使用fabric解决百度BMR的spark集群各节点的部署问题
前言
和小伙伴的一起参加的人工智能比赛进入了决赛之后的一段时间里面,一直在构思将数据预处理过程和深度学习这个阶段合并起来。然而在合并这两部分代码的时候,遇到了一些问题,为此还特意写了脚本文件进行处理。现在比赛过去,我觉得应该把这部分的东西写出来,看看是否有其他朋友会遇到这方面问题,希望对他们有帮助。如有不对之处,请大家指正,谢谢!
比赛遇到的集群各节点的部署痛点
一个前提
在初赛的时候,为了快捷提供数据接口给后面的深度学习模型建立使用,我们将数据预处理独立出来,使用了最为简单的Python操作。在此,考虑到的是,我们的代码需要移植到评委所用的电脑当中进行验证,可能存在没有import某些库的情况,最后导致程序运行失败。
麻烦之处
在进入到决赛后,由于这两块的结合在一起的迫切需求,我们不得不又重新import我们库。然而在这块当中,如果我们只在Master节点,问题很简单,直接将库打包好,写个脚本就完事了。而在百度的BMR的spark集群里面,因为Slaves节点不能访问网络(如下图),因而我们要登录了Master节点之后,然后通过Master内网ssh到Slaves上,进而才能打开我们的脚本部署好我们的程序运行环境。

提出
这样子来说,我们有没有一个很好的办法,能通过Master上运行一个脚本,达到了整个集群的所有节点都自动部署我们的程序运行环境呢?经过阅读书籍《spark最佳实践》,了解到了Python的第三方库fabric。
fabric
首先请允许介绍一下fabric,具体使用方法可以查阅官方API Doc,在此我介绍一下我将使用到某一小部分。
执行本地任务
fabric提供了一个local("shell")的接口,shell就是Linux上的shell命令。例如
from fabric.api import local
local('ls /root/') #ls root文件夹下的文件列表
执行远程任务
fabric的强大之处,不是它在本地做到执行命令,本地执行的事儿可以用原生shell来解决,而是能在远程的服务器上执行命令,哪怕远程的服务器上没有安装fabric。它是通过ssh方式实现的,因而我们需要定义一下三个参数:
env.hosts = ['ipaddress1', 'ipaddress2']
env.user = 'root'
env.password = 'fuckyou.'
通过设置ip,用户名以及用户名密码,我们可以使用run("shell"),达到在远程服务器上执行我们所需要执行的任务。例如
from fabric.api import run, env
env.hosts = ['ipaddress1', 'ipaddress2']
env.user = 'root'
env.password = 'fuckyou.'
run('ls /root/') #ls root文件夹下的文件列表
打开某一个文件夹
有时候我们需要精准地打开某一个文件夹,之后执行该文件下的某一个脚本或者文件。这是,我们得使用以下两个接口:
本地
with lcd('/root/local/'):
local('cat local.txt') # cat 本地'/root/local/'下的local.txt文件
远程
with cd('/root/distance/'):
run('cat distance.txt') # cat 远程'/root/distance/'下的distance.txt文件
执行fabric任务
我们可以通过命令行
fab --fabfile=filename.py job_func
# filename.py为使用fabric写的Python文件
# job_func 为带有fabric的函数,即主要执行的函数
# 以上两个名称都是可以自取,下面的介绍当中,我的为job.py 与 job
socket
为什么会用到socket呢?在上一篇文章当中,我提及到在百度BMR的集群中,他们设置集群Slaves都是通过slaves的hostname的,而不是通过ip。而因为在使用fabric设置环境中的hosts的时候需要用到ip,那我们得通过hostname,进而找到ip。
你或许有疑问,为什么不直接设定Slaves的IP呢?但是百度BMR每次创建spark集群,它提供的内网IP都是不断在变动的,呈现出IP末端递增。
综上,还是使用hostname获取IP
gethostbyname接口
我们可以用过gethostbyname('hostname')接口,传入hostname,然后得到一个IPV4的ip地址。
使用fabric编写各节点自动部署脚本
获取Slaves的hostname
和上一篇文章说道的一样,我们Slaves的hostname是藏在了百度BMR的这里:
'/opt/bmr/hadoop/etc/hadoop/slaves'
将hostname转化为ip,设置fabric的env参数
host_list = []
f = open(path, 'r')
slaves_name = f.read().split('\n')
for i in range(1, slaves_name.__len__()-1):
temp_name = slaves_name[i]
temp_ip = socket.gethostbyname(temp_name)
ip_port = temp_ip + ":22"
host_list.append(ip_port)
del temp_name
del temp_ip
del ip_port
env.user = 'root'
env.password = '*gdut728'
env.hosts = host_list
编写需要自动部署的job
在这里,我要自动部署的是:
1 下载Python第三方库jieba
2 在本地解压下载好的jieba压缩包
3 在本地,进入到解压好的文件夹中,安装jieba
4 将下载好的压缩包传送到Slaves节点上
5 在远程端,解压下载好的jieba压缩包
6 在远程端,进入到解压好的文件夹中,安装jieba
将上面步骤转化为代码,即
def job():
local_command = "wget https://pypi.python.org/packages/71/46/c6f9179f73b818d5827202ad1c4a94e371a29473b7f043b736b4dab6b8cd/jieba-0.39.zip#md5=ca00c0c82bf5b8935e9c4dd52671a5a9"
local(local_command)
jieba_unzip = "unzip jieba-0.39.zip"
jieba_path = "/root/jieba-0.39/"
jieba_install = "python setup.py install"
local(jieba_unzip)
with lcd(jieba_path):
local("ls")
local(jieba_install)
with lcd('/root/'):
put("jieba-0.39.zip", '/root')
run(jieba_unzip)
with cd(jieba_path):
run("ls")
run(jieba_install)
结言
最后,在我上篇文章提到的shell脚本中,最前面加上
yum -y install fabric && fab --fabfile=job.py job
输入./start-hadoop-spark.sh,即可无忧无虑地部署好我要使用的程序运行环境。因为懒,因为麻烦,于是用Python外加shell写了自动部署的脚本。在这个过程中,学习到不少知识,也遇到不少麻烦,写下文章,希望可以减轻大家配置的烦恼~
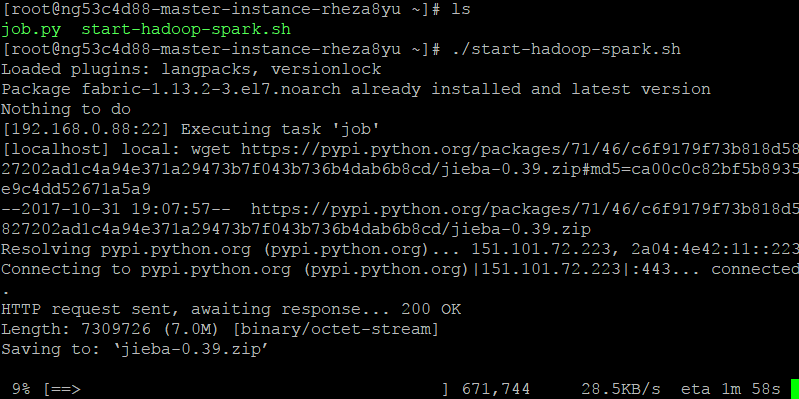
结果如下:
Master:

Slaves1:

Slaves2:

参照
Fabric 中文文档 http://fabric-chs.readthedocs.io/zh_CN/chs/
Python远程部署利器Fabric详解 http://python.jobbole.com/87241/
socket.gethostbyname() https://docs.python.org/2/library/socket.html#socket.gethostbyname
文章出自kwongtai'blog[http://www.cnblogs.com/kwongtai],转载请标明出处!
使用fabric解决百度BMR的spark集群各节点的部署问题的更多相关文章
- 解决百度BMR的spark集群开启slaves结点的问题
前言 最近一直忙于和小伙伴倒腾着关于人工智能的比赛,一直都没有时间停下来更新更新我的博客.不过在这一个过程中,遇到了一些问题,我还是记录了下来,等到现在比较空闲了,于是一一整理出来写成博客.希望对于大 ...
- Spark集群新增节点方法
Spark集群处理能力不足需要扩容,如何在现有spark集群中新增新节点?本文以一个实例介绍如何给Spark集群新增一个节点. 1. 集群环境 现有Spark集群包括3台机器,用户名都是cdahdp, ...
- Eclipse提交代码到Spark集群上运行
Spark集群master节点: 192.168.168.200 Eclipse运行windows主机: 192.168.168.100 场景: 为了测试在Eclipse上开发的代码在Spa ...
- Spark集群数据处理速度慢(数据本地化问题)
SparkStreaming拉取Kafka中数据,处理后入库.整个流程速度很慢,除去代码中可优化的部分,也在spark集群中找原因. 发现: 集群在处理数据时存在移动数据与移动计算的区别,也有些其他叫 ...
- docker 快速部署ES集群 spark集群
1) 拉下来 ES集群 spark集群 两套快速部署环境, 并只用docker跑起来,并保存到私库. 2)弄清楚怎么样打包 linux镜像(或者说制作). 3)试着改一下,让它们跑在集群里面. 4) ...
- Spark集群基础概念 与 spark架构原理
一.Spark集群基础概念 将DAG划分为多个stage阶段,遵循以下原则: 1.将尽可能多的窄依赖关系的RDD划为同一个stage阶段. 2.当遇到shuffle操作,就意味着上一个stage阶段结 ...
- 十、scala、spark集群搭建
spark集群搭建: 1.上传scala-2.10.6.tgz到master 2.解压scala-2.10.6.tgz 3.配置环境变量 export SCALA_HOME=/mnt/scala-2. ...
- Spark集群环境搭建——服务器环境初始化
Spark也是属于Hadoop生态圈的一部分,需要用到Hadoop框架里的HDFS存储和YARN调度,可以用Spark来替换MR做分布式计算引擎. 接下来,讲解一下spark集群环境的搭建部署. 一. ...
- spark集群搭建整理之解决亿级人群标签问题
最近在做一个人群标签的项目,也就是根据客户的一些交易行为自动给客户打标签,而这些标签更有利于我们做商品推荐,目前打上标签的数据已达5亿+, 用户量大概1亿+,项目需求就是根据各种组合条件寻找标签和人群 ...
随机推荐
- Struts2第七篇【介绍拦截器、自定义拦截器、执行流程、应用】
什么是拦截器 拦截器Interceptor-..拦截器是Struts的概念,它与过滤器是类似的-可以近似于看作是过滤器 为什么我们要使用拦截器 前面在介绍Struts的时候已经讲解过了,Struts为 ...
- 02函数-04-箭头函数(ES6)
ES6新增的函数:Arrow Function,定义方式就是一个箭头 箭头函数相当于匿名函数,并且简化了函数定义,和匿名函数最大的区别在于其内部的this不再"乱跑",而是由上下文 ...
- Lucene 搜索的初步探究
搜索应用程序和 Lucene 之间的关系 一般的搜索引擎都会采用这样的 Lucene 采用的是一种称为反向索引(inverted index)的机制.反向索引就是说我们维护了一个词 / 短语表,对于这 ...
- 常见注入手法第一讲EIP寄存器注入
常见注入手法第一讲EIP寄存器注入 博客园IBinary原创 博客连接:http://www.cnblogs.com/iBinary/ 转载请注明出处,谢谢 鉴于注入手法太多,所以这里自己整理一下, ...
- Hello PyQt5
在 ubuntu 系统上 GUI 编程,PyQt5 是个不错的选择.首先,当然是安装 PyQt5 了.终端输入命令: pip3 install PyQt5 即可. 1. 建立一目录 x01.PyQtH ...
- ubuntu下pip的安装和使用
对于python包的安装而言,需要pip包,对python包资源管理.pip包的安装.对于python2.x和python 3.x 方法不同 : Python 2: sudo dnf upgrade ...
- 深入理解String的关键点和方法
String是Java开发中最最常见的,本篇博客针对String的原理和常用的方法,以及String的在开发中常见问题做一个整体性的概括整理.因为之前对String的特性做过一些分析,所以不在详细描述 ...
- jenkins~集群分发功能的具体实现
前一讲主要说了jenkins分发的好处<jenkins~集群分发功能和职责处理>,它可以让具体的节点干自己具体的事,比如windows环境下的节点,它只负责编译,发布windows的生态环 ...
- 机器学习之numpy库中常用的函数介绍(一)
1. mat() mat()与array的区别: mat是矩阵,数据必须是2维的,是array的子集,包含array的所有特性,所做的运算都是针对矩阵来进行的. array是数组,数据可以是多维的,所 ...
- Response.Write输出导致页面变形和页面白屏解决办法
方法一:此方法应该是微软官方推荐的方法,但弹出时会造成页面白屏.Page.RegisterStartupScript("TestEvent", "<script&g ...