1. 初识 Lucene
在学习Lucene之前呢,我们当然首先要了解下什么是Lucene.
0x01 什么是Lucene ?
Lucene是一套用于全文检索和搜索的开放源代码程序库,由Apache软件基金会支持和提供。
Lucene提供了一个简单却强大的应用程序接口,能够做全文索引和搜索,在Java开发环境里Lucene是一个成熟的免费开放源代码工具;
就其本身而论,Lucene是现在并且是这几年,最受欢迎的免费Java信息检索程序库。
Lucene最初是由Doug Cutting所撰写的,他贡献出Lucene的目标是为各种中小型应用程序加入全文检索功能。
Tips: 摘要来自维基百科 https://zh.wikipedia.org/wiki/Lucene
这里我们只需要知道Lucene是目前最为流行的基于 Java 开源全文检索工具包。
0x02 Lucene 是用来做什么的?
基于Lucene的著名项目
| 项目名称 | 项目描述 |
| Apache Nutch | 提供成熟可用的网络爬虫 |
| Apache Solr | 基于Lucenne核心的高性能搜索服务器,提供JSON/Python/Ruby API |
| Elasticsearch | 企业搜索平台,目的是组织数据并使其易于获取 |
| DocFetcher | 跨平台的本机文件搜索桌面程序 |
| Lucene.NET | 提供给.Net平台用户的Lucene类库的封装 |
| Swiftype | 基于Lucene的企业级搜索 |
| Apache Lucy | 为动态语言提供全文搜索的能力,是Lucene Java 库的C接口 |
其实我们不难发现主要用途
- 可以用来编写网络爬虫
- 也可以用来实现网站后台的全文检索。
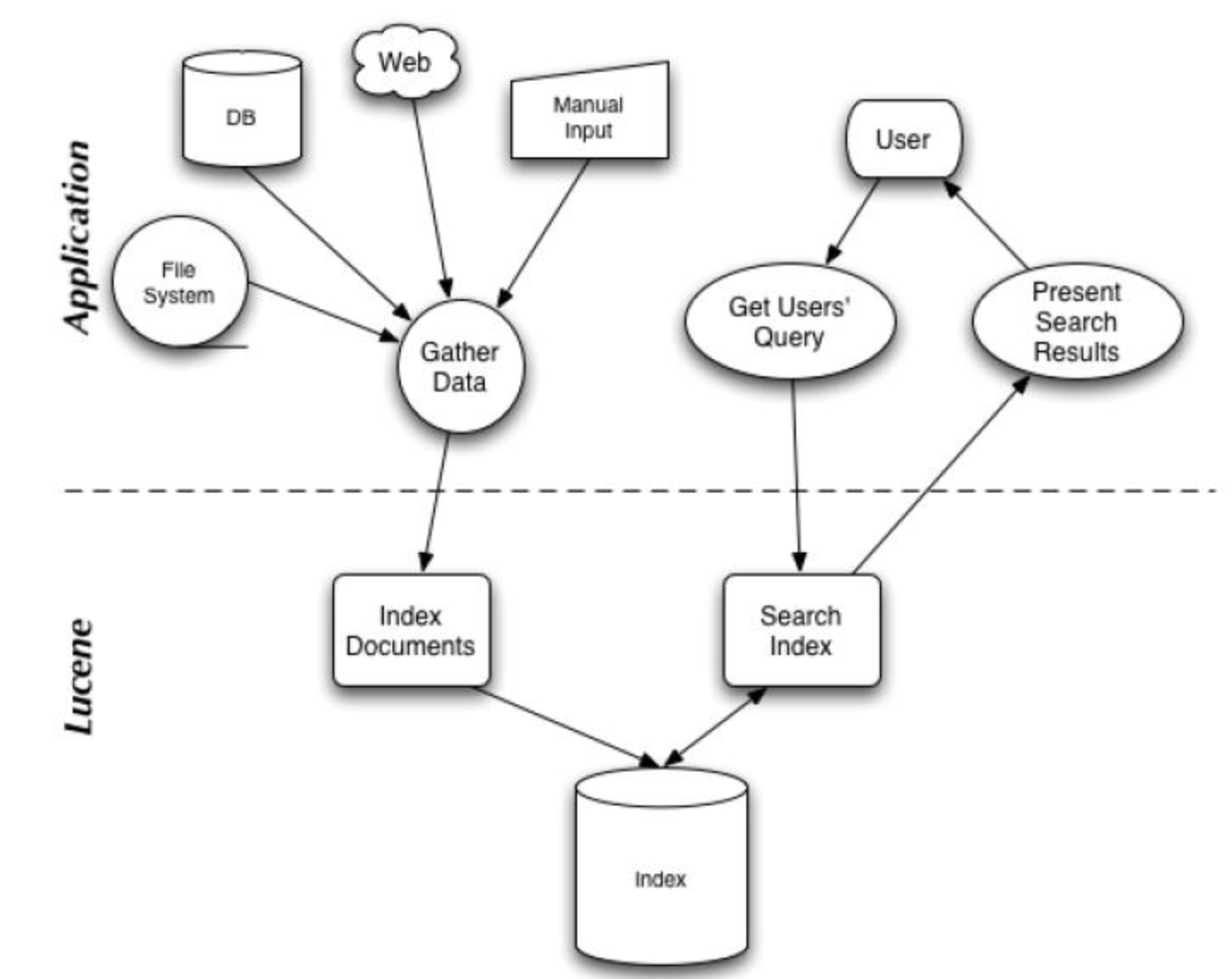
偶然发现这张图感觉挺不错的,在这里分享下:

搜索应用程序和 Lucene 之间的关系
Lucene 能够为文本类型的数据建立索引,所以你只要能把你要索引的数据格式转化的文本的,Lucene 就能对你的文档进行索引和搜索。
0x03 Lucene 软件包分析
Lucene 软件包的发布形式是一个 JAR 文件,下面我们分析一下这个 JAR 文件里面的主要的 JAVA 包,使读者对之有个初步的了解。
Package: org.apache.lucene.document
这个包提供了一些为封装要索引的文档所需要的类,比如 Document, Field。这样,每一个文档最终被封装成了一个 Document 对象。
Package: org.apache.lucene.analysis
这个包主要功能是对文档进行分词,因为文档在建立索引之前必须要进行分词,所以这个包的作用可以看成是为建立索引做准备工作。
Package: org.apache.lucene.index
这个包提供了一些类来协助创建索引以及对创建好的索引进行更新。这里面有两个基础的类:IndexWriter 和 IndexReader,
其中 IndexWriter 是用来创建索引并添加文档到索引中的,IndexReader 是用来删除索引中的文档的。
Package: org.apache.lucene.search
这个包提供了对在建立好的索引上进行搜索所需要的类。比如 IndexSearcher 和 Hits, IndexSearcher 定义了在指定的索引上进行搜索的方法,Hits 用来保存搜索得到的结果。
0x04 搭建Lucene 开发环境?
相信你和我一样已经控制不住自己的洪荒之力想要写个demo来跑跑了,但是在此之前我们还是要先搭建好开发环境。
1. 首先我们需要找到Lucene的官网
Lucene官网:https://lucene.apache.org/

翻译内容如下:
Apache LuceneTM项目开发开源搜索软件,其中包括:
我们的旗舰子项目Lucene Core提供了基于Java的索引和搜索技术,以及拼写检查,高亮显示和高级分析/标记化功能。
SolrTM是一款使用Lucene Core构建的高性能搜索服务器,具有XML / HTTP和JSON / Python / Ruby API,高亮显示,多面搜索,缓存,复制和Web管理界面。
PyLucene是Core项目的Python端口。
2.点击上图中的Download 按钮,会跳转到这个下载页面

Tips: 这里存在很多镜像下载链接,我们选择推荐的下载链接下载即可。
0x05 Lucene Hello World Sample
文档资料相信你在其他网站已经看了不少,但是不写一个能跑起来的Hello World 对于初学者来说是非常痛苦的。
对于这个简单的例子,我们将从一些字符串中创建一个内存索引
1.创建Maven 项目
2.选择创建一个简单的Maven Project

3. 配置工程信息

4. 点击完成

5. 配置POM.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.xingyun</groupId>
<artifactId>lucene-sample</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging> <name>lucene-sample</name> <properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties> <build>
<plugins>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>1.3.2</version>
<executions>
<execution>
<id>ex</id>
<phase>package</phase>
<goals>
<goal>exec</goal>
</goals>
<configuration>
<executable>java</executable>
<arguments>
<argument>-classpath</argument>
<classpath />
<argument>HelloLucene.HelloLucene</argument>
</arguments>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build> <dependencies>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>4.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queries</artifactId>
<version>4.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-test-framework</artifactId>
<version>4.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>4.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>4.0.0</version>
</dependency>
</dependencies>
</project>
6. 创建HelloLucene.java
package com.xingyun; import java.io.IOException;
import java.text.ParseException; import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopScoreDocCollector;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.RAMDirectory;
import org.apache.lucene.util.Version; public class HelloLucene { public static void main(String[] args) throws IOException, ParseException { // 对于这个简单的例子,我们将从一些字符串中创建一个内存索引。
// 0. Specify the analyzer for tokenizing text.
// The same analyzer should be used for indexing and searching
StandardAnalyzer analyzer = new StandardAnalyzer(Version.LUCENE_40); // 1. create the index
Directory index = new RAMDirectory(); IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_40, analyzer); IndexWriter w = new IndexWriter(index, config);
addDoc(w, "Lucene in Action", "193398817");
addDoc(w, "Lucene for Dummies", "55320055Z");
addDoc(w, "Managing Gigabytes", "55063554A");
addDoc(w, "The Art of Computer Science", "9900333X");
w.close(); // 2. query
String querystr = args.length > 0 ? args[0] : "lucene"; // the "title" arg specifies the default field to use
// when no field is explicitly specified in the query.
Query q = null;
try {
q = new QueryParser(Version.LUCENE_40, "title", analyzer).parse(querystr);
} catch (org.apache.lucene.queryparser.classic.ParseException e) {
e.printStackTrace();
} // 3. search
int hitsPerPage = 10;
IndexReader reader = DirectoryReader.open(index);
IndexSearcher searcher = new IndexSearcher(reader);
TopScoreDocCollector collector = TopScoreDocCollector.create(hitsPerPage, true);
searcher.search(q, collector);
ScoreDoc[] hits = collector.topDocs().scoreDocs; // 4. display results
System.out.println("Found " + hits.length + " hits.");
for (int i = 0; i < hits.length; ++i) {
int docId = hits[i].doc;
Document d = searcher.doc(docId);
System.out.println((i + 1) + ". " + d.get("isbn") + "\t" + d.get("title"));
} // reader can only be closed when there
// is no need to access the documents any more.
reader.close();
} private static void addDoc(IndexWriter w, String title, String isbn) throws IOException {
Document doc = new Document();
doc.add(new TextField("title", title, Field.Store.YES)); // use a string field for isbn because we don't want it tokenized
doc.add(new StringField("isbn", isbn, Field.Store.YES));
w.addDocument(doc);
} }
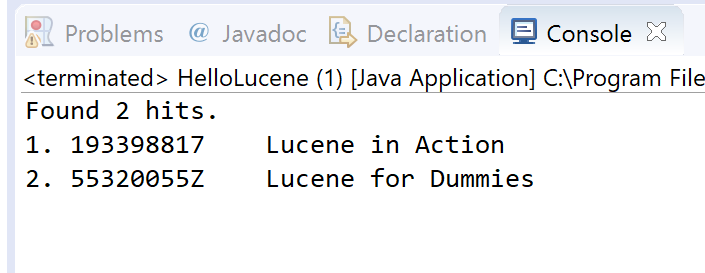
7. 运行后,我们便可以得到索引集合中带有Lucene的所有内容
0x06 代码剖析
我们运行成功后,相信此时的你已经有心情和我一起来分析代码了吧。
1. 创建索引
StandardAnalyzer analyzer = new StandardAnalyzer();
Directory index = new RAMDirectory(); IndexWriterConfig config = new IndexWriterConfig(analyzer); IndexWriter w = new IndexWriter(index, config);
addDoc(w, "Lucene in Action", "193398817");
addDoc(w, "Lucene for Dummies", "55320055Z");
addDoc(w, "Managing Gigabytes", "55063554A");
addDoc(w, "The Art of Computer Science", "9900333X");
w.close();
我们需要虚构一些假的数据,通过上面的方式来对一些字符串和数字创建索引
addDoc 方法定义如下所示:
private static void addDoc(IndexWriter w, String title, String isbn) throws IOException {
Document doc = new Document();
doc.add(new TextField("title", title, Field.Store.YES));
doc.add(new StringField("isbn", isbn, Field.Store.YES));
w.addDocument(doc);
}
2. 查询
String querystr = args.length > 0 ? args[0] : "lucene";
Query q = new QueryParser("title", analyzer).parse(querystr);
3.搜索
int hitsPerPage = 10;
IndexReader reader = DirectoryReader.open(index);
IndexSearcher searcher = new IndexSearcher(reader);
TopDocs docs = searcher.search(q, hitsPerPage);
ScoreDoc[] hits = docs.scoreDocs;
4.显示结果
System.out.println("Found " + hits.length + " hits.");
for(int i=0;i<hits.length;++i) {
int docId = hits[i].doc;
Document d = searcher.doc(docId);
System.out.println((i + 1) + ". " + d.get("isbn") + "\t" + d.get("title"));
}
0x07 参考资料:
Lucene in 5 minutes:http://www.lucenetutorial.com/lucene-in-5-minutes.html
Lucene常识总结以及小demo总结 http://www.imooc.com/article/21946
Lucene 概述: https://www.ibm.com/developerworks/cn/java/j-lo-lucene1/
视频实战教程:
基于Lucene4.6+Solr4.6+Heritrix1.14+S2SH实战开发从无到有垂直搜索引擎
网盘地址:https://pan.baidu.com/s/1nwkAamt 密码: 9ang
备用地址(腾讯微云):http://url.cn/5CmEW7s 密码:p8TmhQ
1. 初识 Lucene的更多相关文章
- 初识Lucene.net
最近想提高下自己的能力,也是由于自己的项目中需要用到Lucene,所以开始接触这门富有挑战又充满新奇的技术.. 刚刚开始,只是写了个小小的demo,用了用lucene,确实很好 创建索引 Data ...
- 初识 Lucene
Lucene是一个信息检索工具库,而不是一个完整的搜索程序 搜索程序 Lucene索引核心类 Lucene索引核心类: Document: 文档对象代表一些域(field)的集合 Field: 每个文 ...
- 第一章 初识Lucene
多看几遍,慢就是快 1.1 应对信息爆炸 1.2 Lucene 是什么 1.2.1 Lucene 能做些什么 1.2.2 Lucene 的历史 1.3 Lucene 和搜索程序组件 基本概念 索引操作 ...
- 初识lucene
lucene的介绍网上有好多,再写一遍可能有点多余了. 使用lucene之前,有一系列的疑问 为什么lucene就比数据库快? 倒排索引是什么,他是怎么做到的 lucene的数据结构是什么样的,cpu ...
- 初识lucene(想看代码的跳过)
最早是在百度贴吧里看到的lucene这个名称,只知道跟搜索引擎有关,因为工作中一直以来没有类似的需求,所以没有花时间学习这方面的知识. 刚过完年,公司不忙,自己闲不住把<Netty权威指南> ...
- (转)初识 Lucene
Lucene 是一个基于 Java 的全文信息检索工具包,它不是一个完整的搜索应用程序,而是为你的应用程序提供索引和搜索功能.Lucene 目前是 Apache Jakarta 家族中的一个开源项目. ...
- 实战 Lucene,第 1 部分: 初识 Lucene (zhuan)
http://www.ibm.com/developerworks/cn/Java/j-lo-lucene1/ ******************************************** ...
- 搜索引擎学习(一)初识Lucene
一.Lucene相关基础概念 定义:一个简易的工具包,实现文件搜索的功能,支持中文,关键字,多条件查询,凡是文件名或文件内容包含的都查出来. 数据分类:结构化数据(固定格式或有限长度的数据)和非结构化 ...
- 【转载】Lucene.Net入门教程及示例
本人看到这篇非常不错的Lucene.Net入门基础教程,就转载分享一下给大家来学习,希望大家在工作实践中可以用到. 一.简单的例子 //索引Private void Index(){ Index ...
随机推荐
- 【转载】使用SDL播放YUV图像数据(转)
SDL提供了针对YUV格式数据的直接写屏操作.废话不多说,直接上代码吧/** * file showyuv.c * author: rare * date: 2009/12/06 * email: d ...
- Error Code: 1054. Unknown column 'age' in 'user'
1.错误描述 10:28:20 alter table user modify age int(3) after sex Error Code: 1054. Unknown column 'age' ...
- Flex中的DataGrid报错(一)
1.错误描述 此行的多个标记: -holeNum -1105: 赋值的目标必须是引用值. 2.错误原因 detailWindow.holeNum.toString() = &q ...
- 芝麻HTTP:Gerapy的安装
Gerapy是一个Scrapy分布式管理模块,本节就来介绍一下它的安装方式. 1. 相关链接 GitHub:https://github.com/Gerapy 2. pip安装 这里推荐使用pip安装 ...
- JAVA几种缓存技术介绍说明
OSCache OSCache是个一个广泛采用的高性能的J2EE缓存框架,OSCache能用于任何Java应用程序的普通的缓存解决方案. OSCache有以下特点: 我创建了一个群,群里不定期分享技术 ...
- Servlet程序
编写: (1)搭建javaweb项目: 1,创建一个java项目:HelloServletWeb 2,在HelloServletWeb中创建一个文件夹webapp表示Web的根 3,在webapp中创 ...
- 关于transform的3D变形函数
继续transform的3D用法: translate3d(x,y,z)定义3D转换 transformX(x)只用x轴的值进行转换: transformY(y)只用y轴的值进行转换: transfo ...
- [Luogu2463][SDOI2008]Sandy的卡片
BZOJ权限题qwq Luogu sol "两个子串长度相同且一个串的全部元素加上一个数就会变成另一个串" 其实就是差分一波以后完全相同 所以对输入的数据进行差分,同时记一下每一个 ...
- SPOJ3267:D-query
题面 SPOJ3267 Sol 给定\(N\)个正整数构成的序列,将对于指定的闭区间查询其区间内的不同的数的个数 主席树 不是权值线段树 维护位置 如果插入一个数时发现之前有过了 那么修改当前的,那个 ...
- [HNOI2010]BUS 公交线路
题面 Bzoj Sol 状压很显然 重点在于转移:题目就相当与每\(p\)长度的车站必须有且仅有\(k\)个被经过 那么转移时状压的二进制一定要有\(k\)个一 且两个相邻转移的状态之间必须满足:设为 ...