Cypher查询语言--Neo4j 之高级篇 (六)
目录
- 排序Order by
- 通过节点属性排序节点
- 通过多节点属性排序节点
- 倒序排列节点
- 空值排序
- Skip
- 跳过前三个
- 返回中间两个
- Limit
- 返回第一部分
- 函数Functions
- 判断
- All
- Any
- None
- Single
- Scalar函数
- Length
- Type
- Id
- Coalesce
- Iterable函数
- Nodes
- Relationships
- Extract
排序(Order by)
输出结果排序可以使用order by 子句。注意,不能使用节点或者关系排序,仅仅只针对其属性有效。
图:

通过节点属性排序节点
查询:
START n=node(3,1,2)
RETURN n
ORDER BY n.name
结果:

通过多节点属性排序节点
在order by子句中可以通过多个属性来排序每个标识符。Cypher首先将通过第一个标识符排序,如果第一个标识符或属性相等,则在order by中检查下一个属性,依次类推。
查询:
START n=node(3,1,2)
RETURN n
ORDER BY n.age, n.name
首先通过age排序,然后再通过name排序。
结果:

倒序排列节点
可以在标识符后添加desc或asc来进行倒序排列或顺序排列。
查询:
START n=node(3,1,2)
RETURN n
ORDER BY n.name DESC
结果:

空值排序
当排列结果集时,在顺序排列中null将永远放在最后,而在倒序排列中放最前面。
查询:
START n=node(3,1,2)
RETURN n.length?, n
ORDER BY n.length?
结果:

Skip
Skip允许返回总结果集中的一个子集。此不保证排序,除非使用了order by’子句。
图:

跳过前三个
返回结果中一个子集,从第三个结果开始,语法如下:
查询:
START n=node(3, 4, 5, 1, 2)
RETURN n
ORDER BY n.name
SKIP 3
前三个节点将略过,最后两个节点将被返回。
结果:

返回中间两个
查询:
START n=node(3, 4, 5, 1, 2)
RETURN n
ORDER BY n.name
SKIP 1
LIMIT 2
中间两个节点将被返回。
结果:

Limit
Limit允许返回结果集中的一个子集。
图:
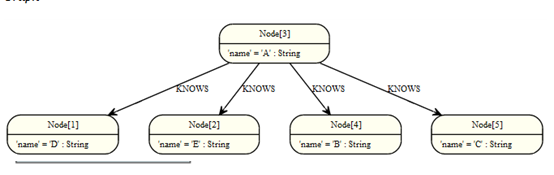
返回第一部分
查询:
START n=node(3, 4, 5, 1, 2)
RETURN n
LIMIT 3
结果:

函数(Functions)
在Cypher中有一组函数,可分为三类不同类型:判断、标量函数和聚类函数。
图:
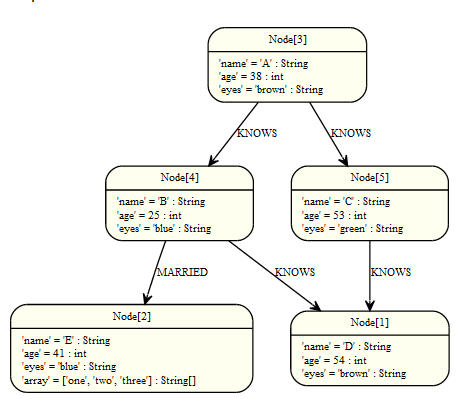
判断
判断为boolean函数,对给出的输入集合做判断并返回true或者false。常用在where子句中过滤子集。
All
迭代测试集合中所有元素的判断。
语法:
All(标识符 in iterable where 判断)
参数:
Ø iterable :一个集合属性,或者可迭代的元素,或一个迭代函数。
Ø 标识符:可用于判断比较的标识符。
Ø 判断:一个测试所有迭代器中元素的判断。
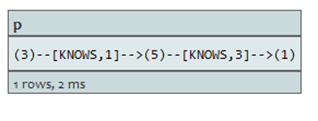
查询:
START a=node(3), b=node(1)
MATCH p=a-[*1..3]->b
WHERE all(x in nodes(p) WHERE x.age > 30)
RETURN p
过滤包含age〈30的节点的路径,返回符合条件路径中所有节点。
结果:
Any
语法:ANY(identifierin iterable WHERE predicate)
参数:
Ø Iterable(迭代器):一个集合属性,或者可迭代的元素,或一个迭代函数。
Ø Identifier(标识符):可用于判断比较的标识符。
Ø Predicate(判断):一个测试所有迭代器中元素的判断。
查询:
START a=node(2)
WHERE any(x in a.array WHERE x = "one")
RETURN a
结果:

None
在迭代器中没有元素判断将返回true。
语法:NONE(identifierin iterable WHERE predicate)
Ø Iterable(迭代器):一个集合属性,或者可迭代的元素,或一个迭代函数。
Ø Identifier(标识符):可用于判断比较的标识符。
Ø Predicate(判断):一个测试所有迭代器中元素的判断。
查询:
START n=node(3)
MATCH p=n-[*1..3]->b
WHERE NONE(x in nodes(p) WHERE x.age = 25)
RETURN p
结果:

Single
如果迭代器中仅有一个元素则返回true。
语法:SINGLE(identifierin iterable WHERE predicate)
参数:
Ø Iterable(迭代器):一个集合属性,或者可迭代的元素,或一个迭代函数。
Ø Identifier(标识符):可用于判断比较的标识符。
Ø Predicate(判断):一个测试所有迭代器中元素的判断。
查询:
START n=node(3)
MATCH p=n-->b
WHERE SINGLE(var in nodes(p) WHERE var.eyes = "blue")
RETURN p
结果:

Scalar函数
标量函数返回单个值。
Length
使用详细的length属性,返回或过滤路径的长度。
语法:LENGTH(iterable )
参数:
Ø Iterable(迭代器):一个集合属性,或者可迭代的元素,或一个迭代函数。
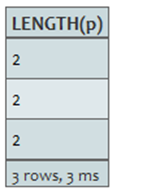
查询:
START a=node(3)
MATCH p=a-->b-->c
RETURN length(p)
返回路径的长度。
结果:
Type
返回关系类型的字符串值。
语法:TYPE(relationship )
参数:
Ø Relationship:一条关系。
查询:
START n=node(3)
MATCH (n)-[r]->()
RETURN type(r)
返回关系r的类型。
结果:

Id
返回关系或者节点的id
语法:ID(property-container )
参数:
Ø Property-container:一个节点或者一条关系。
查询:
START a=node(3, 4, 5)
RETURN ID(a)
返回这三个节点的id。
结果:

Coalesce
返回表达式中第一个非空值。
语法:COALESCE(expression [, expression]* )
参数:
Ø Expression:可能返回null的表达式。
查询:
START a=node(3)
RETURN coalesce(a.hairColour?,a.eyes?)
结果:

Iterable函数
迭代器函数返回一个事物的迭代器---在路径中的节点等等。
Nodes
返回一个路径中的所有节点。
语法:NODES(path )
参数:
Ø Path:路径
查询:
START a=node(3), c=node(2)
MATCH p=a-->b-->c
RETURN NODES(p)
结果:

Relationships
返回一条路径中的所有关系。
语法:RELATIONSHIPS(path )
参数:
Ø Path:路径
查询:
START a=node(3), c=node(2)
MATCH p=a-->b-->c
RETURN RELATIONSHIPS(p)
结果:

Extract
可以使用extract单个属性,或从关系或节点集合迭代一个函数的值。将遍历迭代器中所有的节点并运行表达式返回结果。
语法:EXTRACT(identifier in iterable : expression )
Ø Iterable(迭代器):一个集合属性,或者可迭代的元素,或一个迭代函数。
Ø Identifier(标识符):闭包中表述内容的标识符,这决定哪个标识符将用到。
Ø expression(表达式):这个表达式将对于迭代器中每个值运行一次,并生成一个结果迭代器。
查询:
START a=node(3), b=node(4),c=node(1)
MATCH p=a-->b-->c
RETURN extract(n in nodes(p) : n.age)
返回路径中所有age属性值。
结果:

Cypher查询语言--Neo4j 之高级篇 (六)的更多相关文章
- Cypher查询语言--Neo4j 入门 (一)
目录 操作符 参数 标识符 注解 Start 通过id绑定点 通过id绑定关系 通过id绑定多个节点 所有节点 通过索引查询获取节点 通过索引查询获取关系 多个开始点 Cypher是一个描述性的图形 ...
- Cypher查询语言--Neo4j之聚合函数(五)
目录 聚合Aggregation 计数 计算节点数 分组计算关系类型 计算实体数 计算非空可以值数 求和sum 平均值avg 最大值max 最小值min 聚类COLLECT 相异DISTINCT 聚合 ...
- C# 扩展方法奇思妙用高级篇六:WinForm 控件选择器
在Web开发中,jQuery提供了功能异常强大的$选择器来帮助我们获取页面上的对象.但在WinForm中,.Net似乎没有这样一个使用起来比较方便的选择器.好在我们有扩展方法,可以很方便的打造一个. ...
- Cypher查询语言--Neo4j 综合(四)
目录 返回节点 返回关系 返回属性 带特殊字符的标识符 列的别名 可选属性 特别的结果 查询中的返回部分,返回途中定义的感兴趣的部分.可以为节点.关系或其上的属性. 图 返回节点 返回一个节点,在 ...
- Neo4j Cypher查询语言详解
Cypher介绍 "Cypher"是一个描述性的图形查询语言,允许不必编写图形结构的遍历代码对图形存储有表现力和效率的查询.Cypher还在继续发展和成熟,这也就意味着有可能会出现 ...
- ORM查询语言(OQL)简介--高级篇(续):庐山真貌
相关文章内容索引: ORM查询语言(OQL)简介--概念篇 ORM查询语言(OQL)简介--实例篇 ORM查询语言(OQL)简介--高级篇:脱胎换骨 ORM查询语言(OQL)简介--高级篇(续):庐山 ...
- ORM查询语言(OQL)简介--高级篇:脱胎换骨
相关文章内容索引: ORM查询语言(OQL)简介--概念篇 ORM查询语言(OQL)简介--实例篇 ORM查询语言(OQL)简介--高级篇:脱胎换骨 ORM查询语言(OQL)简介--高级篇(续):庐山 ...
- ORM查询语言(OQL)简介高级篇
ORM查询语言(OQL)简介--高级篇:脱胎换骨 在写本文之前,一直在想文章的标题应怎么取.在写了<ORM查询语言(OQL)简介--概念篇>.<ORM查询语言(OQL)简介--实例篇 ...
- 【转载】Spark性能优化指南——高级篇
前言 数据倾斜调优 调优概述 数据倾斜发生时的现象 数据倾斜发生的原理 如何定位导致数据倾斜的代码 查看导致数据倾斜的key的数据分布情况 数据倾斜的解决方案 解决方案一:使用Hive ETL预处理数 ...
随机推荐
- JS原型、原型链深入理解
原型是JavaScript中一个比较难理解的概念,原型相关的属性也比较多,对象有”prototype”属性,函数对象有”prototype”属性,原型对象有”constructor”属性. 一.初识原 ...
- UVALive 3882 - And Then There Was One【约瑟夫问题】
题目链接:https://icpcarchive.ecs.baylor.edu/index.php?option=com_onlinejudge&Itemid=8&page=show_ ...
- string::npos的一些说明
一.定义 std:: string ::npos的定义: static const size_t npos = -1; 表示 size_t 的最大值( Maximum value for size_t ...
- A. Vasya and Football
A. Vasya and Football time limit per test 2 seconds memory limit per test 256 megabytes input standa ...
- 关于atom
以前老听别人说atom这款编辑器如何如何的好用,今天特地试了下,结果一不小心将顶部的工具栏给隐藏了,弄了半天都没弄出来.后来就在网上到处寻找帮助,试试这个试试那个,终于弄好了,其实是这样的. 首先在任 ...
- phpstorm 怎么实现分屏展示
- putty 与winscp 区别
https://zhidao.baidu.com/question/377968180.html putty 与winscp 有什么区别, 装了 winscp 可以由 putty 替换么 ? 具体用法 ...
- Phpstorm10 主题下载
================================================================================ submit:主题 http://ww ...
- 半透明边框与background-clip
在开始本章之前,我们要先简单介绍CSS中的半透明颜色.自2009年后,网页工作者们开始使用半透明颜色,如rgba().hsla().前者相信大家都很熟悉,不难理解其中将有四个参数,第四个参数则为透明度 ...
- MyEclipse或Eclipse导出JavaDoc中文乱码问题解决