广州图书馆借阅抓取——httpClient的使用
欢迎访问我的个人网站,要是能在GitHub上对网站源码给个star就更好了。
搭建自己的网站的时候,想把自己读过借过的书都想记录一下,大学也做过自己学校的借书记录的爬取,但是数据库删掉了==,只保留一张截图。所以还是要好好珍惜自己阅读的日子吧,记录自己的借书记录——广州图书馆,现在代码已经放在服务器上定时运行,结果查看我的网站(关于我)页面。整个代码采用HttpClient,存储放在MySql,定时使用Spring自带的Schedule,下面是抓取的过程。
1.页面跳转过程
一般都是进入首页http://www.gzlib.gov.cn/,点击进登陆页面,然后输入账号密码。表面上看起来没什么特别之处,实际上模拟登陆的时候不仅仅是向链接post一个请求那么简单,得到的response要么跳回登陆页面,要么无限制重定向。

事实上,它做了单点登录,如下图,广州图书馆的网址为:www.gzlib.gov.cn,而登陆的网址为:login.gzlib.gov.cn。原理网上很多人都讲的很好了,可以看看这篇文章SSO单点登录。

2.处理方法
解决办法不难,只要先模拟访问一下首页即可获取图书馆的session,python的获取代码如:session.get("http://www.gzlib.gov.cn/"),打印cookie之后如下:
[<Cookie JSESSIONID=19E2DDED4FE7756AA9161A52737D6B8E for .gzlib.gov.cn/>, <Cookie JSESSIONID=19E2DDED4FE7756AA9161A52737D6B8E for www.gzlib.gov.cn/>, <Cookie clientlanguage=zh_CN for www.gzlib.gov.cn/>]
整个登陆抓取的流程如下:
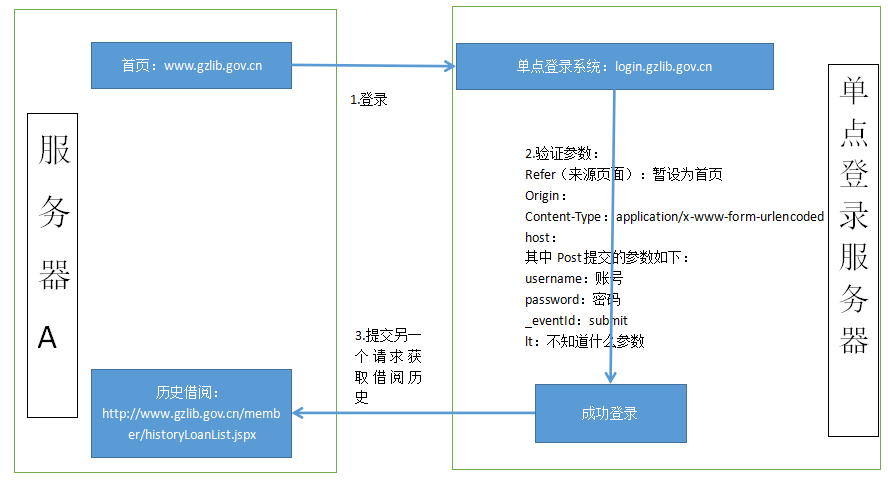
即:
(1)用户先点击广州图书馆的首页,以获取改网址的session,然后点击登录界面,解析html,获取lt(自定义的参数,类似于验证码),以及单点登录服务器的session。
(2)向目标服务器(单点登录服务器)提交post请求,请求参数中包含username(用户名),password(密码),event(时间,默认为submit),lt(自定义请求参数),同时服务端还要验证的参数:refer(来源页面),host(主机信息),Content-Type(类型)。
(3)打印response,搜索你自己的名字,如果有则表示成功了,否则会跳转回登陆页面。
(4)利用cookie去访问其他页面,此处实现的是对借阅历史的抓取,所以访问的页面是:http://www.gzlib.gov.cn/member/historyLoanList.jspx。
基本的模拟登陆和获取就是这些,之后还有对面html的解析,获取书名、书的索引等,然后封装成JavaBean,再之后便是保存入数据库。(去重没有做,不知道用什么方式比较好)
3.代码
3.1 Java中,一般用来提交http请求的大部分用的都是httpclient,首先,需要导入的httpclient相关的包:
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.3</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpcore</artifactId>
<version>4.4.7</version>
</dependency>
3.2 构建声明全局变量——上下文管理器,其中context为上下文管理器
public class LibraryUtil {
private static CloseableHttpClient httpClient = null;
private static HttpClientContext context = null;
private static CookieStore cookieStore = null;
static {
init();
}
private static void init() {
context = HttpClientContext.create();
cookieStore = new BasicCookieStore();
// 配置超时时间
RequestConfig requestConfig = RequestConfig.custom().setConnectTimeout(12000).setSocketTimeout(6000)
.setConnectionRequestTimeout(6000).build();
// 设置默认跳转以及存储cookie
httpClient = HttpClientBuilder.create()
.setKeepAliveStrategy(new DefaultConnectionKeepAliveStrategy())
.setRedirectStrategy(new DefaultRedirectStrategy()).setDefaultRequestConfig(requestConfig)
.setDefaultCookieStore(cookieStore).build();
}
...
3.3 声明一个get函数,其中header可自定义,此处不需要,但是保留着,做成一个通用的吧。
public static CloseableHttpResponse get(String url, Header[] header) throws IOException {
HttpGet httpget = new HttpGet(url);
if (header != null && header.length > 0) {
httpget.setHeaders(header);
}
CloseableHttpResponse response = httpClient.execute(httpget, context);//context用于存储上下文
return response;
}
3.4 访问首页以获得session,服务器上会话是使用session存储的,本地浏览器使用的是cookie,只要本地不退出,那么使用本地的cookie来访问也是可以的,但是为了达到模拟登陆的效果,这里就不再阐述这种方式。
CloseableHttpResponse homeResponse = get("http://www.gzlib.gov.cn/", null);
homeResponse.close();
此时,如果打印cookie,可以看到目前的cookie如下:
<RequestsCookieJar[
<Cookie JSESSIONID=54702A995ECFC684B192A86467066F20 for .gzlib.gov.cn/>,
<Cookie JSESSIONID=54702A995ECFC684B192A86467066F20 for www.gzlib.gov.cn/>,
<Cookie clientlanguage=zh_CN for www.gzlib.gov.cn/>]>
3.5 访问登陆页面,获取单点登录服务器之后的cookie,解析网页,获取自定义参数lt。这里的解析网页使用了Jsoup,语法和python中的BeautifulSoup中类似。
String loginURL = "http://login.gzlib.gov.cn/sso-server/login?service=http%3A%2F%2Fwww.gzlib.gov.cn%2Flogin.jspx%3FreturnUrl%3Dhttp%253A%252F%252Fwww.gzlib.gov.cn%252F%26locale%3Dzh_CN&appId=www.gzlib.gov.cn&locale=zh_CN";
CloseableHttpResponse loginGetResponse = get(loginURL, null);
String content = toString(loginGetResponse);
String lt = Jsoup.parse(content).select("form").select("input[name=lt]").attr("value");
loginGetResponse.close();
此时,再次查看cookie,多了一个(www.gzlib.gov.cn/sso-server):
<RequestsCookieJar[
<Cookie JSESSIONID=54702A995ECFC684B192A86467066F20 for .gzlib.gov.cn/>,
<Cookie JSESSIONID=54702A995ECFC684B192A86467066F20 for www.gzlib.gov.cn/>,
<Cookie clientlanguage=zh_CN for www.gzlib.gov.cn/>,
<Cookie JSESSIONID=9918DDF929757B244456D4ECD2DAB2CB for www.gzlib.gov.cn/sso-server/>]>
3.6 声明一个post函数,用来提交post请求,其中提交的参数默认为
public static CloseableHttpResponse postParam(String url, String parameters, Header[] headers)
throws IOException {
System.out.println(parameters);
HttpPost httpPost = new HttpPost(url);
if (headers != null && headers.length > 0) {
for (Header header : headers) {
httpPost.addHeader(header);
}
}
List<NameValuePair> nvps = toNameValuePairList(parameters);
httpPost.setEntity(new UrlEncodedFormEntity(nvps, "UTF-8"));
CloseableHttpResponse response = httpClient.execute(httpPost, context);
return response;
}
3.7 登陆成功后,如果没有声明returnurl,即登录链接为(http://login.gzlib.gov.cn/sso-server/login),那么只是会显示成功登录的页面:

后台应该是定义了一个service用来进行链接跳转的,想要获取登录成功之后的跳转页面可修改service之后的链接,这里将保持原始状态。此时,查看cookie结果如下:
<RequestsCookieJar[
<Cookie JSESSIONID=54702A995ECFC684B192A86467066F20 for .gzlib.gov.cn/>,
<Cookie JSESSIONID=54702A995ECFC684B192A86467066F20 for www.gzlib.gov.cn/>,
<Cookie clientlanguage=zh_CN for www.gzlib.gov.cn/>,
<Cookie CASTGC=TGT-198235-zkocmYyBP6c9G7EXjKyzgKR7I40QI4JBalTkrnr9U6ZkxuP6Tn for www.gzlib.gov.cn/sso-server>,
<Cookie JSESSIONID=9918DDF929757B244456D4ECD2DAB2CB for www.gzlib.gov.cn/sso-server/>]>
其中,出现CASTGC表明登陆成功了,可以使用该cookie来访问广州图书馆的其他页面,在python中是直接跳转到其他页面,而在java使用httpclient过程中,看到的并不是直接的跳转,而是一个302重定向,打印Header之后结果如下图:
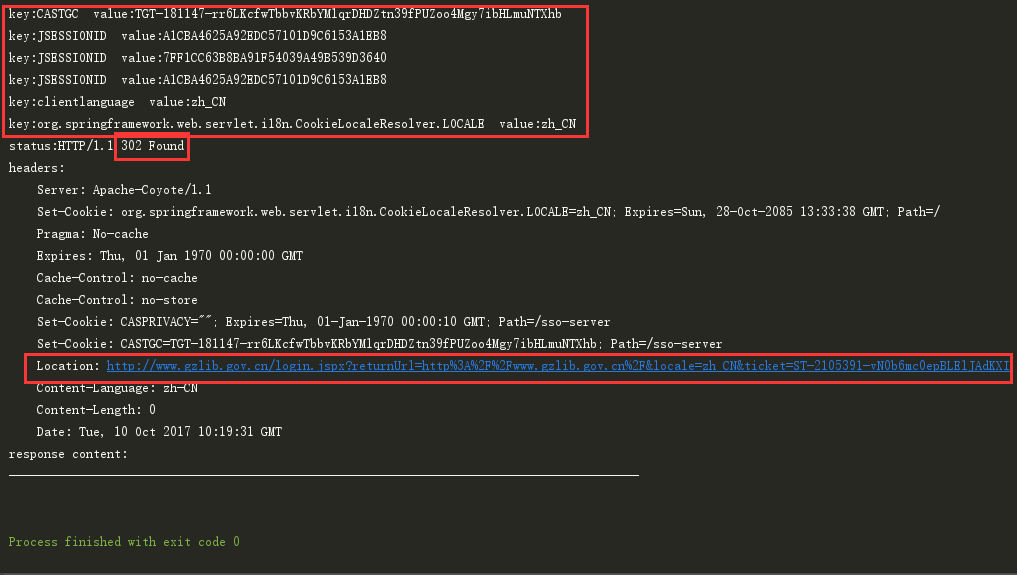
认真研究一下链接,就会发现服务器相当于给了一张通用票ticket,即:可以使用该ticket访问任何页面,而returnUrl则是返回的页面。这里我们直接访问该重定向的url。
Header header = response.getHeaders("Location")[0];
CloseableHttpResponse home = get(header.getValue(), null);
然后打印页面,即可获取登陆之后跳回的首页。
3.8 解析html
获取session并跳回首页之后,再访问借阅历史页面,然后对结果进行html解析,python中使用了BeautifulSoup,简单而又实用,java中的jsoup也是一个不错的选择。
String html = getHTML();
Element element = Jsoup.parse(html).select("table.jieyue-table").get(0).select("tbody").get(0);
Elements trs = element.select("tr");
for (int i = 0; i < trs.size(); i++) {
Elements tds = trs.get(i).select("td");
System.out.println(tds.get(1).text());
}
输出结果:
企业IT架构转型之道
大话Java性能优化
深入理解Hadoop
大话Java性能优化
Java EE开发的颠覆者:Spring Boot实战
大型网站技术架构:核心原理与案例分析
Java性能权威指南
Akka入门与实践
高性能网站建设进阶指南:Web开发者性能优化最佳实践:Performance best practices for Web developers
Java EE开发的颠覆者:Spring Boot实战
深入理解Hadoop
大话Java性能优化
点击查看源码
总结
目前,改代码已经整合进个人网站之中,每天定时抓取一次,但是仍有很多东西没有做(如分页、去重等),有兴趣的可以研究一下源码,要是能帮忙完善就更好了。感谢Thanks♪(・ω・)ノ。整个代码接近250行,当然...包括了注释,但是使用python之后,也不过25行=w=,这里贴一下python的源码吧。同时,欢迎大家访问我的个人网站,也欢迎大家能给个star。
import urllib.parse
import requests
from bs4 import BeautifulSoup
session = requests.session()
session.get("http://www.gzlib.gov.cn/")
session.headers.update(
{"Referer": "http://www.gzlib.gov.cn/member/historyLoanList.jspx",
"origin": "http://login.gzlib.gov.cn",
'Content-Type': 'application/x-www-form-urlencoded',
'host': 'www.gzlib.gov.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'
}
)
baseURL = "http://login.gzlib.gov.cn/sso-server/login"
soup = BeautifulSoup(session.get(baseURL).text, "html.parser")
lt = soup.select("form")[0].find(attrs={'name': 'lt'})['value']
postdict = {"username": "你的身份证",
"password": "密码(默认为身份证后6位)",
"_eventId": "submit",
"lt": lt
}
postdata = urllib.parse.urlencode(postdict)
session.post(baseURL, postdata)
print(session.get("http://www.gzlib.gov.cn/member/historyLoanList.jspx").text)
广州图书馆借阅抓取——httpClient的使用的更多相关文章
- [Java]使用HttpClient实现一个简单爬虫,抓取煎蛋妹子图
第一篇文章,就从一个简单爬虫开始吧. 这只虫子的功能很简单,抓取到”煎蛋网xxoo”网页(http://jandan.net/ooxx/page-1537),解析出其中的妹子图,保存至本地. 先放结果 ...
- 使用HttpClient 4.3.4 自动登录并抓取中国联通用户基本信息和账单数据,GET/POST/Cookie
一.什么是HttpClient? HTTP 协议可能是现在 Internet 上使用得最多.最重要的协议了,越来越多的 Java 应用程序需要直接通过 HTTP 协议来访问网络资源.虽然在 JDK 的 ...
- HttpClient 4.x 执行网站登录并抓取网页的代码
HttpClient 4.x 的 API 变化还是很大,这段代码可用来执行登录过程,并抓取网页. HttpClient API 文档(4.0.x), HttpCore API 文档(4.1) pack ...
- 使用java开源工具httpClient及jsoup抓取解析网页数据
今天做项目的时候遇到这样一个需求,需要在网页上展示今日黄历信息,数据格式如下 公历时间:2016年04月11日 星期一 农历时间:猴年三月初五 天干地支:丙申年 壬辰月 癸亥日 宜:求子 祈福 开光 ...
- HttpClient抓取网页内容简单介绍
版本HttpClient3.1 1.GET方式 第一步.创建一个客户端,类似于你用浏览器打开一个网页 HttpClient httpClient = new HttpClient(); 第二步.创建一 ...
- 利用HttpClient抓取话费详单等信息
由于项目需要,需要获取授权用户的在运营商(中国移动.中国联通.中国电信)那里的个人信息.话费详单.月汇总账单信息(需要指出的是电信用户的个人信息无法从网上营业厅获取).抓取用户信息肯定是要模仿用户登录 ...
- HTTPCLIENT抓取网页内容
通过httpclient抓取网页信息. public class SnippetHtml{ /** * 通过url获取网站html * @param url 网站url */ public Strin ...
- HttpClient+Jsoup 抓取网页信息(网易贵金属为例)
废话不多说直接讲讲今天要做的事. 利用HttpClient和Jsoup技术抓取网页信息.HttpClient是支持HTTP协议的客户端编程工具包,并且它支持HTTP协议. jsoup 是一款基于 Ja ...
- HttpClient(一)HttpClient抓取网页基本信息
一.HttpClient简介 HttpClient 是 Apache Jakarta Common 下的子项目,可以用来提供高效的.最新的.功能丰富的支持 HTTP 协议的客户端编程工具包, 并且它支 ...
随机推荐
- RadioButtonList控件如何取得选中的值
1.需求:我现在页面上有放两个单选控件,现在要通过判断不同的单选控件来对页面上的标签进行显示和隐藏操作 2.控件如下 <asp:RadioButtonList ID=" RepeatD ...
- GUI线程 :打字母游戏
代码: /** * */ package com.niit.syntronized; import java.awt.Color; import java.awt.FlowLayout; import ...
- 【Alpha】Daily Scrum Meeting——Day5
站立式会议照片 1.本次会议为第五次Meeting会议: 2.本次会议在上午大课间09:40,在陆大楼召开,本次会议为30分钟讨论昨天的任务完成情况以及接下来的任务安排. 燃尽图 每个人的工作分配 成 ...
- 201521123049 《JAVA程序设计》 第4周学习总结
1. 本周学习总结 1.1 尝试使用思维导图总结有关继承的知识点. 1.2 使用常规方法总结其他上课内容. ###1.类型转换(cast):是将两种不同类型的变量进行转换,但不能随意强制转换,随意强制 ...
- 201521123010 《Java程序设计》第2周学习总结
1. 本周学习总结 这周学习了在JAVA里各种数据类型的使用.各种运算符的使用.表达是的使用,还初步学习了枚举的用法,也掌握了一些枚举和switch语句结合的用法,还了解了一些字符串类.在实验课上也学 ...
- 201521123080《Java程序设计》第2周学习总结
1.本周学习总结 a.学习了如何建立远程仓库和本地仓库并建立连接. b.学习了一些基础语法. 2.书面作业 Q1.使用Eclipse关联jdk源代码,并查看String对象的源代码(截图)?分析Str ...
- 201521123006 《Java程序设计》第1周学习总结
1. 本章学习总结 (1)java在使用的过程中可以发现其本身有着许多为了节约资源而作的设计,而java根据其应用领域分为了三大平台:Java SE.Java ME与Java EE.在本周的学习中我们 ...
- Hyperledger Fabric 1.0 从零开始(六)——创建Fabric多节点集群
4:创建Fabric多节点集群 4.1.配置说明 首先可以根据官方Fabric自带的e2e_cli列子中的集群方案来生成我们自己的集群,与案例不同的是我们需要把容器都分配到不同的服务器上,彼此之间通过 ...
- [Android FrameWork 6.0源码学习] View的重绘过程之Draw
View绘制的三部曲,测量,布局,绘画现在我们分析绘画部分测量和布局 在前两篇文章中已经分析过了.不了解的可以去我的博客里找一下 下面进入正题,开始分析调用以及函数原理 private void pe ...
- LINUX - awk命令之NF和$NF区别 (转)
NF和$NF 区别问答:(转)1.awk中$NF是什么意思?#pwd/usr/local/etc~# echo $PWD | awk -F/ '{print $NF}'etcNF代表:浏览记录的域的个 ...