TensorFlow多线程输入数据处理框架(二)——输入文件队列
参考书
《TensorFlow:实战Google深度学习框架》(第2版)
一个简单的程序来生成样例数据。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8 """
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: sample_data_produce1.py
@time: 2019/2/3 21:46
@desc: 一个简单的程序来生成样例数据
""" import tensorflow as tf # 创建TFRecord文件的帮助函数
def _int64_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value])) # 模拟海量数据情况下将数据写入不同的文件。num_shards定义了总共写入多少个文件
# instances_per_shard定义了每个文件中有多少个数据
num_shards = 2
instances_per_shard = 2
for i in range(num_shards):
# 将数据分为多个文件时,可以将不同文件以类似0000n-of-0000m的后缀区分。其中m表示了
# 数据总共被存在了多少个文件,n表示当前文件的编号。式样的方式既方便了通过正则表达式
# 获取文件列表,又在文件名中加入了更多的信息。
filename = ('./data.tfrecords-%.5d-of-%0.5d' % (i, num_shards))
writer = tf.python_io.TFRecordWriter(filename)
# 将数据封装成Example结构并写入TFRecord文件
for j in range(instances_per_shard):
# Example结构仅包含当前样例属于第几个文件以及是当前文件的第几个样本
example = tf.train.Example(features=tf.train.Features(feature={
'i': _int64_feature(i),
'j': _int64_feature(j)
}))
writer.write(example.SerializeToString())
writer.close()
运行结果:

展示了tf.train.match_filenames_once函数和tf.train.string_input_producer函数的使用方法。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8 """
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: sample_data_deal1.py
@time: 2019/2/3 22:00
@desc: 展示了tf.train.match_filenames_once函数和tf.train.string_input_producer函数的使用方法
""" import tensorflow as tf # 使用tf.train.match_filenames_once函数获取文件列表
files = tf.train.match_filenames_once('./data.tfrecords-*') # 通过tf.train.string_input_producer函数创建输入队列,输入队列中的文件列表为
# tf.train.match_filenames_once函数获取的文件列表。这里将shuffle参数设为False
# 来避免随机打乱读文件的顺序。但一般在解决真实问题时,会将shuffle参数设置为True
filename_queue = tf.train.string_input_producer(files, shuffle=False) # 如前面所示读取并解析一个样本
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue)
features = tf.parse_single_example(
serialized_example,
features={
'i': tf.FixedLenFeature([], tf.int64),
'j': tf.FixedLenFeature([], tf.int64),
}
) with tf.Session() as sess:
# 虽然在本段程序中没有声明任何变量,但使用tf.train.match_filenames_once函数时
# 需要初始化一些变量。
tf.local_variables_initializer().run()
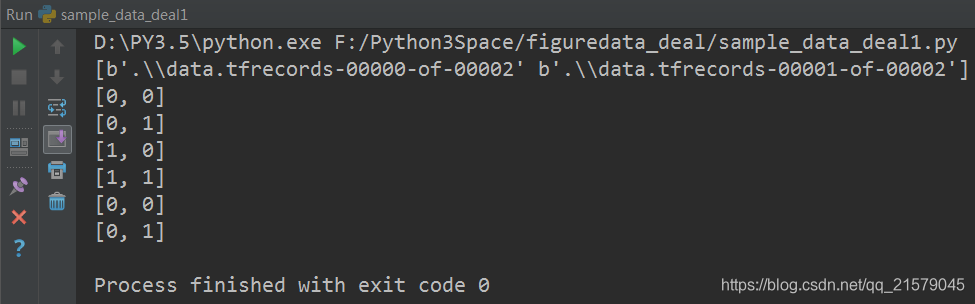
print(sess.run(files)) # 声明tf.train.Coordinator类来协同不同线程,并启动线程。
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord) # 多次执行获取数据的操作
for i in range(6):
print(sess.run([features['i'], features['j']])) # 请求处理的线程停止
coord.request_stop()
# 等待,直到处理的线程已经停止
coord.join(threads)
运行结果:
TensorFlow多线程输入数据处理框架(二)——输入文件队列的更多相关文章
- TensorFlow多线程输入数据处理框架(四)——输入数据处理框架
参考书 <TensorFlow:实战Google深度学习框架>(第2版) 输入数据处理的整个流程. #!/usr/bin/env python # -*- coding: UTF-8 -* ...
- Tensorflow多线程输入数据处理框架(一)——队列与多线程
参考书 <TensorFlow:实战Google深度学习框架>(第2版) 对于队列,修改队列状态的操作主要有Enqueue.EnqueueMany和Dequeue.以下程序展示了如何使用这 ...
- Tensorflow多线程输入数据处理框架
Tensorflow提供了一系列的对图像进行预处理的方法,但是复杂的预处理过程会减慢整个训练过程,所以,为了避免图像的预处理成为训练神经网络效率的瓶颈,Tensorflow提供了多线程处理输入数据的框 ...
- TensorFlow多线程输入数据处理框架(三)——组合训练数据
参考书 <TensorFlow:实战Google深度学习框架>(第2版) 通过TensorFlow提供的tf.train.batch和tf.train.shuffle_batch函数来将单 ...
- tensorflow学习笔记——多线程输入数据处理框架
之前我们学习使用TensorFlow对图像数据进行预处理的方法.虽然使用这些图像数据预处理的方法可以减少无关因素对图像识别模型效果的影响,但这些复杂的预处理过程也会减慢整个训练过程.为了避免图像预处理 ...
- 吴裕雄--天生自然 pythonTensorFlow图形数据处理:输入数据处理框架
import tensorflow as tf # 1. 创建文件列表,通过文件列表创建输入文件队列 files = tf.train.match_filenames_once("F:\\o ...
- 吴裕雄 python 神经网络——TensorFlow 输入数据处理框架
import tensorflow as tf files = tf.train.match_filenames_once("E:\\MNIST_data\\output.tfrecords ...
- 大数据处理框架之Strom:认识storm
Storm是分布式实时计算系统,用于数据的实时分析.持续计算,分布式RPC等. (备注:5种常见的大数据处理框架:· 仅批处理框架:Apache Hadoop:· 仅流处理框架:Apache Stor ...
- Java 多线程基础(十二)生产者与消费者
Java 多线程基础(十二)生产者与消费者 一.生产者与消费者模型 生产者与消费者问题是个非常典型的多线程问题,涉及到的对象包括“生产者”.“消费者”.“仓库”和“产品”.他们之间的关系如下: ①.生 ...
随机推荐
- FastDFS的配置、部署与API使用解读(1)Get Started with FastDFS(转)
转载请注明来自:诗商·柳惊鸿CSDN博客,原文链接:FastDFS的配置.部署与API使用解读(1)入门使用教程 1.背景 FastDFS是一款开源的.分布式文件系统(Distributed File ...
- 使用Poi对EXCLE的导入导出
import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException; import ...
- busybox 终端支持 ctrl-r
Busybox Settings ---> Busybox Library Tuning ---> [*] History saving [ ] Save history on shell ...
- MySQL优化之——触发器
转载请注明出处:http://blog.csdn.net/l1028386804/article/details/46763665 触发器是一个特殊的存储过程,不同的是存储过程要用CALL来调用,而触 ...
- NettyIO
- opencv VS2010配置
一.下载 opencv下载地址:http://www.opencv.org.cn/ 点击下载栏 最新的可能有3.2了,但是支持的VS版本是VS2012等版本.这里只选用2.4.9版本 下载后就是安装 ...
- mysql优化-----索引覆盖
一道面试题: 有商品表, 有主键,goods_id, 栏目列 cat_id, 价格price 说:在价格列上已经加了索引,但按价格查询还是很慢,问可能是什么原因,怎么解决? 答:在实际场景中,一个电商 ...
- java 获取路径
1.利用System.getProperty()函数获取当前路径:System.out.println(System.getProperty("user.dir"));//user ...
- BestCoder4 1002 Miaomiao's Geometry (hdu 4932) 解题报告
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=4932 题目意思:给出 n 个点你,需要找出最长的线段来覆盖所有的点.这个最长线段需要满足两个条件:(1 ...
- hdu 2594 Simpsons’ Hidden Talents(两个串的next数组)
题意:两个字符串s.t,求s和t的最长的相同的前缀和后缀 思路:先求s的next数组,再求t的next数组(即代码中ex数组,此时不是自己与自己匹配,而是与s匹配),最后看ex[len2]即可(len ...