SPFA 算法详解
适用范围:给定的图存在负权边,(快看小说网)这时类似Dijkstra等算法便没有了用武之地,而Bellman-Ford算法的复杂度又过高,SPFA算法便 派上用场了。 我们约定有向加权图G不存在负权回路,即最短路径一定存在。当然,我们可以在执行该算法前做一次拓扑排序,以判断是否存在负权回路,但这不是我们讨论的重 点。
算法思想:我们用数组d记录每个结点的最短路径估计值,用邻接表来存储图G。我们采取的方法是动态逼近法:设立一个先进先出的队列用来保存待优化的 结点,优化时每次取出队首结点u,并且用u点当前的最短路径估计值对离开u点所指向的结点v进行松弛操作,如果v点的最短路径估计值有所调整,且v点不在 当前的队列中,就将v点放入队尾。这样不断从队列中取出结点来进行松弛操作,直至队列空为止
期望的时间复杂度O(ke), 其中k为所有顶点进队的平均次数,可以证明k一般小于等于2。
实现方法:
建立一个队列,初始时队列里只有起始点,再建立一个表格记录起始点到所有点的最短路径(该表格的初始值要赋为极大值,该点到他本身的路径赋为 0)。然后执行松弛操作,用队列里有的点作为起始点去刷新到所有点的最短路,
男欢女爱如果刷新成功且被刷新点不在队列中则把该点加入到队列最后。重复执行直到队列 为空。
判断有无负环:
如果某个点进入队列的次数超过N次则存在负环(SPFA无法处理带负环的图)
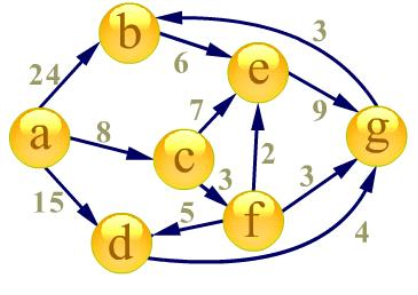
首先建立起始点a到其余各点的
最短路径表格
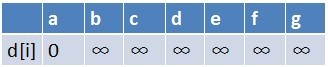
首先源点a入队,当队列非空时:
1、队首元素(a)出队,对以a为起始点的所有边的终点依次进行松弛操作(此处有b,c,d三个点),此时路径表格状态为:
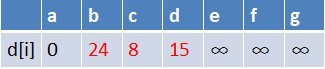
在松弛时三个点的最短路径估值变小了,而这些点队列中都没有出现,这些点
需要入队,此时,队列中新入队了三个结点b,c,d
队首元素b点出队,对以b为起始点的所有边的终点依次进行松弛操作(此处只有e点),此时路径表格状态为:
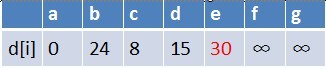
在最短路径表中,e的最短路径估值也变小了,e在队列中不存在,因此e也要
入队,此时队列中的元素为c,d,e
队首元素c点出队,对以c为起始点的所有边的终点依次进行松弛操作(此处有e,f两个点),此时路径表格状态为:
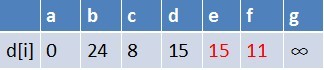
在最短路径表中,e,f的最短路径估值变小了,e在队列中存在,f不存在。因此
e不用入队了,f要入队,此时队列中的元素为d,e,f
队首元素d点出队,对以d为起始点的所有边的终点依次进行松弛操作(此处只有g这个点),此时路径表格状态为:
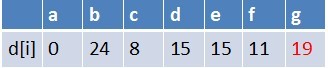
在最短路径表中,g的最短路径估值没有变小(松弛不成功),没有新结点入队,队列中元素为f,g
队首元素f点出队,对以f为起始点的所有边的终点依次进行松弛操作(此处有d,e,g三个点),此时路径表格状态为:

在最短路径表中,e,g的最短路径估值又变小,队列中无e点,e入队,队列中存在g这个点,g不用入队,此时队列中元素为g,e
队首元素g点出队,对以g为起始点的所有边的终点依次进行松弛操作(此处只有b点),此时路径表格状态为:
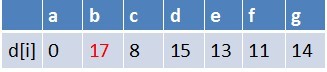
在最短路径表中,b的最短路径估值又变小,队列中无b点,b入队,此时队列中元素为e,b
队首元素e点出队,对以e为起始点的所有边的终点依次进行松弛操作黎南杨小丽(此处只有g这个点),此时路径表格状态为:
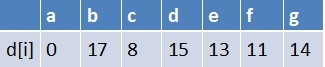
在最短路径表中,g的最短路径估值没变化(松弛不成功),此时队列中元素为b
队首元素b点出队,对以b为起始点的所有边的终点依次进行松弛操作(此处只有e这个点),此时路径表格状态为:
在最短路径表中,e的最短路径估值没变化(松弛不成功),此时队列为空了
最终a到g的最短路径为14
java代码
package spfa负权路径; import java.awt.List;
import java.util.ArrayList;
import java.util.Scanner;
public class SPFA {
/**
* @param args
*/
public long[] result; //用于得到第s个顶点到其它顶点之间的最短距离
//数组实现邻接表存储
class edge{
public int a;//边的起点
public int b;//边的终点
public int value;//边的值
public edge(int a,int b,int value){
this.a=a;
this.b=b;
this.value=value;
}
}
public static void main(String[] args) {
// TODO Auto-generated method stub
SPFA spafa=new SPFA();
Scanner scan=new Scanner(System.in);
int n=scan.nextInt();
int s=scan.nextInt();
int p=scan.nextInt();
edge[] A=new edge[p];
for(int i=0;i<p;i++){
int a=scan.nextInt();
int b=scan.nextInt();
int value=scan.nextInt();
A[i]=spafa.new edge(a,b,value);
}
if(spafa.getShortestPaths(n,s,A)){
for(int i=0;i<spafa.result.length;i++){
System.out.println(spafa.result[i]+" ");
}
}else{
System.out.println("存在负环");
}
}
/*
* 参数n:给定图的顶点个数
* 参数s:求取第s个顶点到其它所有顶点之间的最短距离
* 参数edge:给定图的具体边
* 函数功能:如果给定图不含负权回路,则可以得到最终结果,如果含有负权回路,则不能得到最终结果
*/
private boolean getShortestPaths(int n, int s, edge[] A) {
// TODO Auto-generated method stub
ArrayList<Integer> list = new ArrayList<Integer>();
result=new long[n];
boolean used[]=new boolean[n];
int num[]=new int[n];
for(int i=0;i<n;i++){
result[i]=Integer.MAX_VALUE;
used[i]=false;
}
result[s]=0;//第s个顶点到自身距离为0
used[s]=true;//表示第s个顶点进入数组队
num[s]=1;//表示第s个顶点已被遍历一次
list.add(s); //第s个顶点入队
while(list.size()!=0){
int a=list.get(0);//获取数组队中第一个元素
list.remove(0);//删除数组队中第一个元素
for(int i=0;i<A.length;i++){
//当list数组队的第一个元素等于边A[i]的起点时
if(a==A[i].a&&result[A[i].b]>(result[A[i].a]+A[i].value)){
result[A[i].b]=result[A[i].a]+A[i].value;
if(!used[A[i].b]){
list.add(A[i].b);
num[A[i].b]++;
if(num[A[i].b]>n){
return false;
}
used[A[i].b]=true;//表示边A[i]的终点b已进入数组队
}
}
}
used[a]=false; //顶点a出数组对
}
return true;
}
}
SPFA 算法详解的更多相关文章
- 图的最短路径-----------SPFA算法详解(TjuOj2831_Wormholes)
这次整理了一下SPFA算法,首先相比Dijkstra算法,SPFA可以处理带有负权变的图.(个人认为原因是SPFA在进行松弛操作时可以对某一条边重复进行松弛,如果存在负权边,在多次松弛某边时可以更新该 ...
- SPFA 算法详解( 强大图解,不会都难!) (转)
适用范围:给定的图存在负权边,这时类似Dijkstra等算法便没有了用武之地,而Bellman-Ford算法的复杂度又过高,SPFA算法便 派上用场了. 我们约定有向加权图G不存在负权回路,即最短路径 ...
- SPFA算法详解
前置知识:Bellman-Ford算法 前排提示:SPFA算法非常容易被卡出翔.所以如果不是图中有负权边,尽量使用Dijkstra!(Dijkstra算法不能能处理负权边,但SPFA能) 前排提示*2 ...
- Bellman-Ford算法与SPFA算法详解
PS:如果您只需要Bellman-Ford/SPFA/判负环模板,请到相应的模板部分 上一篇中简单讲解了用于多源最短路的Floyd算法.本篇要介绍的则是用与单源最短路的Bellman-Ford算法和它 ...
- Bellman-Ford&&SPFA算法详解
Dijkstra在正权图上运行速度很快,但是它不能解决有负权的最短路,如下图: Dijkstra运行的结果是(以1为原点):0 2 12 6 14: 但手算的结果,dist[4]的结果显然是5,为什么 ...
- 【最短路径Floyd算法详解推导过程】看完这篇,你还能不懂Floyd算法?还不会?
简介 Floyd-Warshall算法(Floyd-Warshall algorithm),是一种利用动态规划的思想寻找给定的加权图中多源点之间最短路径的算法,与Dijkstra算法类似.该算法名称以 ...
- BM算法 Boyer-Moore高质量实现代码详解与算法详解
Boyer-Moore高质量实现代码详解与算法详解 鉴于我见到对算法本身分析非常透彻的文章以及实现的非常精巧的文章,所以就转载了,本文的贡献在于将两者结合起来,方便大家了解代码实现! 算法详解转自:h ...
- kmp算法详解
转自:http://blog.csdn.net/ddupd/article/details/19899263 KMP算法详解 KMP算法简介: KMP算法是一种高效的字符串匹配算法,关于字符串匹配最简 ...
- 机器学习经典算法详解及Python实现--基于SMO的SVM分类器
原文:http://blog.csdn.net/suipingsp/article/details/41645779 支持向量机基本上是最好的有监督学习算法,因其英文名为support vector ...
随机推荐
- Graphical Analysis of German Parliament Voting Pattern
We use network visualizations to look into the voting patterns in the current German parliament. I d ...
- C. Friends
C. Friends 题意 对于任一点,求到此点距离不超过6的节点数. 分析 第一次dfs,形成一个以 1 为根的有向树,设 down[i][j] 为以i为根节点,距离 i 点距离不超过 j 的节点数 ...
- Eclipse之文件【默认编码格式设置】,防止乱码等问题
文件默认编码格式设置步骤如下: 这里显示的是workspace的视图 其他格式文件的视图如下:
- 天气正好,hello world!
两个多月,稀里糊涂的回来了,内心很迷茫,回来一周了,明知道还需要有一大堆东西需要去学,但是却找不到之前学习的状态,在寝室,在实验室,看着自己一向不喜欢的电视剧,无目的的逛着淘宝,刷着头条和知乎,就这么 ...
- dedecms后台添加新变量和删除变量的方法
下面由做网站为大家来介绍dedecms后台添加新变量和删除变量的方法 添加新变量是做什么用的?答:可以在模板内调用的东东. 一.进入网站织梦(Dedecms)后台(以dede5.5为例),依次打开系统 ...
- kali&BT安装好之后无法上网或者无法获得内网IP
大家都知道,要想进行内网渗透攻击,你必须要在那个内网里. 但是大家在Vmware里安装kali的时候,大多数用户为了方便,未选择桥接模式,而是选择了使用与本机共享的IP网络当然,这样能上网,但是你的虚 ...
- CSS3学习系列之选择器(三)
E:enabled伪类选择器和E:disabled伪类选择器 E:enabled伪类选择器用来指定元素处于可用状态的样式. E:disabled伪类选择器用来指定当元素处于不可用状态时的样式. 当一个 ...
- javascript中event.clientX和event.clientY用法的注意事项
今天做项目用到了event.clientX和event.clientY,给元素定位,用定位的时候,让top和left等于事件元素的的坐标 <!DOCTYPE html> <html& ...
- flask 扩展之 -- flask-sqlalchemy
flask-sqlalchemy.md 一. 安装 $ pip install flask-sqlalchemy 二. 配置 配置选项列表 : 选项 说明 SQLALCHEMY_DATABASE_UR ...
- 【CC2530入门教程-01】IAR集成开发环境的建立与项目开发流程
[引言] 本系列教程就有关CC2530单片机应用入门基础的实训案例进行分析,主要包括以下6部分的内容:1.CC2530单片机开发入门.2.通用I/O端口的输入和输出.3.外部中断初步应用.4.定时/计 ...