zookeeper快速入门
一。zookeeper简介
- zookeeper 是apache旗下的hadoop子项目,它一个开源的,分布式的服务协调器。同样通过zookeeper可以实现服务间的同步与配置维护。通常情况下,在分布式应用开发中,协调服务这样的工作不是件容易的事,很容易出现死锁,不恰当的选举竞争等。zookeeper就是担负起了分布式协调的重担。
- zookeeper的特点:
- 使用简单:ZooKeeper允许分布式程序通过一个类似于标准文件系统的共享的层次化名称空间来相互协调。名称空间由数据寄存器(称为znode)组成,在ZooKeeper中,它们类似于文件和目录。与为存储而设计的典型文件系统不同,ZooKeeper数据保存在内存中,这意味着ZooKeeper可以达到高吞吐量和低延迟数
- 同步与复制:组成ZooKeeper服务的服务器必须互相有感知。客户端连接到一个ZooKeeper服务器。客户端维护一个TCP连接,通过它发送请求、获取响应、获取观察事件和发送心跳。如果连接到服务器的TCP连接中断,客户端将连接到另一个服务器。
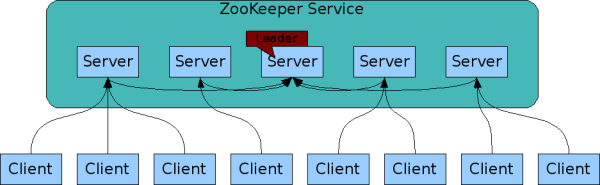
- 有序
- 在进行大量读操作时,运行速度奇快
- ZooKeeper提供的名称空间非常类似于标准文件系统。名称是由斜杠(/)分隔的路径元素序列。在ZooKeeper的名称空间中,每一个节点都是通过一条路径来标识的。如图所示 :
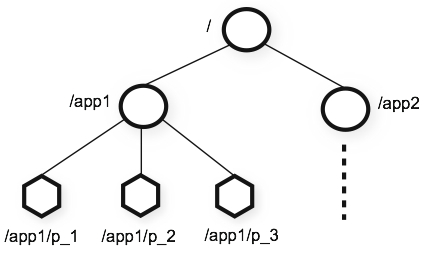
- 当然zookeeper与标准文件系统不同的是,它的节点分为永久节点和临时节点(随着会话断开而消失)
- 客户端的节点都会被设置一个监控,当znode发生更改时,这个变化会通知所有客户端然后删除
二。zookeeper快速上手
- 下载zookeeper:地址,并解压,然后得到如下目录:
- 进入conf目录下我们复制一份zoo_sample.cfg并改名为zoo.cfg
- cp zoo_sample.cfg zoo.cfg
运行 vi zoo.cfg 我们先来看看配置
- # The number of milliseconds of each tick
- tickTime=2000
- # The number of ticks that the initial
- # synchronization phase can take
- initLimit=10
- # The number of ticks that can pass between
- # sending a request and getting an acknowledgement
- syncLimit=5
- # the directory where the snapshot is stored.
- # do not use /tmp for storage, /tmp here is just
- # example sakes.
- dataDir=../zookeeper-data
- # the port at which the clients will connect
- clientPort=2181
- # the maximum number of client connections.
- # increase this if you need to handle more clients
- #maxClientCnxns=60
- #
- # Be sure to read the maintenance section of the
- # administrator guide before turning on autopurge.
- #
- # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
- #
- # The number of snapshots to retain in dataDir
- #autopurge.snapRetainCount=3
- # Purge task interval in hours
- # Set to "0" to disable auto purge feature
- #autopurge.purgeInterval=1
在这里我们保持默认配置先不变。更改一下dataDir这个值,注意:先在zookeeper的根目录下把该文件夹建好
- 进入bin目录下启动zookeeper。注意:再此之前必须配置JAVA_HOME的环境变量
- ./zkServer.sh start
- 紧接着在bin目录下运行客户端
- ./zkCli.sh -server 127.0.0.1:
运行过后会得到如下提示界面:
- Connecting to localhost:2181
- log4j:WARN No appenders could be found for logger (org.apache.zookeeper.ZooKeeper).
- log4j:WARN Please initialize the log4j system properly.
- Welcome to ZooKeeper!
- JLine support is enabled
- [zkshell: 0]
紧接着我们运行help命令可以看看当前可以运行哪些指令:
- [zkshell: 0] help
- ZooKeeper host:port cmd args
- get path [watch]
- ls path [watch]
- set path data [version]
- delquota [-n|-b] path
- quit
- printwatches on|off
- create path data acl
- stat path [watch]
- listquota path
- history
- setAcl path acl
- getAcl path
- sync path
- redo cmdno
- addauth scheme auth
- delete path [version]
- setquota -n|-b val path
其中 get:为获取节点数据 , ls查看当前节点的子节点 create:创建节点 delete:删除节点 set设置节点的内容数据
下面我们依次运行如下命令看看:
- [zkshell: ] ls /
- [zookeeper]
- [zkshell: ] create /zk_test my_data
- Created /zk_test
- [zkshell: ] ls /
- [zookeeper, zk_test]
- [zkshell: ] get /zk_test
- my_data
- cZxid =
- ctime = Fri Jun :: PDT
- mZxid =
- mtime = Fri Jun :: PDT
- pZxid =
- cversion =
- dataVersion =
- aclVersion =
- ephemeralOwner =
- dataLength =
- numChildren =
- [zkshell: ] set /zk_test junk
- cZxid =
- ctime = Fri Jun :: PDT
- mZxid =
- mtime = Fri Jun :: PDT
- pZxid =
- cversion =
- dataVersion =
- aclVersion =
- ephemeralOwner =
- dataLength =
- numChildren =
- [zkshell: ] get /zk_test
- junk
- cZxid =
- ctime = Fri Jun :: PDT
- mZxid =
- mtime = Fri Jun :: PDT
- pZxid =
- cversion =
- dataVersion =
- aclVersion =
- ephemeralOwner =
- dataLength =
- numChildren =
- [zkshell: ] delete /zk_test
- [zkshell: ] ls /
- [zookeeper]
- [zkshell: ]
- [zkshell: ] ls /
三。使用java操作zookeeper
通常情况下我们可以使用zookeeper提供的原生jar包操作zookeeper服务,但是zookeeper原生方式操作很麻烦,不过我们可以用第三方的组件来操作zookeeper,比如说:zkClient 或者curator。curator提供了更丰富的功能,但是使用起来比zkClient稍微复杂一点。关于curator我们后续篇幅会介绍,这里先贴出zkClient的例子:
添加zkClient的依赖:
- // https://mvnrepository.com/artifact/com.101tec/zkclient
- compile group: 'com.101tec', name: 'zkclient', version: '0.10'
示例代码:
- package com.bdqn.lyrk.register;
- import org.I0Itec.zkclient.IZkDataListener;
- import org.I0Itec.zkclient.ZkClient;
- import org.apache.zookeeper.CreateMode;
- import java.io.IOException;
- public class ResgisterApplication {
- public static void main(String[] args) throws IOException {
- ZkClient zkClient = new ZkClient("localhost:2181", 1000);
- //获取指定路径的子节点个数
- System.out.println(zkClient.countChildren("/"));
- //如果节点存在则删除该节点
- if (zkClient.exists("/dubbo")) {
- zkClient.delete("/dubbo");
- }
- //创建永久的节点
- String nodeName = zkClient.create("/dubbo", "{\"name\":\"admin\"}", CreateMode.PERSISTENT);
- System.out.println(nodeName);
- //创建临时节点
- zkClient.createEphemeralSequential("/dubbo/test", "a");
- zkClient.createEphemeralSequential("/dubbo/test", "b");
- //读取节点数据
- System.out.println(zkClient.readData("/dubbo").toString());
- //订阅dubbo数据的变化
- zkClient.subscribeDataChanges("/dubbo", new IZkDataListener() {
- @Override
- public void handleDataChange(String dataPath, Object data) throws Exception {
- System.out.println(dataPath+"节点数据发生变化。。。");
- }
- @Override
- public void handleDataDeleted(String dataPath) throws Exception {
- System.out.println(dataPath+"节点数据被删除....");
- }
- });
- //订阅dubbo子节点的变化
- zkClient.subscribeChildChanges("/dubbo",(parentPath, currentChilds) -> System.out.println("dubbo节点发生变化"));
- //更新dubbo节点的数据
- zkClient.writeData("/dubbo", "dubbo");
- System.in.read();
- }
- }
注意以下几点:
1.不能删除已经存在子节点的节点
2.不能再临时节点上创建节点
四。zookeeper与eureka浅谈
一个分布式系统不可能同时满足C(一致性)、A(可用性)和P(分区容错性)
zookeeper优先保证CP,当服务发生故障会进行leader的选举,整个期间服务处在不可用状态,如果选举时间过长势必会大幅度降低性能,另外就用途来说zookeeper偏向于服务的协调,当然含有注册中心的作用
eureka优先保证AP, 即服务的节点各个都是平等的,没有leader不leader一说, 当服务发生故障时,其余的节点仍然可以提供服务,因此在出现故障时,性能表现优于zookeeper,但是可能会造成数据不一致的情况。
zookeeper快速入门的更多相关文章
- Zookeeper 快速入门(上)
来源:holynull, blog.leanote.com/post/holynull/Zookeeper 如有好文章投稿,请点击 → 这里了解详情 Zookeeper是Hadoop分布式调度服务,用 ...
- ZooKeeper学习总结 第一篇:ZooKeeper快速入门
1. 概述 Zookeeper是Hadoop的一个子项目,它是分布式系统中的协调系统,可提供的服务主要有:配置服务.名字服务.分布式同步.组服务等. 它有如下的一些特点: 简单 Zookeeper的核 ...
- zookeeper 快速入门
分布式系统简介 在分布式系统中另一个需要解决的重要问题就是数据的复制.我们日常开发中,很多人会碰到一个问题:客户端C1更新了一个值K1由V1更新到V2.但是客户端C2无法立即读取到K的最新值.上面的例 ...
- kafka快速入门(官方文档)
第1步:下载代码 下载 1.0.0版本并解压缩. > tar -xzf kafka_2.11-1.0.0.tgz > cd kafka_2.11-1.0.0 第2步:启动服务器 Kafka ...
- 中小型研发团队架构实践五:Redis快速入门及应用
Redis的使用难吗?不难,Redis用好容易吗?不容易.Redis的使用虽然不难,但与业务结合的应用场景特别多.特别紧,用好并不容易.我们希望通过一篇文章及Demo,即可轻松.快速入门并学会应用. ...
- Hadoop生态圈-Hive快速入门篇之HQL的基础语法
Hadoop生态圈-Hive快速入门篇之HQL的基础语法 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客的重点是介绍Hive中常见的数据类型,DDL数据定义,DML数据操作 ...
- Nutch 快速入门(Nutch 2.2.1+Hbase+Solr)
http://www.tuicool.com/articles/VfEFjm Nutch 2.x 与 Nutch 1.x 相比,剥离出了存储层,放到了gora中,可以使用多种数据库,例如HBase, ...
- 中小型研发团队架构实践:Redis快速入门及应用
Redis的使用难吗?不难,Redis用好容易吗?不容易.Redis的使用虽然不难,但与业务结合的应用场景特别多.特别紧,用好并不容易.我们希望通过一篇文章及Demo,即可轻松.快速入门并学会应用. ...
- Solr快速入门
1. 什么是Solr Solr是基于lucene的全文检索服务器.不同于lucene工具包,solr是一个web应用,运行在servlet容器,屏蔽了底层细节,并对外提供服务. 点我lucene快速入 ...
随机推荐
- 【iOS】swift 枚举
枚举语法 你可以用enum开始并且用大括号包含整个定义体来定义一个枚举: enum SomeEnumeration { // 在这里定义枚举 } 这里有一个例子,定义了一个包含四个方向的罗盘: enu ...
- 机器学习中的K-means算法的python实现
<机器学习实战>kMeans算法(K均值聚类算法) 机器学习中有两类的大问题,一个是分类,一个是聚类.分类是根据一些给定的已知类别标号的样本,训练某种学习机器,使它能够对未知类别的样本进行 ...
- 关于PHP7
目前一直使用php7也看了许多文档视频等,整理一下相关细节(仅为记录-),对于PHP7性能,如下图所示. * 在wordpress3.0.1中 php7比php5.6性能提升约3倍左右 新特性 一.变 ...
- python利用递归函数输出嵌套列表的每个元素
1.先用 for 循环取. for item in l: if isinstance(item ,list): for newitem in item: print(newitem) else: pr ...
- api-gateway实践(15)API网关的待改进点 20171207
一.API网关能力 API网关负责服务请求路由.组合及协议转换.客户端的所有请求都首先经过API网关,然后由它将请求路由到合适的微服务.API网关的客户端通过统一的网关接入微服务,在网关层处理所有的非 ...
- SpringBoot应用的属性管理
一.properties 配置文件 1.src/main/application.properties spring.profiles.active=dev spring.application.na ...
- win10下安装Ubuntu16.04双系统
其实我是不喜欢系统的,之前都是在win下面进行开发,现在来了个项目,经过各种环境的安装调研,最终选择在Ubuntu下面进行开发.之前想着为啥不在虚拟机里面安装Ubuntu进行操作呢,由于虚拟机的体验不 ...
- [转]python 模块 chardet下载及介绍
来源:http://blog.csdn.net/tianzhu123/article/details/8187470/ 在处理字符串时,常常会遇到不知道字符串是何种编码,如果不知道字符串的编码就不 ...
- 《Java面向对象设计》
<Java面向对象设计> 第一章 面向对象软件工程与UML p理解为什么需要软件工程 p掌握软件工程的基本概念 p掌握软件生命周期各个阶段的主要任务 p了解流行软件开发过程 p了解软件过程 ...
- JS面向对象使用面向对象进行开发
面向对象基础一之初体验使用面向对象进行开发 对 JS 中的面向对象的基础进行讲述, 初体验使用面向对象进行开发 主要内容是 面向对象的概念及特性 用面向对象的方式解决简单的标签创建实例 一些基础的 ...