【原】无脑操作:ElasticSearch学习笔记(01)
开篇来自于经典的“保安的哲学三问”(你是谁,在哪儿,要干嘛)
问题一、ElasticSearch是什么?有什么用处?
答:截至2018年12月28日,从ElasticSearch官网(https://www.elastic.co/cn/products)上,得知:ElasticSearch是基于 JSON 的分布式搜索和分析引擎,专为实现水平扩展、高可靠性和管理便捷性而设计。用于搜索、分析和存储您的数据。
问题二、ElasticSearch的由来?
答:大约在2010年,一个叫Shay Banon的待业工程师跟随他的新婚妻子来到伦敦,他的妻子想在伦敦学习做一名厨师。而他在伦敦寻找工作的期间,接触到了Lucene的早期版本,他想为自己的妻子开发一个方便搜索菜谱的应用。直接使用Lucene构建搜索会有很多的坑以及重复性的工作,所以Shay便在Lucene的基础上不断进行抽象来让Java程序嵌入搜索变得更容易一些,经过一段时间的打磨,就诞生了他的第一个开源作品,他给自己的这个作品起了个名字,叫 “Compass”,中文即“指南针”的意思。之后,Shay找到了一份新工作,新工作是处在一个高性能分布式的开发环境中。他在工作中渐渐发现,越来越需要一个易用的高性能、实时、分布式搜索服务,于是他决定重写Compass,将它从一个库打造成了一个独立的server,并将其改名为Elasticsearch。Elasticsearch发布的第一个版本是在2010年的二月份,从那之后,Elasticsearch便成了Github上最受人瞩目的项目之一,并且很快就有超过300名开发者加入进来贡献了自己的代码。后来Shay和另一位合伙人成立了公司专注打造Elasticsearch,他们对Elasticsearch进行了一些商业化的包装和支持。但是,Elasticsearch承诺,永远都将是开源并且免费的。不过悲剧的是,Shay承诺为妻子开发的菜谱搜索应用,到现在还没做出来……(划重点:ElasticSearch基于Lucene)
问题三、ElasticSearch有什么功能?有什么优势?
答:截至2018年12月28日,从ElasticSearch官网(https://www.elastic.co/cn/products/elasticsearch)上,得知:Elasticsearch 是一个分布式、Restful风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。作为 Elastic Stack 的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况。具备存储、查询和分析功能。具备速度、可扩展性、弹性、灵活性、操作友好、客户端库丰富等优势,是开源的、分布式、基于 Restful API、支持 PB 甚至更高数量级的搜索引擎工具。
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
1、ElasticSearch的安装及结构
ElasticSearch支持Windows安装,直接到官网的下载页面(https://www.elastic.co/cn/downloads/elasticsearch)下载即可。
注意,如果使用ELK全家桶,官方建议ElasticSearch、Logstash、Kibana三个产品选择同一版本号。截至2018年12月28日,ElasticSearch的最新版本是6.5.4。本篇笔记使用的是6.5.0。下载后放在D:\ELK目录下。

bin:elasticsearch的启动脚本等
config:配置文件目录
data:当前节点的分片数据
lib:运行依赖的jar包
logs:日志文件目录
modules:模块库
plugins:插件目录
2、ElasticSearch的运行
Windows版本的Elasticsearch运行还是很简单的,直接在bin目录下,找到elasticsearch.bat这个批处理文件,双击运行就可以了。当然也可以通过命令行窗口进入到该目录下,输入elasticsearch回车进行执行。
出现如下信息说明Elasticsearch已经启动起来了,并且运行在本机的9200端口上。
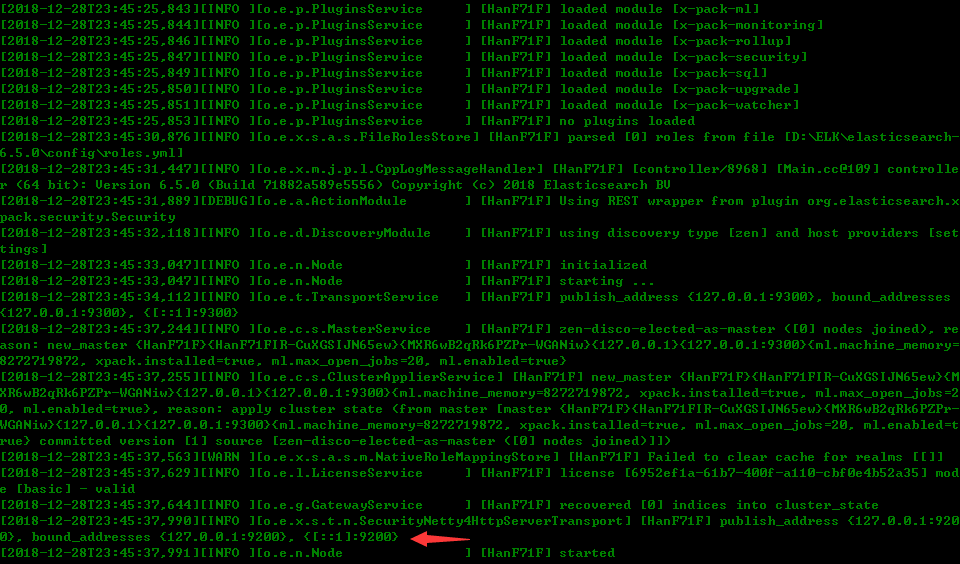
在浏览器的地址栏中输入:localhost:9200,如果能看到如下信息,说明启动成功
{
"name" : "HanF71F",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "kYp2rOofTwWN1-kj7Qjw_A",
"version" : {
"number" : "6.5.0",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "816e6f6",
"build_date" : "2018-11-09T18:58:36.352602Z",
"build_snapshot" : false,
"lucene_version" : "7.5.0",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
cluster_name: ElasticSearch配置的集群名称,默认是elasticsearch,es服务会通过广播方式自动连接在同一网段下的es服务,通过多播方式进行通信,同一网段下可以有多个集群,通过集群名称这个属性来区分不同的集群。
cluster_uuid:ElasticSearch配置的集群唯一编号
build_flavor:编译特点
lucene_version:ElasticSearch基于lucene的,lucene的版本号
3、ElasticSearch的工具
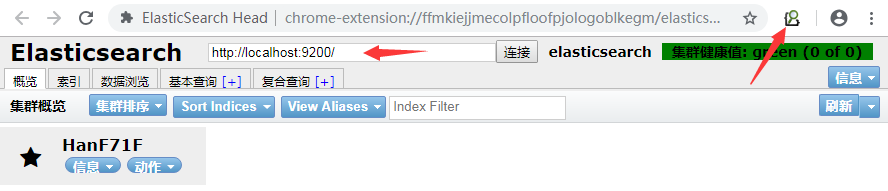
① 结合Chrome浏览器的ElasticSearchHead插件使用
下载名为chromeFOR.COM_elasticsearch-head_v0.1.3.crx的Chrome插件,安装后,在Chrome浏览器的右上角点击Elastic Search Head这个图标即可使用
② 结合Kibana工具使用
个人觉得Kibana是和ElasticSearch结合是很好的,毕竟都是一家的产品。Windows下的Kibana使用也很简单,直接下载同ElasticSearch一样版本的Kibana(https://www.elastic.co/downloads/kibana)

直接在bin目录下,找到kibana.bat这个批处理文件,双击运行就可以了。当然也可以通过命令行窗口进入到该目录下,输入kibana回车进行执行。
出现如下信息说明Kibana已经启动起来了,并且运行在本机的5601端口上。

在浏览器的地址栏中输入:localhost:5601,如果能看到如下信息,说明Kibana启动成功。
4、 ElasticSearch的基本术语
将ElasticSearch和关系型数据库做一个类比
| 关系型数据库 | ⇒ | 数据库(Database) | ⇒ | 表(Table) | ⇒ | 行(Rows) | ⇒ | 列(Columns) |
| ElasticSearch | ⇒ | 索引(Index) | ⇒ | 类型(Type) | ⇒ | 文档(Docments) | ⇒ | 字段(Fields) |
一个ElasticSearch集群可以包含多个索引(数据库),一个索引中可以包含多个类型(表),一个类型中可以包含多个文档(行),一个文档中可以包含多个字段(列)。
Elasticsearch可以理解为是面向文档型数据库。数据用JSON作为文档序列化的格式。
① Near Realtime(NRT):近实时的意思,表示从写入数据到数据可以被搜索有一个小延迟(大概1秒);基于es执行搜索和分析可以达到秒级。
② Cluster:集群,包含多个节点,每个节点属于哪个集群是通过配置(集群名称,默认是elasticsearch)来决定的,对于中小型应用来说,开始阶段常常一个集群对应一个节点。
③ Node:节点,集群中的一个节点,节点也有一个名称(默认是随机分配的),在执行运维管理操作时节点名称很重要,默认节点会加入一个名称为“elasticsearch”的集群,如果直接启动一堆节点,那么它们会自动组成一个elasticsearch集群,当然一个节点也可以组成一个elasticsearch集群。
④ Document&field:文档,es中的最小数据单元,一个document可以是一条客户数据,一条商品分类数据,一条订单数据,通常用JSON数据结构表示,每个index下的type中,都可以去存储多个document。一个document里面有多个field,每个field就是一个数据字段。
⑤ Index:索引,包含一堆有相似结构的文档数据,比如可以有一个客户索引,商品分类索引,订单索引,索引有一个名称。一个index包含很多document,一个index就代表了一类类似的或者相同的document。比如说建立一个product index,商品索引,里面可能就存放了所有的商品数据,所有的商品document。
⑥ Type:类型,每个索引里都可以有一个或多个type,type是index中的一个逻辑数据分类,一个type下的document,都有相同的field,比如博客系统,有一个索引,可以定义用户数据type,博客数据type,评论数据type。
⑦ Shard:单台机器无法存储大量数据,es可以将一个索引中的数据切分为多个shard,分布在多台服务器上存储。有了shard就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞吐量和性能。每个shard都是一个lucene index。
⑧ Replica:任何一个服务器随时可能故障或宕机,此时shard可能就会丢失,因此可以为每个shard创建多个replica副本。replica可以在shard故障时提供备用服务,保证数据不丢失,多个replica还可以提升搜索操作的吞吐量和性能。primary shard(建立索引时一次设置,不能修改,默认5个),replica shard(随时修改数量,默认1个),默认每个索引10个shard,5个primary shard,5个replica shard,最小的高可用配置,是2台服务器。
5、ElasticSearch的基本使用(CRUD)
首先对Restful风格的动作有一个了解:GET(查询操作),POST(新增/修改操作),PUT(修改操作),DELETE(删除操作)
下列命令均在Kibana的DevTools中执行,DevTools中输入关键字有相应的提示,很不错。
① 检查集群的健康状况
GET /_cat/health?v
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1546176515 13:28:35 elasticsearch green 1 1 1 1 0 0 0 0 - 100.0%
② 查看集群中所有的索引
GET /_cat/indices?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open .kibana_1 qqZcESKyTvCWJjF7ToyUWw 1 0 1 0 5.1kb 5.1kb
③ 创建索引(可以使用ElasticSearchHead插件的图形化创建方式,也可以手写命令)
PUT /study_elasticsearch?pretty
#! Deprecation: the default number of shards will change from [5] to [1] in 7.0.0; if you wish to continue using the default of [5] shards,
you must manage this on the create index request or with an index template
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "study_elasticsearch"
}
创建后再次执行查看索引的命令,可以看到这时有两个索引存在了。
GET /_cat/indices?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open .kibana_1 qqZcESKyTvCWJjF7ToyUWw 1 0 1 0 5.1kb 5.1kb
yellow open study_elasticsearch P1yCgFQiS1Si2Nc0IlZflA 5 1 0 0 1.1kb 1.1kb
④ 删除索引
DELETE /study_elasticsearch?pretty
{
"acknowledged" : true
}
删除后再次执行查看索引的命令,可以看到这时剩一个索引存在了。
GET /_cat/indices?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open .kibana_1 qqZcESKyTvCWJjF7ToyUWw 1 0 1 0 5.1kb 5.1kb
⑤ 新增文档
PUT /study_elasticsearch/person/1
{
"name" : "zhang yang",
"age" : 21,
"job" : "boss"
}
{
"error": {
"root_cause": [
{
"type": "cluster_block_exception",
"reason": "blocked by: [FORBIDDEN/12/index read-only / allow delete (api)];"
}
],
"type": "cluster_block_exception",
"reason": "blocked by: [FORBIDDEN/12/index read-only / allow delete (api)];"
},
"status": 403
}
从错误信息清晰的看到是索引只读的提示,所以考虑放开索引的只读设置。
PUT _settings
{
"index": {
"blocks": {
"read_only_allow_delete": "false"
}
}
}
{
"acknowledged" : true
}
再次尝试新增文档
PUT /study_elasticsearch/person/1
{
"name" : "zhang yang",
"age" : 21,
"job" : "boss"
}
{
"_index" : "study_elasticsearch",
"_type" : "person",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
PUT /study_elasticsearch/person/2
{
"name" : "zhang xiong jia",
"age" : 20,
"job" : "employee"
}
{
"_index" : "study_elasticsearch",
"_type" : "person",
"_id" : "2",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
PUT /study_elasticsearch/person/3
{
"name" : "wu qing qing",
"age" : 22,
"job" : "manager"
}
{
"_index" : "study_elasticsearch",
"_type" : "person",
"_id" : "3",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
注意,此时的文档版本version为1
⑥ 查询文档数量
GET /study_elasticsearch/person/_count
{
"count" : 3,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
}
}
⑦ 查询文档(不加任何查询条件,本篇用的都是Search Lite API的写法)
GET /study_elasticsearch/person/_search
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 3,
"max_score" : 1.0,
"hits" : [
{
"_index" : "study_elasticsearch",
"_type" : "person",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"name" : "zhang xiong jia",
"age" : 20,
"job" : "employee"
}
},
{
"_index" : "study_elasticsearch",
"_type" : "person",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"name" : "zhang yang",
"age" : 21,
"job" : "boss"
}
},
{
"_index" : "study_elasticsearch",
"_type" : "person",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"name" : "wu qing qing",
"age" : 22,
"job" : "manager"
}
}
]
}
}
注意:对某个索引(Index)下某个类型(Type)没加任何条件的查询,结果默认会展示出前20条文档(Documents)
⑧ 查询文档(带查询条件,本篇用的都是Search Lite API的写法)
直接通过id获取文档:
GET /study_elasticsearch/person/1
{
"_index" : "study_elasticsearch",
"_type" : "person",
"_id" : "1",
"_version" : 1,
"found" : true,
"_source" : {
"name" : "zhang yang",
"age" : 21,
"job" : "boss"
}
}
通过查询字段的值获取文档:(按age赋值22查询,找到了吴局)
GET /study_elasticsearch/person/_search?q=age:22
{
"took" : 10,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 1.0,
"hits" : [
{
"_index" : "study_elasticsearch",
"_type" : "person",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"name" : "wu qing qing",
"age" : 22,
"job" : "manager"
}
}
]
}
}
通过查询字段的值获取文档:(按name赋值zhang查询,找到了名字中有zhang的大小张行长)
GET /study_elasticsearch/person/_search?q=name:zhang
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 2,
"max_score" : 0.2876821,
"hits" : [
{
"_index" : "study_elasticsearch",
"_type" : "person",
"_id" : "2",
"_score" : 0.2876821,
"_source" : {
"name" : "zhang xiong jia",
"age" : 20,
"job" : "employee"
}
},
{
"_index" : "study_elasticsearch",
"_type" : "person",
"_id" : "1",
"_score" : 0.2876821,
"_source" : {
"name" : "zhang yang",
"age" : 21,
"job" : "boss"
}
}
]
}
}
⑨ 更新文档(替换)
PUT /study_elasticsearch/person/1
{
"name" : "hong zi jun",
"age" : 21,
"job" : "CEO"
}
{
"_index" : "study_elasticsearch",
"_type" : "person",
"_id" : "1",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}
注意:此时id为1的这条文档的版本version变成了2,文档的内容也变成了洪行长
GET /study_elasticsearch/person/1
{
"_index" : "study_elasticsearch",
"_type" : "person",
"_id" : "1",
"_version" : 2,
"found" : true,
"_source" : {
"name" : "hong zi jun",
"age" : 21,
"job" : "CEO"
}
}
这种替换的方式做更新,需要替换的内容和原先的内容字段一致,如果不一致就会用替换内容替换掉原先的内容
PUT /study_elasticsearch/person/1
{
"name" : "ye yu",
"gender" : "female"
}
{
"_index" : "study_elasticsearch",
"_type" : "person",
"_id" : "1",
"_version" : 3,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}
再次查询,发现person的字段和内容均发生了变化,变成叶阿姨了。显然,这种替换方式的缺点在于全量替换了,不想替换的也被替换了。
GET /study_elasticsearch/person/1
{
"_index" : "study_elasticsearch",
"_type" : "person",
"_id" : "1",
"_version" : 3,
"found" : true,
"_source" : {
"name" : "ye yu",
"gender" : "female"
}
}
⑩ 更新文档(更新)
先把id为1的数据替换回去
PUT /study_elasticsearch/person/1
{
"name" : "zhang yang",
"age" : 21,
"job" : "boss"
}
{
"_index" : "study_elasticsearch",
"_type" : "person",
"_id" : "1",
"_version" : 4,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 1
}
GET /study_elasticsearch/person/1
{
"_index" : "study_elasticsearch",
"_type" : "person",
"_id" : "1",
"_version" : 4,
"found" : true,
"_source" : {
"name" : "zhang yang",
"age" : 21,
"job" : "boss"
}
}
使用POST结合_update做更新
POST /study_elasticsearch/person/1/_update
{
"doc" : {
"job" : "CTO"
}
}
{
"_index" : "study_elasticsearch",
"_type" : "person",
"_id" : "1",
"_version" : 5,
"result" : "noop",
"_shards" : {
"total" : 0,
"successful" : 0,
"failed" : 0
}
}
再查询一下,发现id为1的文档的job字段发生了改变,其他的字段及内容没有变化
GET /study_elasticsearch/person/1
{
"_index" : "study_elasticsearch",
"_type" : "person",
"_id" : "1",
"_version" : 5,
"found" : true,
"_source" : {
"name" : "zhang yang",
"age" : 21,
"job" : "CTO"
}
}
⑪ 删除文档
DELETE /study_elasticsearch/person/1
{
"_index" : "study_elasticsearch",
"_type" : "person",
"_id" : "1",
"_version" : 6,
"result" : "deleted",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 5,
"_primary_term" : 1
}
再查询一下,找不到该条文档了
GET /study_elasticsearch/person/1
{
"_index" : "study_elasticsearch",
"_type" : "person",
"_id" : "1",
"found" : false
}
如果是想删除所有的文档,可以如下操作
POST /study_elasticsearch/person/_delete_by_query
{
"query": {
"match_all": {}
}
}
{
"took" : 42,
"timed_out" : false,
"total" : 2,
"deleted" : 2,
"batches" : 1,
"version_conflicts" : 0,
"noops" : 0,
"retries" : {
"bulk" : 0,
"search" : 0
},
"throttled_millis" : 0,
"requests_per_second" : -1.0,
"throttled_until_millis" : 0,
"failures" : [ ]
}
再查询一下,发现没有数据了
GET /study_elasticsearch/person/_search
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 0,
"max_score" : null,
"hits" : [ ]
}
}
至此,最简单基本的操作就讲完了,是不是特别无脑啊(*^_^*)
【原】无脑操作:ElasticSearch学习笔记(01)的更多相关文章
- ElasticSearch学习笔记-01 简介、安装、配置与核心概念
一.简介 ElasticSearch是一个基于Lucene构建的开源,分布式,RESTful搜索引擎.设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便.支持通过HTTP使用JSON进 ...
- 【原】无脑操作:IDEA + maven + Shiro + SpringBoot + JPA + Thymeleaf实现基础授权权限
上一篇<[原]无脑操作:IDEA + maven + Shiro + SpringBoot + JPA + Thymeleaf实现基础认证权限>介绍了实现Shiro的基础认证.本篇谈谈实现 ...
- 【原】无脑操作:IDEA + maven + Shiro + SpringBoot + JPA + Thymeleaf实现基础认证权限
开发环境搭建参见<[原]无脑操作:IDEA + maven + SpringBoot + JPA + Thymeleaf实现CRUD及分页> 需求: ① 除了登录页面,在地址栏直接访问其他 ...
- 【原】无脑操作:EasyUI Tree实现左键只选择叶子节点、右键浮动菜单实现增删改
Easyui中的Tree组件使用频率颇高,经常遇到的需求如下: 1.在树形结构上,只有叶子节点才能被选中,其他节点不能被选中: 2.在叶子节点上右键出现浮动菜单实现新增.删除.修改操作: 3.在非叶子 ...
- 【原】无脑操作:express + MySQL 实现CRUD
基于node.js的web开发框架express简单方便,很多项目中都在使用.这里结合MySQL数据库,实现最简单的CRUD操作. 开发环境: IDE:WebStorm DB:MySQL ------ ...
- SaToken学习笔记-01
SaToken学习笔记-01 SaToken版本为1.18 如果有排版方面的错误,请查看:传送门 springboot集成 根据官网步骤maven导入依赖 <dependency> < ...
- Elasticsearch学习笔记一
Elasticsearch Elasticsearch(以下简称ES)是一款Java语言开发的基于Lucene的高效全文搜索引擎.它提供了一个分布式多用户能力的基于RESTful web接口的全文搜索 ...
- 软件测试之loadrunner学习笔记-01事务
loadrunner学习笔记-01事务<转载至网络> 事务又称为Transaction,事务是一个点为了衡量某个action的性能,需要在开始和结束位置插入一个范围,定义这样一个事务. 作 ...
- PHP操作MongoDB学习笔记
<?php/*** PHP操作MongoDB学习笔记*///*************************//** 连接MongoDB数据库 **////*************** ...
- delphi操作xml学习笔记 之一 入门必读
Delphi 对XML的支持---TXMLDocument类 Delphi7 支持对XML文档的操作,可以通过TXMLDocument类来实现对XML文档的读写.可以利用TXMLDocum ...
随机推荐
- expdb和impdb使用方法
一 关于expdp和impdp 使用EXPDP和IMPDP时应该注意的事项:EXP和IMP是客户端工具程序,它们既可以在客户端使用,也可以在服务端使用. EXPDP和IMPDP是服务端的工具 ...
- iOS 中判断应用程序是否为第一次打开
第一步:在AppDelegate中当应用启动完成后加入一下代码: - (BOOL)application:(UIApplication *)application didFinishLaunching ...
- 附录D——自动微分(Autodiff)
本文介绍了五种微分方式,最后两种才是自动微分. 前两种方法求出了原函数对应的导函数,后三种方法只是求出了某一点的导数. 假设原函数是$f(x,y) = x^2y + y +2$,需要求其偏导数$\fr ...
- Heroku创始人Adam Wiggins发布十二要素应用宣言
Heroku是业内知名的云应用平台,从对外提供服务以来,他们已经有上百万应用的托管和运营经验.前不久,创始人Adam Wiggins根据这些经验,发布了一个“十二要素应用宣言(The Twelve-F ...
- 从JVM内存管理的角度谈谈JAVA类的静态方法和静态属性
在JVM中,内存分为两个部分,Stack(栈)和Heap(堆),这里,我们从JVM的内存管理原理的角度来认识Stack和Heap,并通过这些原理认清Java中静态方法和静态属性的问题. 一般,JVM的 ...
- mvn -DskipTests和-Dmaven.test.skip=true区别
在使用mvn package进行编译.打包时,Maven会执行src/test/java中的JUnit测试用例,有时为了跳过测试,会使用参数-DskipTests和-Dmaven.test.skip= ...
- 图形验证码知识点整理 Object.prototype.toString.call()等
使用typeof bar === "object"检测”bar”是否为对象有什么缺点?如何避免?这是一个十分常见的问题,用 typeof 是否能准确判断一个对象变量,答案是否定的, ...
- 玩转web之ligerui(一)---ligerGrid重新指定url
请珍惜小编劳动成果,该文章为小编原创,转载请注明出处. 在特定情况下,我们需要重新指定ligerGrid的url来获取不同的数据,在这里我说一下我用的方法: 首先先定义一个全局变量,然后定义liger ...
- 数据分析工具Pandas
参考学习资料:http://pandas.pydata.org 1.什么是Pandas? Pandas的名称来自于面板数据(panel data)和Python数据分析(data analys ...
- DDD实战进阶第一波(十一):开发一般业务的大健康行业直销系统(实现经销商代注册用例与登录令牌分发)
前两篇文章主要实现了经销商代注册的仓储与领域逻辑.经销商登录的仓储与相关逻辑,这篇文章主要讲述经销商代注册的用例与经销商登录的查询功能. 一.经销商代注册用例 在经销商代注册用例中,我们需要传递经销商 ...