Python爬虫01——第一个小爬虫
Python小爬虫——贴吧图片的爬取
在对Python有了一定的基础学习后,进行贴吧图片抓取小程序的编写。
目标:
- 首先肯定要实现图片抓取这个基本功能
- 然后实现对用户所给的链接进行抓取
- 最后要有一定的交互,程序不能太傻吧
一、页面获取
要让python可以进行对网页的访问,那肯定要用到urllib之类的包。So先来个 import urllib
urllib中有 urllib.urlopen(str) 方法用于打开网页并返回一个对象,调用这个对象的read()方法后能直接获得网页的源代码,内容与浏览器右键查看源码的内容一样。
#coding:utf-8
import urllib page = urllib.urlopen('http://tieba.baidu.com/p/1753935195')#打开网页
htmlcode = page.read()#读取页面源码
print htmlcode#在控制台输出
运行结果与查看源码其实差不多
运行结果就不放上来了
也可以写到文本文档中:
#coding:utf-8
import urllib page = urllib.urlopen('http://tieba.baidu.com/p/1753935195')
htmlcode = page.read()
#print htmlcode pageFile = open('pageCode.txt','w')#以写的方式打开pageCode.txt
pageFile.write(htmlcode)#写入
pageFile.close()#开了记得关
运行一遍,txt就出现在了getJpg.py 的目录下
的目录下
好了别闹,我们把它封装成方法:
def get_html(url):
page = urllib.urlopen(url)
html = page.read()
return html
然后我们的页面获取代码就K.O.了
二、图片(目标)的提取
做完上面步骤,你打开txt一看,我去!这都是什么跟什么啊,根本找不到图片在哪好伐?
客官别急啊,我这就去给你叫我们的小。。。图片!图片!
首先我们要一个正则表达式 (什么你不会?请看菜鸟入门教程-->Go)
然后我们看源代码,Yeah 我们找到了其中一张图片是这样的
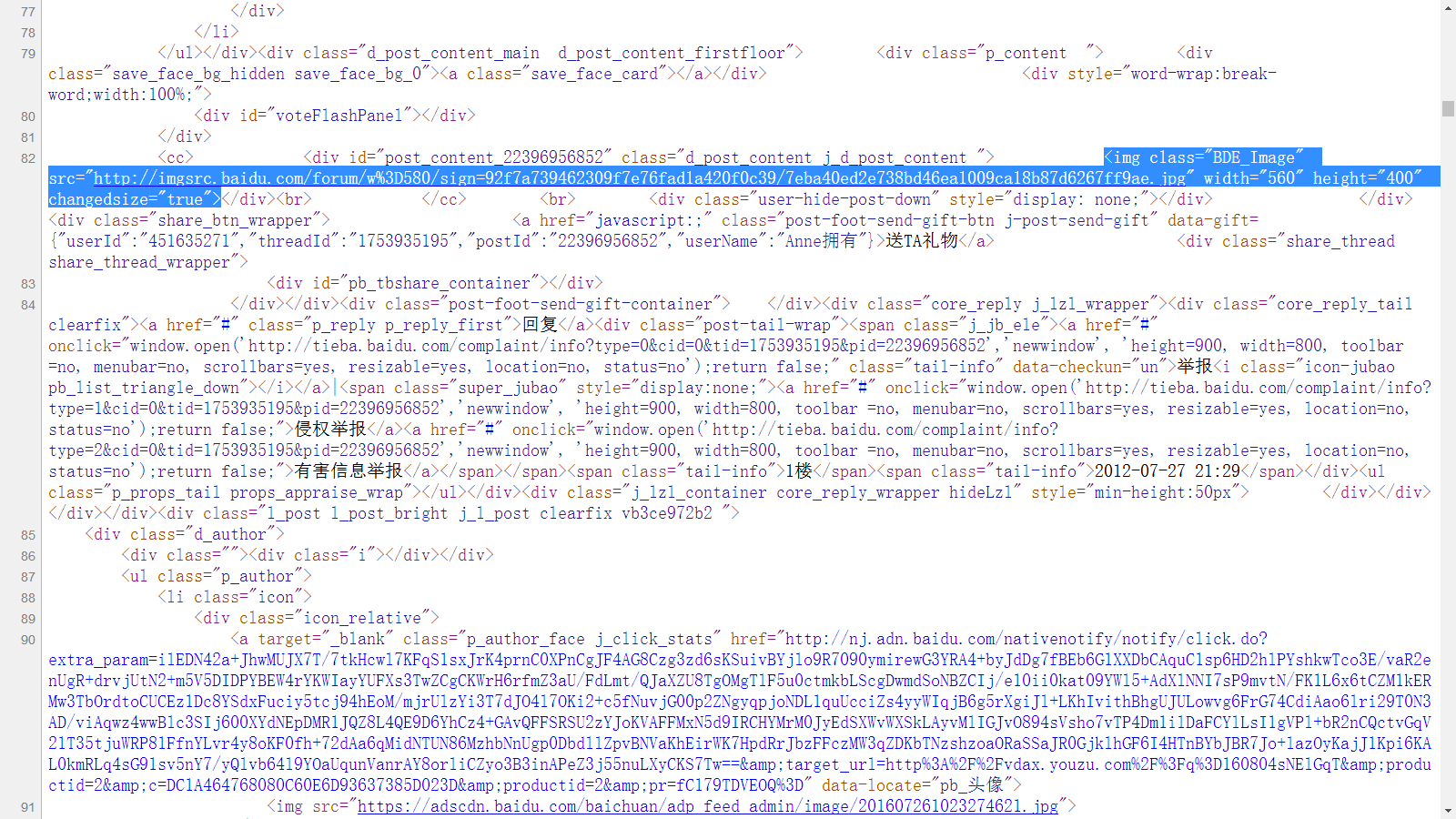
写出图片的正则表达式: reg = r'src="(.+?\.jpg)" width'
解释下吧——匹配以src="开头然后接一个或多个任意字符(非贪婪),以.jpg" width结尾的字符串。比如图中红框内src后 双引号里的链接就是一个匹配的字符串。
接着我们要做的就是从get_html方法返回的辣么长一串字符串中 拿到 满足正则表达式的 字符串。
用到python中的re库中的 re.findall(str) 它返回一个满足匹配的字符串组成的列表
# coding:utf-8
import urllib
import re def get_html(url):
page = urllib.urlopen(url)
html = page.read()
return html reg = r'src="(.+?\.jpg)" width'#正则表达式
reg_img = re.compile(reg)#编译一下,运行更快
imglist = reg_img.findall(get_html('http://tieba.baidu.com/p/1753935195'))#进行匹配
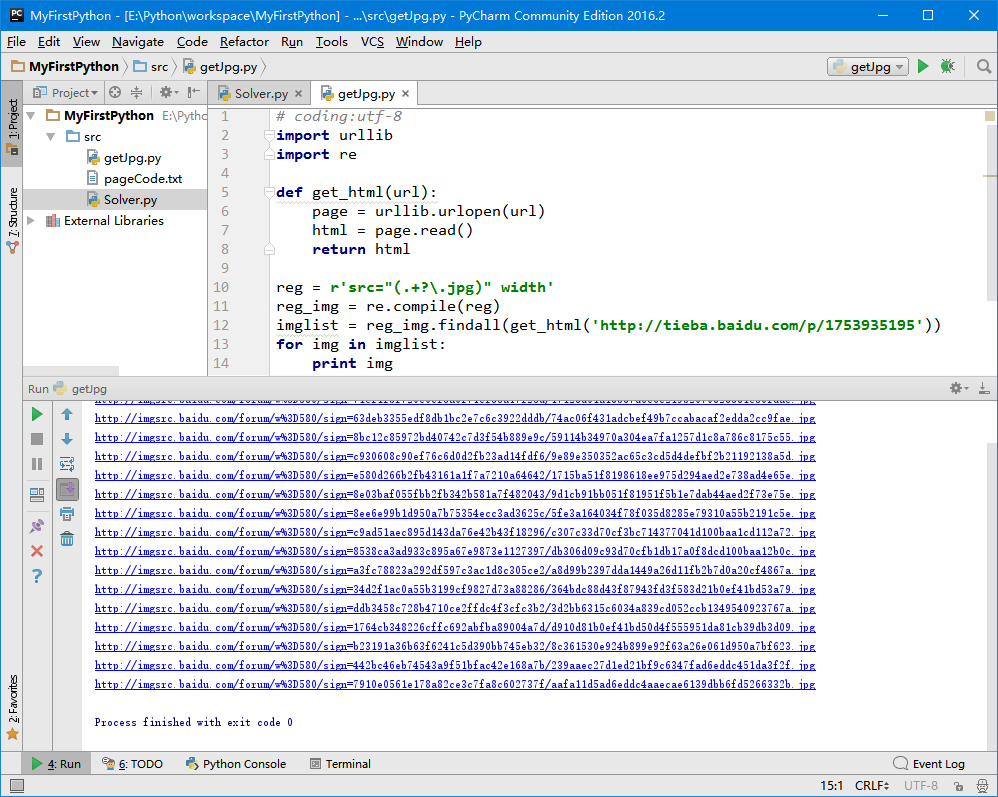
for img in imglist:
print img
打印出这么多图片链接
光把链接拿出来没用啊,我们的目标是下载下来~
urllib库中有一个 urllib.urlretrieve(链接,名字) 方法,它的作用是以第二个参数为名字下载链接中的内容,我们来试用一下
在上面代码循环中加上 urllib.urlretrieve(img, 'tieba.jpg')
卧槽!!!怎么只下了一张
至少它下载了不是?啪啪啪啪啪(掌声)
检查下问题出在哪。。。。
没错我们只给了一个tieba.jpg的名字,后来的把前面的覆盖了。
调整下代码:
# coding:utf-8
import urllib
import re def get_html(url):
page = urllib.urlopen(url)
html = page.read()
return html reg = r'src="(.+?\.jpg)" width'
reg_img = re.compile(reg)
imglist = reg_img.findall(get_html('http://tieba.baidu.com/p/1753935195'))
x = 0
for img in imglist:
urllib.urlretrieve(img, '%s.jpg' %x)
x += 1
啪啪啪啪啪

第一步完成~
三、指定链接抓取
我想要抓另一个帖子,总不能打开源代码,然后把那段地址改了在运行吧。
只是一个小程序,那也不行欸,加一个让用户指定地址的交互。
先把提取图片的那段代码打包下:
def get_image(html_code):
reg = r'src="(.+?\.jpg)" width'
reg_img = re.compile(reg)
img_list = reg_img.findall(html_code)
x = 0
for img in img_list:
urllib.urlretrieve(img, '%s.jpg' % x)
x += 1
最后来个请输入:
print u'请输入url:',
url = raw_input()
if url:
pass
else:
url = 'http://tieba.baidu.com/p/1753935195'
html_code = get_html(url)
get_image(html_code)
运行一下,试试另一个帖子:
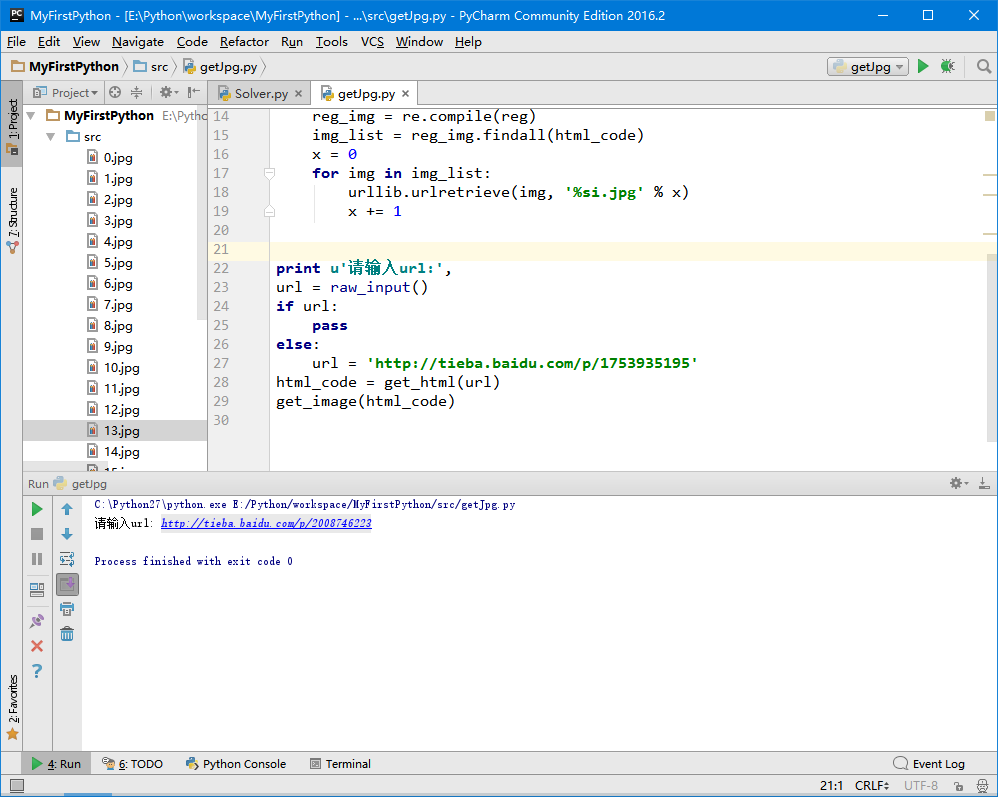
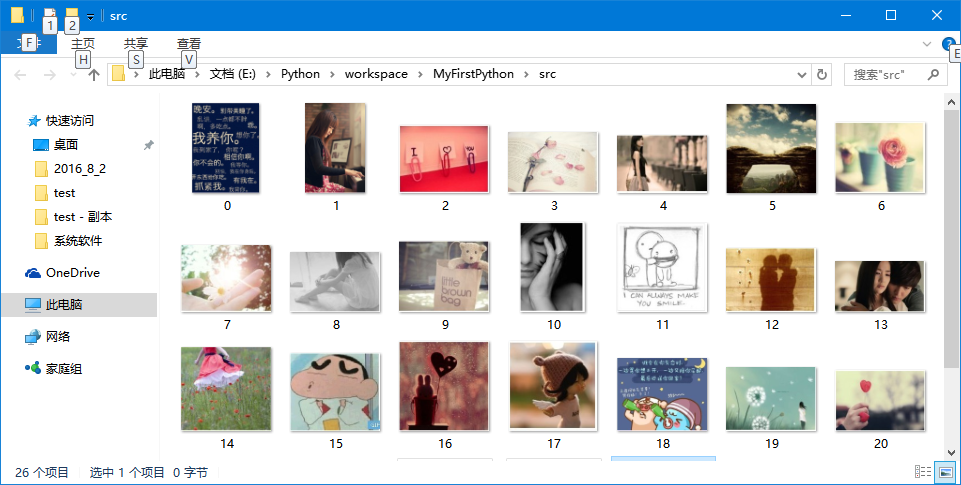
完美~~
四、交互的添加
虽然写的是一个简单的小程序,但有强迫症的我还是给他加上了交互(不然多难受啊:双击,屏幕一闪,下载完了。。。)
最后的代码
# coding:utf-8
import urllib
import re def get_html(url):
page = urllib.urlopen(url)
html_code = page.read()
return html_code def get_image(html_code):
reg = r'src="(.+?\.jpg)" width'
reg_img = re.compile(reg)
img_list = reg_img.findall(html_code)
x = 0
for img in img_list:
urllib.urlretrieve(img, '%s.jpg' % x)
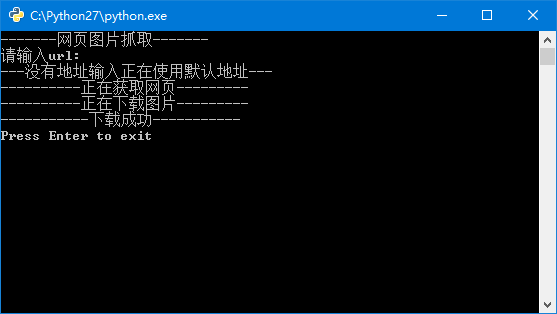
x += 1 print u'-------网页图片抓取-------'
print u'请输入url:',
url = raw_input()
if url:
pass
else:
print u'---没有地址输入正在使用默认地址---'
url = 'http://tieba.baidu.com/p/1753935195'
print u'----------正在获取网页---------'
html_code = get_html(url)
print u'----------正在下载图片---------'
get_image(html_code)
print u'-----------下载成功-----------'
raw_input('Press Enter to exit')
相对来说比较舒服的交互体验,大功告成~
Python爬虫01——第一个小爬虫的更多相关文章
- Python 学习(1) 简单的小爬虫
最近抽空学了两天的Python,基础知识都看完了,正好想申请个联通日租卡,就花了2小时写了个小爬虫,爬一下联通日租卡的申请页面,看有没有好记一点的手机号~ 人工挑眼都挑花了. 用的IDE是PyCh ...
- 使用Python写的第一个网络爬虫程序
今天尝试使用python写一个网络爬虫代码,主要是想訪问某个站点,从中选取感兴趣的信息,并将信息依照一定的格式保存早Excel中. 此代码中主要使用到了python的以下几个功能,因为对python不 ...
- 利用python写一个简单的小爬虫 爬虫日记(1)(好好学习)
打开py的IDLE >>>import urllib.request >>>a=urllib.request.urlopen("http://www.ba ...
- 从Python小白到第一个小游戏发布
1.安装必要的环境(附图两张) 直接下载安装程序,本人win10系统,根据电脑系统下载并安装对应的python.exe,安装路径可以选择D盘的,具体安装细节这里就不说了,不知道的可以留言或者找度娘 2 ...
- python3速查参考- python基础 1 -> python版本选择+第一个小程序
题外话: Python版本:最新的3.6 安装注意点:勾选添加路径后自定义安装到硬盘的一级目录,例如本人的安装路径: F:\Python 原因:可以自动添加python环境变量,自动关联.py文件,其 ...
- Python做的第一个小项目-模拟登陆
1. 用户输入帐号密码进行登陆 2. 用户信息保存在文件内 3. 用户密码输入错误三次后锁定用户 主要采用循环语句和条件语句进行程序流程的控制,加入文件的读写操作 while True: choice ...
- 用Python 3写的一个Spider小爬虫(使用内置urllib模块and正则表达式)
用Python写了一个Spider小爬虫,爬一爬斗鱼“王者荣耀”在线直播的主播及人气
- Python爬虫02——贴吧图片爬虫V2.0
Python小爬虫——贴吧图片爬虫V2.0 贴吧图片爬虫进阶:在上次的第一个小爬虫过后,用了几次发现每爬一个帖子,都要自己手动输入帖子链接,WTF这程序简直反人类!不行了不行了得改进改进. 思路: 贴 ...
- python 10 min系列三之小爬虫(一)
python10min系列之小爬虫 前一篇可视化大家表示有点难,写点简单的把,比如命令行里看论坛的十大,大家也可以扩展为抓博客园的首页文章 本文原创,同步发布在我的github上 据说去github右 ...
随机推荐
- WPF中的RichTextBox
原文链接:http://blog.csdn.net/wuzhengqing1/article/details/7010902 取出richTextBox里面的内容 第一种方法:将richTextBox ...
- 【WCF】错误处理(四):一刀切——IErrorHandler
前面几篇烂文中所介绍到的错误方式,都是在操作协定的实现代码中抛出 FaultException 或者带泛型参数的detail方案,有些时候,错误的处理方法比较相似,可是要每个操作协定去处理,似乎也太麻 ...
- nginx反向代理的nginx.conf配置
下面的配置是nginx.conf的示例 nginx反向代理 就是说把跨域的url通过本地代理的方式,变成同域的请求,如此来解决跨域问题 该配置下 通过http://localhost/html5/路径 ...
- ios sqlite3的简单使用
第一:创建表格 //创建表格 -(void)creatTab{ NSString*creatSQL=@"CREATE TABLE IF NOT EXISTS PERSIONFO(ID INT ...
- Spring+SpringMVC+MyBatis+easyUI整合优化篇(十一)数据层优化-druid监控及慢sql记录
本文提要 前文也提到过druid不仅仅是一个连接池技术,因此在将整合druid到项目中后,这一篇文章将去介绍druid的其他特性和功能,作为一个辅助工具帮助提升项目的性能,本文的重点就是两个字:监控. ...
- Unity 检测物体是否在相机视野范围内
需求: 类似NPC血条,当NPC处于摄像机视野内,血条绘制,且一直保持在NPC头顶. 开始: 网上查找资料,然后编写代码: public RectTransform rectBloodPos; voi ...
- Java设计模式:桥接模式
问题提出 生活中有很多事物集合,设为A1,A2......Am ,而每个事物都有功能F1,F2....Fn. 例如邮局的发送业务.简单模拟有两类事物:信件和包裹,均有平邮和挂号邮寄功能.程序设计中如何 ...
- cocos2d-x - C++/Lua交互
使用tolua++将自定义的C++类嵌入,让lua脚本使用 一般过程: 自定义类 -> 使用tolua++工具编译到LuaCoco2d.cpp中 -> lua调用 步骤一:自定义一个C++ ...
- 如何有效快速提高Java服务端开发人员的技术水平?
我相信很多工作了3-5年的开发人员都会经常问自己几个问题: 1.为什么总是感觉技术没有质的提高? 2.如何能够有效和快速的提高自身的技术水平? 3.如何进入到一个牛逼的大公司,认识牛逼的人? 这篇文章 ...
- uiautomator+cucumber实现自动化测试
前提 由于公司业务要求,所以自动化测试要达到以下几点: 跨应用的测试 测试用例可读性强 测试报告可读性强 对失败的用例有截图保存并在报告中体现 基于以上几点,在对自动化测试框架选型的时候就选择了uia ...