Redis - NoSQL数据库技术(一)
NoSQL入门概述(一)
作者 : Stanley 罗昊
【转载请注明出处和署名,谢谢!】
什么是NoSQL
NoSQL(NoSQL - Not Only SQL),意“不仅仅是SQL”;
泛指非关系型的数据库;
随着互联网web2.0网站的兴起,传统的关系数据库在应对web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站以及显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展;
NoSQL数据库的产生就是为了解决大规模数据集合,多重复数据种类带来的挑战,尤其是大数据应用难题,包括大规模数据的存储。
(例如谷歌或Facebook每天为澳门的用户手机万亿比特的数据),这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展;
为什么用NoSQL
在最早的项目研发时期,是单机MySQL的美好年代,无非就是三层架构,dao层直接访问数据库获取数据后响应给客户即可,非常简单;
但是随着时代的改变,以及互联网用户越来越多,大规模的互联网公司兴起,数据量急剧增加,再用最早的开发模式,已经完全满足不了现在时代的需求了;
所以就nosql(非关系型数据库)横空出世,来解决大数据量情况下提高数据库读取效率,从而提升系统性能以及客户体验;
在早期的系统,dao层直接访问数据库获取数据,但是现在时代的变迁,这样的方式在数据量大的情况下,效率非常非常的查,你无论怎么优化都是徒劳;
nosql出现后,犹如在数据库前面加了一堵墙,dao层先访问Redis,Redis再访问数据库;
数据库读出来的数据先存入Redis,获取数据的时候,直接从Redis中获取即可,不用再通过数据库从内存中读写;
今天我们可以通过第三方平台(如:Google,Facebook等)可以很容易的访问和抓取数据,用户的个人信息,社交网络,地理位置,用户产生的数据和用户操作日志以及成倍的增加;
我们如果要对这些用户数据进行挖掘,MySQL数据库以及不合适这些应用了,NoSQL数据库发展却能很好的出列这些大数据;
单机MySQL的美好年代
在最早的javaweb开发应用程序中,无非就是JSP跳JSP,一个JSP处理用户并且响应,另外一个JSP发出请求,请求别的JSP,再往后,JSP跳Serclet,Serclet掉业务逻辑层的方法,业务逻辑掉数据访问层,数据访问层去请求数据库发起事物;
在90年代,一个网站的访问量都不大,用单个数据库完全可以轻松应付;
在那个时候,更多的都是静态网页,动态交互类型的网站不多;
在那个时候程序的划分也非常简单:
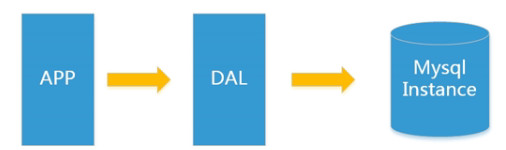
随着时代的变迁,数据的总量总有一天会撑破这个机器,数据库读取也就是查询效率讲会变得非常非常低;
建立索引也是会占用磁盘空间的,数据量越大,你索引越多,时间久了机器就是受不了你这样折腾了;
还有一个访问量(读写混合)一个数据库是受不了的,你读取跟插入数据都是在同一个数据库,这样数据库也是承受不了的(数据量大的情况下);
所以,问题已经列出来了,我们就要解决,要去优化这些问题,提高性能;
在以上这种开发模式,数据量在小于1w是可以满足的,自己用用,或访问量不大的情况下是没有问题的,自己做练习什么的都可以,但是进入企业,就不可以再这么用了;
Redis(缓存)+MySQL+垂直拆分
随着数据量大,读写都是在同一台机器上,扛不住了以后呢,项目架构也就进行了改变:

跟上一张图标对比,是只有一个MySQL数据库,并且现在我们还在MySQL前面档了一层Cache(这里理解成Redis【缓存】),换句话说,之前是DAO层直接去访问数据库,现在DAO层直接去Redis里面;
是不是有点像替数据库挡了一层,大家都指定,对数据库伤害比较大的就是频繁的查询,如果频繁查询的刚好还是一些固定的顺序,我们是不是可以把他摘出来放到缓存里面(Redis);
mysql还有一个垂直拆分,言下之意就是,你一个数据装不住了,你拆开了以后,例如,买家跟卖家被分成两个库,这样的话,数据库的压力就被分担了一些;
MySQL主从读写分离
举个例子,现在是一台机器一个数据库,我现在要求一台机器变成五个数据库,那么,其中的一台数据库作为主库,另外四台作为从库,我插入一条数据是给主库,主库这个时候需要同步另外四个从库,比如我主库里面有 a b c,这个时候我向里面查一个d,这个时候主库就需要向另外四个从库也添加一个d来保持同步;
也可以理解为主从复制,主表里面有什么东西,我从表需要迅速的复制粘贴进来;
读写分离,顾名思义,读就是查询,写就是增 删 改,在我们自己做练习的时候,增删改查一直都是同一台机器或同一个数据库,但是在实际开发当中,这种情况是不允许的,因为非常影响效率;
所以又有一个数据库是只做查询,另外一个数据库是只做增 删 改,这就是读写分离,所以就造成了下面这张图:
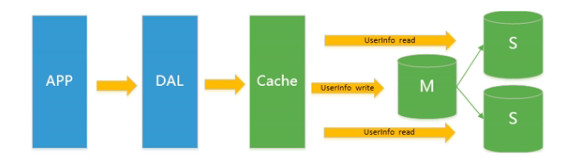
由于数据库的写入压力增加,Redis只能缓解数据库的读取压力,读写集中在一个数据库上让数据库不堪重负,大部分网站开始使用主从赋值技术来达到读写分离,提高读写性能和读库的可扩展性;
之前是光在mysql前面档了一个缓存,现在,在缓存背后又出现了数据库的拆分,变成了读写分离了,M代表主表,S代表从表;
什么概念呢?
就是,对于一个数据库的信息,写的操作都放到M(主)库了,读的操作都去从库去度,这样的话,存载的数据被分割以后,就可以大大的缓解数据库的压力;
分库分表+水平拆分+mysql集群
经过前几次的拆分,改变,读写分离,往后发现又扛不住了,这个时候,集群就出来了;
在Redis的高速缓存,MySQL的主从复制,读写分离的基础上,这时,MySQL主库的读写压力开始出现瓶颈,而数据量的持续猛增,由于MyISAM使用表锁,在高并发下会出现严重的锁问题,大量的高并发MySQL应用开始使用InnoDB引擎代替MyISAM;
同时,开始流行使用分表分库来缓解写压力和数据库增长的扩展问题,这个时候,分表分库就成了一个热门的技术,是面试的热门问题也是业界讨论的热门技术问题;
也就是在这个时候MySQL推出了还不太稳定的表分区,这也给技术实力一般的公司带来了希望,虽然MySQL推出MySQL Cluster集群,但性能也不能很好满足互联网的需求,只是在高可靠性上提供非常大的保障;

我们可以发现,以上图就用了数据库的集群,三个数据库各司其职,每个数据库存放的是整个项目数据的3分之1,频繁查询的数据库单独列出一个库,经常不用的数据也独立出来放在一个数据库中;
如今的项目结构
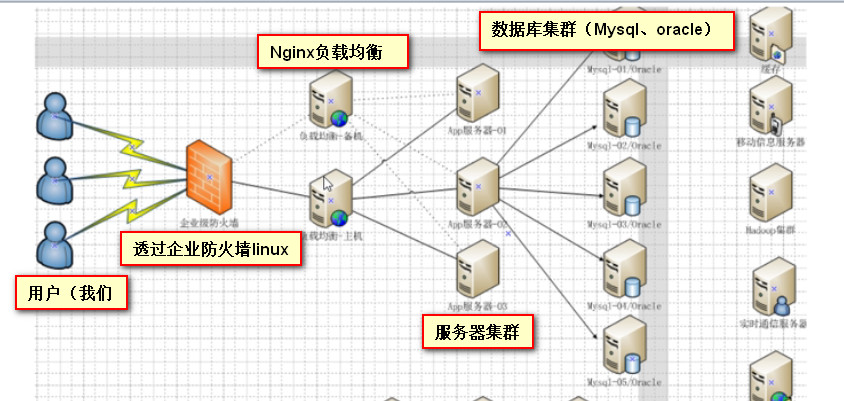
首先,三个蓝色的小人人就点客户,通过企业防火墙Linux,往后就是负载均衡的主备Nginx,做这个负载均衡、反向代理的一个;
所以说在真正的项目研发的时候,你是不可能先经过服务器的,而是先经过Nginx;
后面就是一大堆应用服务器的集群,也可以理解为tomcat的集群,一只猫带不动这个项目,那么就一群猫来带,这样就实现了高可用,负载均衡以及服务器的集群;
再往后,就是数据库的集群了;
今日感悟:
当一个人可以轻松做一件事情的时候,你自己也这么认为自己也可以;
那么你就大错特错了
Redis - NoSQL数据库技术(一)的更多相关文章
- CouchBase数据库-一个较新的、发展迅速的nosql数据库技术
couchbase是一个较新的.发展迅速的nosql数据库技术.2014年,viber宣布使用couchbase替换mongodb,以适应10亿级的用户量,目前,couchbase已大量运用于生产环境 ...
- NoSQL数据库技术特性解析之文档数据库
现今云计算的从业人员对NoSQL一词并不感到陌生,虽然很多技术人员都长期从事关系数据库的工作,但现在他们对NoSQL技术充满期待.对于企业来说,从关系型数据库到NoSQL数据库转变绝对是个需要深思熟虑 ...
- 转 开启“大数据”时代--大数据挑战与NoSQL数据库技术 iteye
一直觉得“大数据”这个名词离我很近,却又很遥远.最近不管是微博上,还是各种技术博客.论坛,碎碎念大数据概念的不胜枚举. 在我的理解里,从概念理解上来讲,大数据的目的在于更好的数据分析,否则如此大数据的 ...
- Redis Nosql数据库
Redis是一个key-value存储系统.和Memcached类似.可是攻克了断电后数据全然丢失的情况.并且她支持很多其它无化的value类型.除了和string外,还支持lis ...
- NoSQL数据库技术实战-第1章 NoSQL与大数据简介 NoSQL数据库的类型
键值存储数据库临时性:如Memcached.临时性的键值数据库把数据存储在内存中,在两种情况下会造成上数据的丢失,一是断电,而是数据内容超出内存大小.这种处理的好处是非常快.永久型:如Tokyo Ty ...
- NoSQL数据库技术实战-第1章 NoSQL的数据一致性 传统关系型数据库的ACID
在看着章节的时候,我简单的回顾了一下关系型数据库的事务处理的ACID原则,其中原子性和持久性比较好理解.由于以前没有深入去研究.关于一致性和隔离性上我产生了疑问,在整理后分析如下: 一致性:书中所 ...
- NoSQL数据库技术实战-第1章 NoSQL与大数据简介 NoSQL产生的原因
NoSQL产生的原因: 关系型数据库不擅长的操作,是NoSQL应运而生的原因: 大量的数据写入操作书上写的是“大量数据的写入操作“,我理解的应该是“大量的数据写入操作”,因为大量的数据写入操作才会引起 ...
- SequoiaDB创始人:比MongoDB领先一到两年 打造企业级NoSQL数据库
CSDN.NET 这几年来, NoSQL数据库凭借其易扩展.高性能.高可用.数据模型灵活等特色吸引到了大量新兴互联网公司的青睐,包括国内的淘宝.新浪.京东商城.360.搜狗等都已经在局部尝试NoS ...
- 2018年阿里云NoSQL数据库大事盘点
NoSQL一词最早出现在1998年.2009年Last.fm的Johan Oskarsson发起了一次关于分布式开源数据库的讨论,来自Rackspace的Eric Evans再次提出了NoSQL概念, ...
随机推荐
- sql语句联表更新(从一个数据库中的一张表更新到另一个数据库的另一张表)
一.sql server数据库写法: update a set a.ksgmm=b.ksgmm,a.ksgm=b.ksgm,a.scztm=b.scztm,a.sczt=b.sczt from lan ...
- jquery和ajax的关系详细介绍【转】
jquery和ajax的关系详细介绍 http://www.jb51.net/article/43965.htm
- OpenApi开放平台架构实践
背景 随着业务的发展,越来越多不同系统之间需要数据往来,我们和外部系统之间产生了数据接口的对接.当然,有我们提供给外部系统(工具)的,也有我们调用第三方的.而这里重点讲一下我们对外的接口. 目前,我们 ...
- 什么是分布式锁及正确使用redis实现分布式锁
分布式锁 分布式锁其实可以理解为:控制分布式系统有序的去对共享资源进行操作,通过互斥来保持一致性. 举个不太恰当的例子:假设共享的资源就是一个房子,里面有各种书,分布式系统就是要进屋看书的人,分布式锁 ...
- 树莓派+花生棒+leanote搭建自己的笔记服务器
背景 对于一个程序猿来说.女朋友可以(暂时)没有,但是不能没有一个很好的记笔记的应用.因为记笔记可以帮助自己积累学习提升自己.每一次回头看自己记得笔记,你都会有新的理解. 也许有人会说,用有道云啊,有 ...
- JAVA中写时复制(Copy-On-Write)Map实现
1,什么是写时复制(Copy-On-Write)容器? 写时复制是指:在并发访问的情景下,当需要修改JAVA中Containers的元素时,不直接修改该容器,而是先复制一份副本,在副本上进行修改.修改 ...
- spring中bean的scope属性理解
bean的scope属性有prototype,singleton,request, session几个属性 spring和struts2整合的时候,struts2的action要配置成scope=&q ...
- struts2(二)---ModelDriven模型驱动
这篇文章是在上一篇文章(http://blog.csdn.net/u012116457/article/details/48194905)的基础上写的,大家可以先快速阅读一下上一篇. 这篇文章用来写一 ...
- yii批量插入的方法
public function insertSeveral($table, $array_columns) { $sql = ''; $params = array(); $i = 0; foreac ...
- websocket(一)--握手
最近在琢磨怎么实现服务端的消息推送,因为以前都是通过客户端请求来获取信息的,如果需要实时信息就得轮询,比如通过ajax不停的请求. websocket相当于对HTTP协议进行了升级,客户端和服务端通过 ...