jupyter notebook的架构
最近项目需要改写jupyter notebook的内核,由于内功不够,英语过差,读文档真的是心痛,然后各种搜索找到了一篇不错的讲解。
转自:http://blog.just4fun.site/jupyter-notebook-architecture.html
在jupyter主页上,官方有对其做个简要说明:
The Jupyter Notebook is based on a set of open standards for interactive computing. Think HTML and CSS for interactive computing on the web. These open standards can be leveraged by third party developers to build customized applications with embedded interactive computing.
jupyter notebook基于若干开放标准,可以将其视为三个部分:
- Notebook Document Format : 基于JSON的开放文档格式,完整地记录用户的会话(sessions)和代码、说明性的文本、方程以及富文本输出
- Interactive Computing Protocol: 该协议用于连接Notebook和内核,基于JSON数据、ZMQ以及WebSockets
- The Kernel: 使用特定编程语言实际跑代码的地方,并将输出返回给用户。内核也返回tab键补全信息
架构图
上边提到的三个部分直接的关系如下
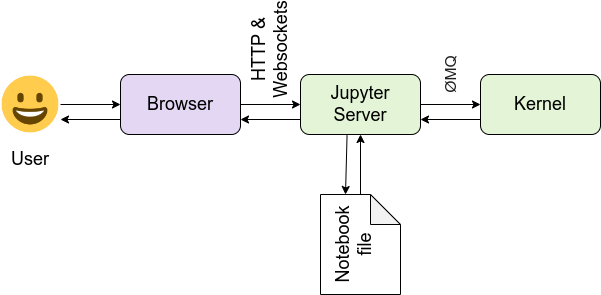
于是我们可以回答what happens when这类经典问题,当我们点击运行print("hello world")时发生了什么
从上图我们可以看出发生了这样一些事:用户在浏览器里写代码,点击运行后,代码从浏览器发送给Web服务器(tornado),接着从Web服务器发送消息到Kernel(python)执行代码,在Kernel中执行代码产生的输出/错误会被发送给Web服务器,接着发往给浏览器,用户于是看到输出,这个过程说起来很绕,实际执行飞快无比
如果你对jupyter的生态有兴趣,那么下边这张架构图,能让你看出各个项目直接的关系,如果你只关心jupyter notebook,它也给出了更为细致的信息
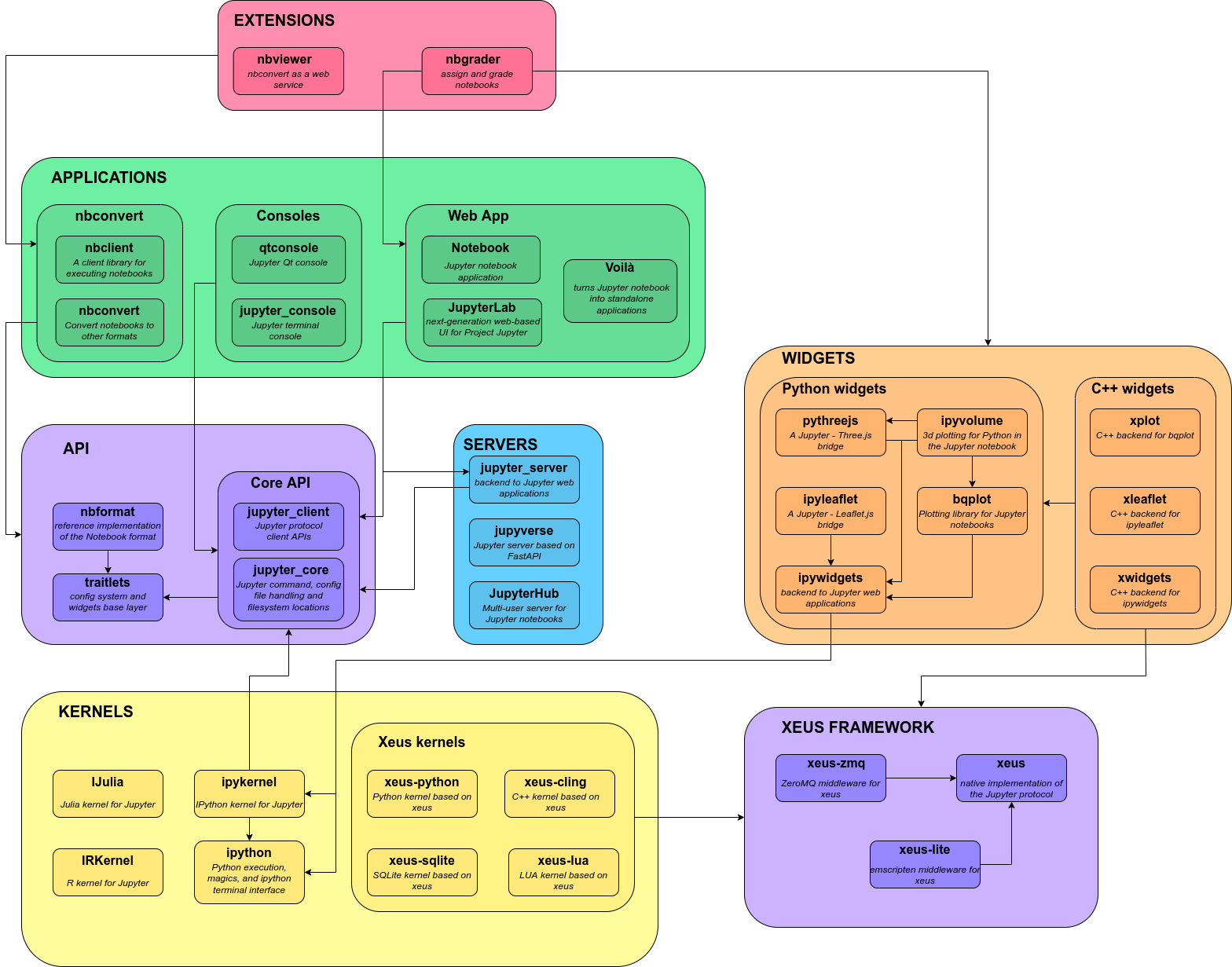
简单直译(英语差):
servers:jupyterhub --> 需要登录的多用户笔记本
tmpnb --> 不需要登录的临时笔记本
nbgrader --> 作为任务创建和分级的笔记本
nbviewer --> 网站笔记本的HTML视图
Applications: nbconvert --> 将笔记本文件转换为其他格式
notebook --> Jupyter notebook 应用相当于Django的app
qtconcle --> 控制应用
jupyter_consle-->Jupyter 终端应用
API:nbformat --> ipython 文件下载,保存,格式版本迁移和信托
jupyter_client
jupyter_core --> jupyter命令,配置文件和文件系统位置
Kernerl : ipywidgets --> 交互组件
ipython --> python代码执行,魔法语法和ipython终端交互
ipykernel --> 内核通讯协议
traitlets --> 所有依赖:配置系统和小部件基础层
如果你对通信过程很感兴趣,这一看下这张图(消息的传输用到了 ZeroMQ):
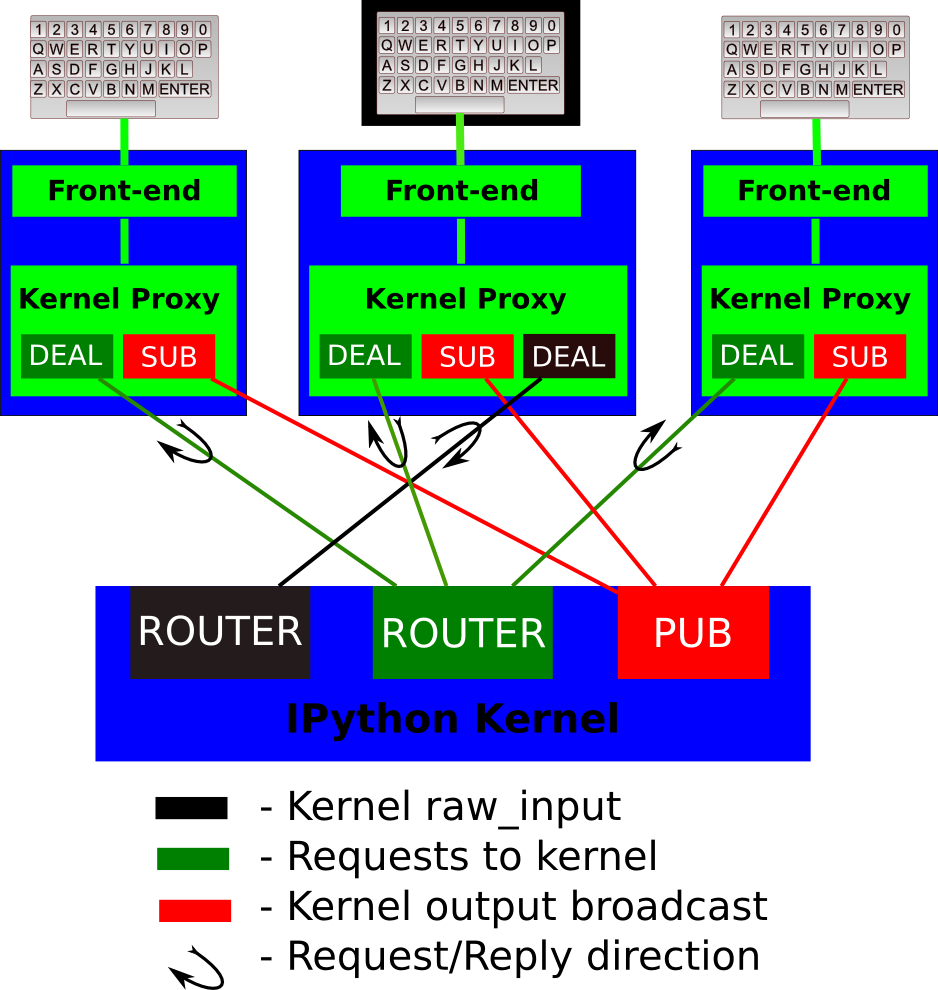
如果你对ZeroMQ有兴趣,可以看我之前的笔记消息队列中间件学习笔记
从途中我们可以看到主要利用了ZeroMQ的Publisher-Subscriber模式来做通信
回到我的项目上
对上边what happens when的回答稍作修改,我们就能得到一个改良版的blocklu4pi的架构,而且这类架构几乎适用于任何的web IDE类型的项目。blockly正在流行,这套架构之后大有用武之地
修改后的通信流程为: 用户在浏览器里拖拽blockly积木块生成代码,点击运行后,代码从浏览器发送给Web服务器(tornado),接着从Web服务器发送消息到Kernel(python)执行代码,在Kernel中执行代码产生的输出/错误会被发送给Web服务器,接着发往给浏览器,用户于是看到输出
上述两个流程的区别仅在于产生代码的方式不同而已,jupyter是用户手写,而blockly是用积木生成,余下过程一!模!一!样!
交互式探索
为了对通信和调用过程有更细致的了解,我们可以在notebook里进行交互式探索, REPL优雅之处在于让我们方便地做实验与探索未知
这篇文章给了我们一个思路来观察Kernel是如何接收、运行和返回消息:
用户代码和Kernel在同一进程中执行,因此我们可以通过一些特殊的代码研究Kernel是如何接收、运行并返回消息的
作者接下来演示了如何通过
gc, threading, traceback, inspect查看了Kernel是如何接收和发送消息,以及如何运行用户代码的
非常有意思的一篇分析,不过因为时间过去较久,架构有些调整,所以我这边给出最新的交互数据
我的版本为
- jupyter 4.3.0
- ipython 5.2.2
- notebook 4.4.1
下边是实验数据
Kernel中的Socket对象
通过gc模块的get_objects()遍历进程中所有的对象
- mport gc
- def get_objects(class_name):
- return [o for o in gc.get_objects() if type(o).__name__ == class_name]
- kapp = get_objects("IPKernelApp")[0] #<ipykernel.kernelapp.IPKernelApp at 0x108a22d10>
- kapp.shell_socket, kapp.iopub_socket # (<zmq.sugar.socket.Socket at 0x108a8d328>, <ipykernel.iostream.BackgroundSocket at 0x108aa3850>)
IPKernelApp对象的shell_socket和iopub_socket分别用于接收命令和广播代码执行输出,对应于架构图部分表示通信过程的图中绿色和红色端口
在Notebook中执行用户输入的print时,会经由iopub_socket将输出的内容传送给Web服务器,最终在Notebook界面中显示
我们知道python中,print语句实际上会调用sys.stdout完成输出工作
那么Kernel中的sys.stdout是什么对象
- import sys
- print sys.stdout #<ipykernel.iostream.OutStream object at 0x108a9cfd0>
- print sys.stdout.pub_thread # <ipykernel.iostream.IOPubThread at 0x108aa32d0>
前头说到iopub_socket用于广播代码的输出,可以推测sys.stdout是一个对kapp.iopub_socket进行包装的OutStream对象(sys.stdout经由kapp.iopub_socket广播出来)
我们可以发现sys.stderr和sys.stdout是同个对象(内存地址完全相同)
Kernel中的线程
通过threading.enumerate()可以获得当前进程中的所有线程
- import threading
- threading.enumerate()
- '''
- [<_MainThread(MainThread, started 140736413283264)>,
- <Thread(Thread-2, started daemon 123145475149824)>,
- <HistorySavingThread(IPythonHistorySavingThread, started 123145485709312)>,
- <Heartbeat(Thread-3, started daemon 123145479356416)>,
- <ParentPollerUnix(Thread-1, started daemon 123145489915904)>]
- '''
各个线程的功能为:
- 主线程(MainThread)接收来自前端的命令,执行用户代码,并输出代码的执行结果。
- HistorySaving线程用户将用户输入的历史保存到Sqlite数据库中
- Heartbeat线程用于定时向前端发送消息,用于检测心跳
- ParentPollerUnix线程,监视父进程,如果父进程退出,则保证Kernel进程也退出
用户代码的执行
通过在用户代码中执行traceback.print_stack()输出整个执行堆栈
- File "/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/runpy.py", line 162, in _run_module_as_main
- "__main__", fname, loader, pkg_name)
- File "/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/runpy.py", line 72, in _run_code
- exec code in run_globals
- File "/Users/wwj/env/lib/python2.7/site-packages/ipykernel/__main__.py", line 3, in <module>
- app.launch_new_instance()
- File "/Users/wwj/env/lib/python2.7/site-packages/traitlets/config/application.py", line 658, in launch_instance
- app.start()
- File "/Users/wwj/env/lib/python2.7/site-packages/ipykernel/kernelapp.py", line 474, in start
- ioloop.IOLoop.instance().start()
- File "/Users/wwj/env/lib/python2.7/site-packages/zmq/eventloop/ioloop.py", line 177, in start
- super(ZMQIOLoop, self).start()
- File "/Users/wwj/env/lib/python2.7/site-packages/tornado/ioloop.py", line 887, in start
- handler_func(fd_obj, events)
- File "/Users/wwj/env/lib/python2.7/site-packages/tornado/stack_context.py", line 275, in null_wrapper
- return fn(*args, **kwargs)
- File "/Users/wwj/env/lib/python2.7/site-packages/zmq/eventloop/zmqstream.py", line 440, in _handle_events
- self._handle_recv()
- File "/Users/wwj/env/lib/python2.7/site-packages/zmq/eventloop/zmqstream.py", line 472, in _handle_recv
- self._run_callback(callback, msg)
- File "/Users/wwj/env/lib/python2.7/site-packages/zmq/eventloop/zmqstream.py", line 414, in _run_callback
- callback(*args, **kwargs)
- File "/Users/wwj/env/lib/python2.7/site-packages/tornado/stack_context.py", line 275, in null_wrapper
- return fn(*args, **kwargs)
- File "/Users/wwj/env/lib/python2.7/site-packages/ipykernel/kernelbase.py", line 276, in dispatcher
- return self.dispatch_shell(stream, msg)
- File "/Users/wwj/env/lib/python2.7/site-packages/ipykernel/kernelbase.py", line 228, in dispatch_shell
- handler(stream, idents, msg)
- File "/Users/wwj/env/lib/python2.7/site-packages/ipykernel/kernelbase.py", line 390, in execute_request
- user_expressions, allow_stdin)
- File "/Users/wwj/env/lib/python2.7/site-packages/ipykernel/ipkernel.py", line 196, in do_execute
- res = shell.run_cell(code, store_history=store_history, silent=silent)
- File "/Users/wwj/env/lib/python2.7/site-packages/ipykernel/zmqshell.py", line 501, in run_cell
- return super(ZMQInteractiveShell, self).run_cell(*args, **kwargs)
- File "/Users/wwj/env/lib/python2.7/site-packages/IPython/core/interactiveshell.py", line 2717, in run_cell
- interactivity=interactivity, compiler=compiler, result=result)
- File "/Users/wwj/env/lib/python2.7/site-packages/IPython/core/interactiveshell.py", line 2827, in run_ast_nodes
- if self.run_code(code, result):
- File "/Users/wwj/env/lib/python2.7/site-packages/IPython/core/interactiveshell.py", line 2881, in run_code
- exec(code_obj, self.user_global_ns, self.user_ns)
- File "<ipython-input-2-2e94e8c65f66>", line 2, in <module>
- traceback.print_stack()
从中可以看到用户代码是如何被调用的
在KernelApp对象的start()中,调用ZeroMQ中的ioloop.start()处理来自shell_socket的消息。当从Web服务器接收到execute_request消息时,将调用kernel.execute_request()方法
kapp.kernel.execute_request #<bound method IPythonKernel.execute_request of <ipykernel.ipkernel.IPythonKernel object at 0x10c09f910>>
在execute_request()中调用shell对象的如下方法最终执行用户代码:
- print kapp.kernel.shell.run_cell #<bound method ZMQInteractiveShell.run_cell of <ipykernel.zmqshell.ZMQInteractiveShell object at 0x10c09f950>>
- print kapp.kernel.shell.run_ast_nodes #<bound method ZMQInteractiveShell.run_ast_nodes of <ipykernel.zmqshell.ZMQInteractiveShell object at 0x10c09f950>>
- print kapp.kernel.shell.run_code #<bound method ZMQInteractiveShell.run_code of <ipykernel.zmqshell.ZMQInteractiveShell object at 0x10c09f950>>
shell对象在其user_global_ns和user_ns属性在执行代码,这两个字典就是用户代码的执行环境,实际上它们是同一个字典
- print globals() is kapp.kernel.shell.user_global_ns #True
- print globals() is kapp.kernel.shell.user_ns #True
查看shell_socket的消息
可以利用inspect.stack()获得前面的执行堆栈中的各个frame对象,从而查看堆栈中的局域变量的内容,这样可以观察到Kernel经由shell_socket接收的回送的消息
- import inspect
- frames = {}
- for info in inspect.stack():
- if info[3] == "dispatch_shell":
- frames["request"] = info[0]
- if info[3] == "execute_request":
- frames["reply"] = info[0]
- print "hello world"
以上代码在kernel里执行的时候,通信过程已经完成,所以我们可以拿到frames["request"],frames["reply"]在print "hello world"之前执行,所以frames["reply"]不包含代码运行的结果
Kernel接收到的消息
- frames["request"].f_locals["msg"]
- '''
- {'buffers': [],
- 'content': {'allow_stdin': True,
- 'code': 'import inspect\nframes = {}\nfor info in inspect.stack():\n if info[3] == "dispatch_shell":\n frames["request"] = info[0]\n if info[3] == "execute_request":\n frames["reply"] = info[0]\nprint "hello world"',
- 'silent': False,
- 'stop_on_error': True,
- 'store_history': True,
- 'user_expressions': {}},
- 'header': {'date': datetime.datetime(2017, 3, 8, 9, 35, 4, 596768, tzinfo=tzutc()),
- 'msg_id': '0616032D8FE8469780CA0A4A89D578AD',
- 'msg_type': 'execute_request',
- 'session': '6DDDE94601B247779637A3F3A0F2F573',
- 'username': 'username',
- 'version': '5.0'},
- 'metadata': {},
- 'msg_id': '0616032D8FE8469780CA0A4A89D578AD',
- 'msg_type': 'execute_request',
- 'parent_header': {}}
- '''
Kernel对上述消息的应答
- frames["reply"].f_locals["reply_msg"]
- '''
- {'content': {u'execution_count': 4,
- u'payload': [],
- u'status': u'ok',
- u'user_expressions': {}},
- 'header': {'date': datetime.datetime(2017, 3, 8, 9, 35, 4, 613218, tzinfo=tzutc()),
- 'msg_id': u'd4d00f59-d6a3739d12069c2fb8c0a23f',
- 'msg_type': u'execute_reply',
- 'session': u'337fb80f-b3760e2423717a4de6ff4ba8',
- 'username': u'wwj',
- 'version': '5.0'},
- 'metadata': {'dependencies_met': True,
- 'engine': u'7b3fd05a-613d-4c6e-a789-f952660d4edf',
- 'started': datetime.datetime(2017, 3, 8, 17, 35, 4, 598015),
- 'status': u'ok'},
- 'msg_id': u'd4d00f59-d6a3739d12069c2fb8c0a23f',
- 'msg_type': u'execute_reply',
- 'parent_header': {'date': datetime.datetime(2017, 3, 8, 9, 35, 4, 596768, tzinfo=tzutc()),
- 'msg_id': '0616032D8FE8469780CA0A4A89D578AD',
- 'msg_type': 'execute_request',
- 'session': '6DDDE94601B247779637A3F3A0F2F573',
- 'username': 'username',
- 'version': '5.0'},
- 'tracker': <zmq.sugar.tracker.MessageTracker at 0x10b266f50>}
- '''
上面的应答消息并非代码的执行结果,代码的输出在执行代码时已经经由sys.stdout->iopub_socket发送给Web服务器了。
手写一jupyter
jupyter已经演变得非常庞大,许多的代码都在打磨细节,如此一来直接阅读源码,会陷入各种细枝末节里,不大好一眼看到核心逻辑。为了理解原理,溯本求源是一个好方法,一种策略是翻到早起的版本或者commit
另一种策略是看一些类似的小项目(专注在原理实现),zmq-pykernel是一个不错的实验,它基于ZeroMQ来实现,非常小巧
写一个自己的kernel
尽管官方文档有相应教程,不过直接从metakernel开始是个不错的选择,metakernel为我们做了许多起步阶段的工作,具体可以参考metakernel features
参考
一个完美的报错

看到这个报错后,瞬间感觉信息量好大。。。
jupyter notebook的架构的更多相关文章
- MAC安装python jupyter notebook
介绍: Jupyter Notebook(此前被称为 IPython notebook)是一个交互式笔记本,支持运行 40 多种编程语言. Jupyter Notebook 的本质是一个 Web 应用 ...
- 安装、配置Jupyter Notebook快速入门教程
What? Why? How? ---安装 ---启动 ---关闭 ---保存 Markdown语法 Magic关键词 转换notebook--toHTML 创建幻灯片 运行代码 What? 文字化编 ...
- [Python Debug]Kernel Crash While Running Neural Network with Keras|Jupyter Notebook运行Keras服务器宕机原因及解决方法
最近做Machine Learning作业,要在Jupyter Notebook上用Keras搭建Neural Network.结果连最简单的一层神经网络都运行不了,更奇怪的是我先用iris数据集跑了 ...
- 玩转 Jupyter Notebook (CentOS)
Jupyter Notebook 简介 Jupyter Notebook 是一个开源的 Web 应用程序,可以用来创建和共享包含动态代码.方程式.可视化及解释性文本的文档.其应用于包括:数据整理与转换 ...
- 【学习笔记】第三章 python3核心技术与实践--Jupyter Notebook
可能你已经知道,Python 在 14 年后的“崛起”,得益于机器学习和数学统计应用的兴起.那为什么 Python 如此适合数学统计和机器学习呢?作为“老司机”的我可以肯定地告诉你,Jupyter N ...
- Ubuntu 18.04安装Conda、Jupyter Notebook、Anaconda
1.Conda是一个开源的软件包管理系统和环境管理系统,它可以作为单独的纯净工具安装在系统环境中,有的python库无法用conda获得时,conda允许在conda环境中利用Pip获取包文件.可以将 ...
- 基于Ubuntu+Python+Tensorflow+Jupyter notebook搭建深度学习环境
基于Ubuntu+Python+Tensorflow+Jupyter notebook搭建深度学习环境 前言一.环境准备环境介绍软件下载VMware下安装UbuntuUbuntu下Anaconda的安 ...
- 在pytorch下使用tensorboardX(win10;谷歌浏览器;jupyter notebook)
使用环境:win10 ,在jupyter notebook下运行 谷歌浏览器 1.环境安装 使用conda 安装,打开anacond powershell,输入pip install tensorbo ...
- Python 代码编辑器怎么选?PyCharm、VS Code、Jupyter Notebook 都各有特色
Python 代码编辑器怎么选?PyCharm.VS Code.Jupyter Notebook 都各有特色,Jupyter 适合做数据分析这些需要可视化的操作,PyCharm 更适合做完整的 Pyt ...
随机推荐
- 从Socket入门到BIO,NIO,multiplexing,AIO
Socket入门 最简单的Server端读取Client端内容的demo public class Server { public static void main(String [] args) t ...
- Lucene-02:搜索初步
承接上一篇文章. package com.amazing; import java.io.File; import java.io.IOException; import org.apache.luc ...
- Python中四种样式的99乘法表
1.常规型. #常规型 i=1 while i<=9: j=1 while j<=i: print(''%d*%d=%2d''%(i,j,i*j),end='') i+=1 #等号只是用来 ...
- 【HTML】 HTML基础知识 一些标签
额..是这样的,去年为了学习web框架,自己开发了一个zbx配置管理的二次开发系统,当时从零开始接触web开发,也第一次接触到了前端的一些知识.其中最基础的就是html/css了.我把那部分笔记整理上 ...
- [css 揭秘]:CSS揭秘 技巧(二):多重边框
我的github地址:https://github.com/FannieGirl/ifannie/ 源码都在这上面哦! 喜欢的给我一个星吧 多重边框 问题:我们通常希望在css代码层面以更灵活的方式来 ...
- mac上Pycharm个性化快捷键,类似Myeclipse的快速复制等快捷键
好几天没写博客了,在win10下写了几天python,然后下了pycharm使用,发现还可以,但是太笨重了,切回了mac,然后装了pycharm社区版本. 但是这个使用太别扭了,没有myeclipse ...
- python 函数基础 定义
一.函数介绍 1.为什么要有函数? 没有函数的代码组织结构不清晰,可读性差. 代码冗余 管理维护难度大,扩展性 2.什么是函数? 具备某一个功能的工具就是程序中的函数. 事先准备工具的过程就是:函数的 ...
- React demo:express、react-redux、react-router、react-roter-redux、redux-thunk(二)
上一篇杂七杂八说了下express部分的,现在开始进入正题. 接下去的顺序,就是项目从零开始的顺序(思路方向). [actions定义] 如图,目录页,有4部分的内容,所以以下几个actions是需要 ...
- Hibernate学习(4)- Hibernate对象的生命周期
1.Hibernate对象的生命周期(瞬时状态.持久化状态.游离状态) 1.瞬时状态(Transient): 使用new操作符初始化的对象就是瞬时状态,没有跟任何数据库数据相关联:2.持久化状态(Pa ...
- Semaphore 源码分析
Semaphore 源码分析 1. 在阅读源码时做了大量的注释,并且做了一些测试分析源码内的执行流程,由于博客篇幅有限,并且代码阅读起来没有 IDE 方便,所以在 github 上提供JDK1.8 的 ...