户反馈集成到产品中的能力。 使用GraphQL这个问题就解决了。由于GraphQL的灵活性,无需在服务器上额外工作就可以在客户端上进行更改。由于客户端可以指定准确的数据需求,所以当前端的设计和数据需求发生变化时,并不需要后端API做出任何的修改就可以满足展现层的变化。
4. Schema和类型系统的好处
GraphQL使用强大的Type System来定义API的功能。所有在API中公开的类型都是使用GraphQL schema Definition Language (SDL)在模式中编写的。该模式充当客户端和服务器之间的契约,以定义客户机如何访问数据。 一旦定义了模式,在前端和后端工作的团队就可以在没有进一步通信的情况下完成工作,因为他们都知道通过网络发送的数据的确切结构。 前端团队可以通过mock所需的数据结构来轻松测试他们的应用程序。一旦后端API实现完成,就可以对客户端应用程序进行切换来调用实际的API获取数据,这也可以使得我们实现更好的客户端和服务端的分离。
写在最后
我们可以看出GraphQL的出现可以使得我们后端API具有更大的灵活性以及扩展性以满足不同client对数据的需要,这大大丰富了API的数据提供的能力。
GraphQL 入门介绍的更多相关文章
- C# BackgroundWorker组件学习入门介绍
C# BackgroundWorker组件学习入门介绍 一个程序中需要进行大量的运算,并且需要在运算过程中支持用户一定的交互,为了获得更好的用户体验,使用BackgroundWorker来完成这一功能 ...
- 初识Hadoop入门介绍
初识hadoop入门介绍 Hadoop一直是我想学习的技术,正巧最近项目组要做电子商城,我就开始研究Hadoop,虽然最后鉴定Hadoop不适用我们的项目,但是我会继续研究下去,技多不压身. < ...
- [Python爬虫] 在Windows下安装PhantomJS和CasperJS及入门介绍(上)
最近在使用Python爬取网页内容时,总是遇到JS临时加载.动态获取网页信息的困难.例如爬取CSDN下载资源评论.搜狐图片中的“原图”等,此时尝试学习Phantomjs和CasperJS来解决这个问题 ...
- [Python爬虫] scrapy爬虫系列 <一>.安装及入门介绍
前面介绍了很多Selenium基于自动测试的Python爬虫程序,主要利用它的xpath语句,通过分析网页DOM树结构进行爬取内容,同时可以结合Phantomjs模拟浏览器进行鼠标或键盘操作.但是,更 ...
- JavaScript入门介绍(二)
JavaScript入门介绍 [函数] 函数function 是Javascript的基础模块单元,用于代码的复用.信息影藏和组合调用. function a(){} 函数对象Function Lit ...
- JavaScript入门介绍(一)
JavaScript入门介绍 [经常使用的调试工具][w3school.com.cn在线编辑] [Chrome浏览器 开发调试工具]按F121.代码后台输出调试:console.log("t ...
- .NET 4 并行(多核)编程系列之一入门介绍
.NET 4 并行(多核)编程系列之一入门介绍 本系列文章将会对.NET 4中的并行编程技术(也称之为多核编程技术)以及应用作全面的介绍. 本篇文章的议题如下: 1. 并行编程和多线程编程的区别. ...
- .NET读写Excel工具Spire.Xls使用(1)入门介绍
原文:[原创].NET读写Excel工具Spire.Xls使用(1)入门介绍 在.NET平台,操作Excel文件是一个非常常用的需求,目前比较常规的方法有以下几种: 1.Office Com组件的方式 ...
- Linux入门介绍
Linux入门介绍 一.Linux 初步介绍 Linux的优点 免费的,开源的 支持多线程,多用户 安全性好 对内存和文件管理优越 系统稳定 消耗资源少 Linux的缺点 操作相对困难 一些专业软件以 ...
随机推荐
- 温故而后知新——对ado.net中常用对象的一些解释
在使用ado.net连接数据库获取数据,一般的步骤是: 1.设置好web.config //用来设置服务器数据库的地址以及登录名密码 2.创建Connection对象 //用来创建访问数据 ...
- Day15 jss整体结构梳理
JS DOM--- 两个步骤: 1 查找标签 (1)直接查找 document.getElementById("idname") // dom对象 document.getElem ...
- C++ 进制转换 十进制十六进制八进制二进制相互转换
思路: 下面我把相互转换的所有类型都写出来了.实际上都是通过十进制中转的,这样比较简单,写出X进制转成十进制和从十进制转成X进制的两份代码直接拷贝就完成了剩余的部分.哦,对,自己封装了一个charTo ...
- nginx安装配置+集群tomcat:Centos和windows环境
版本:nginx-1.8.0.tar.gz 官网:http://nginx.org/en/download.html 版本:apache-tomcat-6.0.44.tar.gz 官 ...
- 架构之高可用性(HA)集群(Keepalived)
Keepalived简介 Keepalived是Linux下一个轻量级别的高可用解决方案.高可用(High Avalilability,HA),其实两种不同的含义:广义来讲,是指整个系统的高可用行,狭 ...
- Hive中Join的原理和机制
转自:http://lxw1234.com/archives/2015/06/313.htm 笼统的说,Hive中的Join可分为Common Join(Reduce阶段完成join)和Map Joi ...
- ImportError: numpy.core.multiarray failed to import
1. ImportError: numpy.core.multiarray failed to import pip install -U numpy http://stackoverflow.com ...
- cnblog 模板 SimpleMemory 个性化设置代码备份
/页面顶部作者名/ blogTitle h1 { font-size: 50px; margin-top: 0px; } /页面简介/ blogTitle h2 { letter-spacing: 1 ...
- 第七章 mysql 事务索引以及触发器,视图等等,很重要又难一点点的部分
[索引] 帮助快速查询 MyISAM ,InnoDB支持btree索引 Memory 支持 btree和hash索引 存储引擎支持 每个表至少16个索引 总索引长度至少256字节 创建索引的优 ...
- PAT1100:Mars Numbers
1100. Mars Numbers (20) 时间限制 400 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 CHEN, Yue People o ...