一天搞懂深度学习-训练深度神经网络(DNN)的要点
前言
这是《一天搞懂深度学习》的第二部分
一、选择合适的损失函数
典型的损失函数有平方误差损失函数和交叉熵损失函数。
交叉熵损失函数:

选择不同的损失函数会有不同的训练效果
二、mini-batch和epoch
(1)什么是mini-batch和epoch
所谓的mini-batch指的是我们将原来的数据分成不重叠的若干个小的数据块。然后在每一个epoch里面分别的运行每个mini-batch。ecpoch的次数和mini-batch的大小可以由我们自己设置。
(2)进行mini-batch和epoch划分的原因
之所以要进行mini-batch和epoch的改变,一个很重要的原因是这样就可以实现并行计算。但是这样的话,每一次的L就不是全局损失而是局部损失。mini-batch采用了并行计算会比之前传统算法的速度更快。并且mini-batch的效果会比传统的方法好
(3)mini-batch和epoch的缺点
mini-batch是不稳定的。mini-batch不一定会收敛。
三、新的激励函数
深度学习并不是说神经网络的层数越多越好。因为神经网络的深度越深那么在误差回传的过程中,因为层数过多可能会有梯度消失的问题。所谓梯度消失问题指的是在训练的过程中,越靠近输出层的学习的越快越靠近输入层的学习的越慢。那么随着深度的增加,靠近输出层的隐含层权重已经收敛了,但是靠近输入层的隐含层却还没有什么变化,相当于还是像初始的时候一样权重是随机的。
为了梯度消失的问题,学者提出了使用ReLU函数作为激励函数。以下是ReLU函数:
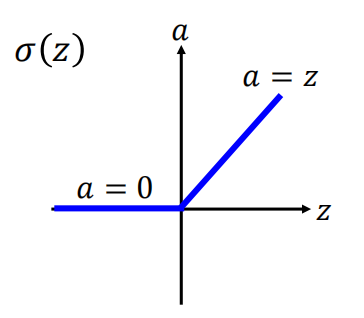
(1)为什么要选择ReLU函数作为激励函数
1.很容易计算
2.Relu函数和我们神经元的激励机制很像:神经元只有在接收一定量的刺激才能够产生反应
3.infinite sigmoid with different biases【这句话不知道咋解释】
4.解决梯度消失问题
(2)ReLU函数的变种
ReLU函数有很多种形式,上面的函数图像只是其中最原始的一种。还有Leaky ReLU和Parametric ReLU
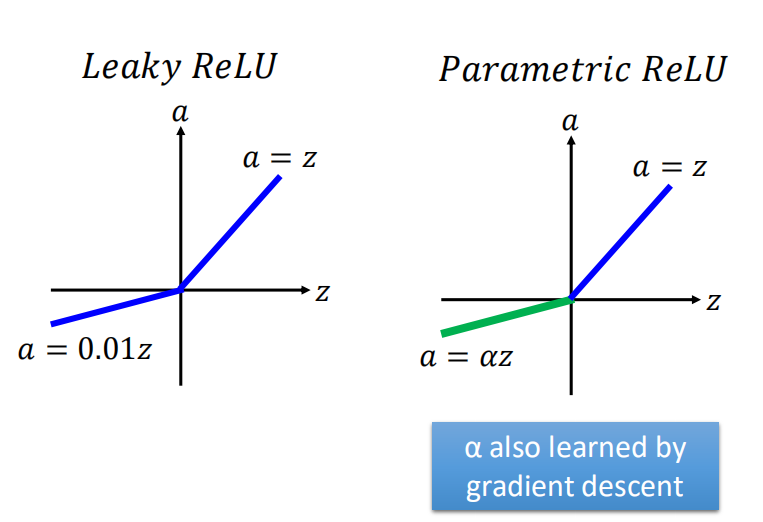
(3)Maxout激励函数
Maxout激励函数先将隐含层的神经元进行分组然后利用分段函数得到组中每一个elements的值,取最大的输出。这个分段函数分的段数是取决于一个group里面有多少个elements。其实ReLU就是一个group里面只有一个element的Maxout激励函数
四、自适应的学习率
学习率是一个很重要的参数,如果学习率选择的太大的话就会出现无法收敛的情况,如果学习率选择的太小的话收敛的太慢,训练过程太长。
我们选择学习率一般不是选择一个固定的值,而是让它随着训练次数的不断增加而减少。学习率针对不同的参数应该是不同的。并且对于所有的参数来说学习率应该越来越小。导数越大,学习率越小;导数越小,学习率越大。【这里导数是有正负性的】
五、Momentum
单纯的使用导数用于改变学习率,很容易陷入局部最小,或者极值点。为了避免这一点,我们使用了Momentum。虽然加上Momentum并不能完全的避免陷入局部最小,但是可以从一定的程度上减缓这个现象。
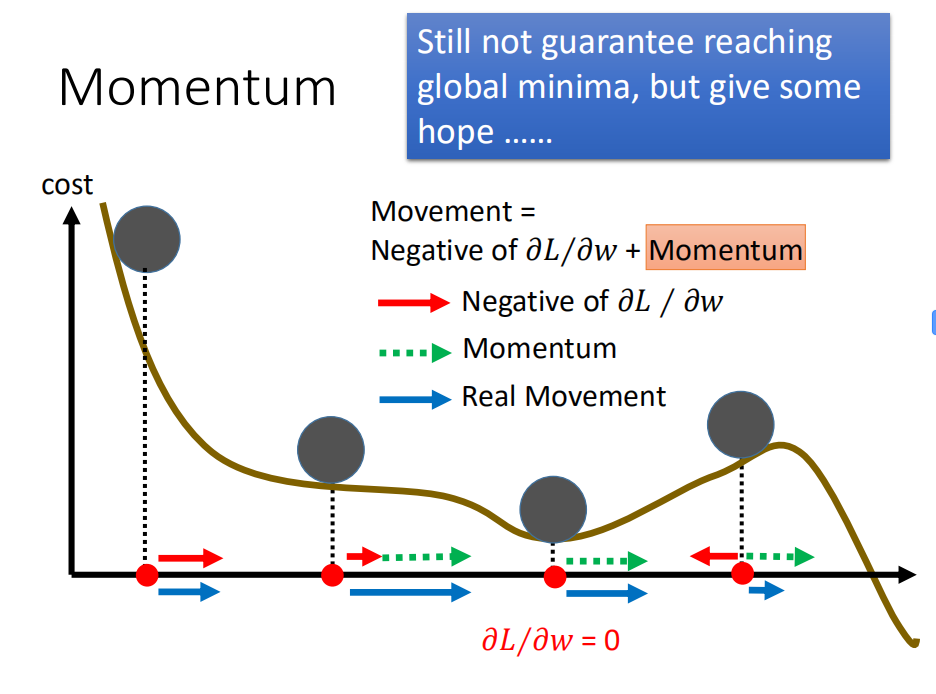
六、过拟合
所谓的过拟合,就是过度的学习训练集的特征,将训练集独有的特征当做了数据的全局特征,使得其无法适应测试集的分布。
防止过拟合的方法叫做正则化,正则化的方式有很多。
在神经网络中正则化的方法主要有四种:
1.早起停止(eary stopping):比如我们可以设置训练的最大轮数等
2.权重衰减:减少无用的边的权重
3.droupout:每次训练的时候都删除一些节点单元,这样会使网络结构变得简单,训练过程也变得更加简单。它的定义是如果你在训练的阶段对于某一层删除了p%节点,那么你在训练时该层的神经元的权重也要衰减p%。droupout可以看做是一个ensamble的过程。
4.网络结构:比如CNN
一天搞懂深度学习-训练深度神经网络(DNN)的要点的更多相关文章
- java web应用调用python深度学习训练的模型
之前参见了中国软件杯大赛,在大赛中用到了深度学习的相关算法,也训练了一些简单的模型.项目线上平台是用java编写的web应用程序,而深度学习使用的是python语言,这就涉及到了在java代码中调用p ...
- 中文译文:Minerva-一种可扩展的高效的深度学习训练平台(Minerva - A Scalable and Highly Efficient Training Platform for Deep Learning)
Minerva:一个可扩展的高效的深度学习训练平台 zoerywzhou@gmail.com http://www.cnblogs.com/swje/ 作者:Zhouwan 2015-12-1 声明 ...
- TensorRT深度学习训练和部署图示
TensorRT深度学习训练和部署 NVIDIA TensorRT是用于生产环境的高性能深度学习推理库.功率效率和响应速度是部署的深度学习应用程序的两个关键指标,因为它们直接影响用户体验和所提供服务的 ...
- 基于NVIDIA GPUs的深度学习训练新优化
基于NVIDIA GPUs的深度学习训练新优化 New Optimizations To Accelerate Deep Learning Training on NVIDIA GPUs 不同行业采用 ...
- MLPerf结果证实至强® 可有效助力深度学习训练
MLPerf结果证实至强 可有效助力深度学习训练 核心与视觉计算事业部副总裁Wei Li通过博客回顾了英特尔这几年为提升深度学习性能所做的努力. 目前根据英特尔 至强 可扩展处理器的MLPerf结果显 ...
- 深度学习训练过程中的学习率衰减策略及pytorch实现
学习率是深度学习中的一个重要超参数,选择合适的学习率能够帮助模型更好地收敛. 本文主要介绍深度学习训练过程中的6种学习率衰减策略以及相应的Pytorch实现. 1. StepLR 按固定的训练epoc ...
- 学习笔记︱Nvidia DIGITS网页版深度学习框架——深度学习版SPSS
DIGITS: Deep Learning GPU Training System1,是由英伟达(NVIDIA)公司开发的第一个交互式深度学习GPU训练系统.目的在于整合现有的Deep Learnin ...
- 深度学习之卷积神经网络(CNN)的应用-验证码的生成与识别
验证码的生成与识别 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/10755361.html 目录 1.验证码的制 ...
- 深度学习之循环神经网络RNN概述,双向LSTM实现字符识别
深度学习之循环神经网络RNN概述,双向LSTM实现字符识别 2. RNN概述 Recurrent Neural Network - 循环神经网络,最早出现在20世纪80年代,主要是用于时序数据的预测和 ...
随机推荐
- epoll通俗讲解
转载地址:http://yaocoder.blog.51cto.com/2668309/888374 首先我们来定义流的概念,一个流可以是文件,socket,pipe等等可以进行I/O ...
- css3动画从入门到精通
什么是css3动画? 通过 CSS3,我们能够创建动画,这可以在许多网页中取代动画图片.Flash 动画以及 JavaScript. CSS3带来了圆角,半透明,阴影,渐变,多背景图等新的特征,轻松实 ...
- Linux下编译GDAL
一.准备工作 从官网下载GDAL.PROJ.4和GEOS,将其存放在/home/liml/Work/3rdPart目录并解压,如下图所示.下载地址请自行Google.注:使用的系统是CentOS6.4 ...
- 用javah 导出类的头文件, 常见的错误及正确的使用方法
******************************************************************************** 用javah 导出类的头文件, 常见的 ...
- 《java入门第一季》之面向对象(private关键字与封装概念的初探)
/* 定义一个学生类: 成员变量:name,age 成员方法:show()方法 在使用这个案例的过程中,发现了一个问题: 通过对象去给成员变量赋值,可以赋值一些非法的数据.例如:name你赋值了一个3 ...
- 求剁手的分享,如何简单开发js图表
前段时间做的一个项目里需要用到js图表,在网上找了下,大概找到了highcharts.fusioncharts这些国外产品. 因为都收费,虽然有盗版,我也不敢用,万一被找上们来就砸锅卖铁了要.自己写j ...
- TCP的核心系列 — SACK和DSACK的实现(五)
18版本对于每个SACK块,都是从重传队列头开始遍历.37版本则可以选择性的遍历重传队列的某一部分,忽略 SACK块间的间隙.或者已经cache过的部分.这主要是通过tcp_sacktag_skip( ...
- iOS真机调试步骤(Xcode8.0以上版本)(2015年)
方法/步骤(转载:http://jingyan.baidu.com/article/22fe7ced20cc073002617f97.html) 获取真机调试的证书,先在本地生成获取证书的文件,找不到 ...
- Android NFC开发(二)——Android世界里的NFC所具备的条件以及使用方法
Android NFC开发(二)--Android世界里的NFC所具备的条件以及使用方法 NFC的应用比较广泛,而且知识面也是比较广的,所以就多啰嗦了几句,我还还是得跟着官方文档:http://dev ...
- Android特效专辑(九)——仿微信雷达搜索好友特效,逻辑清晰实现简单
Android特效专辑(九)--仿微信雷达搜索好友特效,逻辑清晰实现简单 不知不觉这个春节也已经过完了,遗憾家里没网,没能及时给大家送上祝福,今天回到深圳,明天就要上班了,小伙伴们是不是和我一样呢?今 ...