[scrapy]Item Loders
Items
Items就是结构化数据的模块,相当于字典,比如定义一个{"title":"","author":""},items_loders就是从网页中提取title和author字段填充到items里,比如{"title":"初学scrapy","author":"Alex"},然后items把结构化的数据传给pipeline,pipeline可以把数据插入进MySQL里.
实例
items.py
import scrapy class JobBoleArticleItem(scrapy.Item):
title = scrapy.Field()
create_date = scrapy.Field()
url = scrapy.Field()
url_object_id = scrapy.Field()
front_image_url = scrapy.Field()
front_image_path = scrapy.Field()
praise_nums = scrapy.Field()
comment_nums = scrapy.Field()
fav_nums = scrapy.Field()
jobbole.py
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request
from scrapy.loader import ItemLoader from urllib import parse
import re
import datetime
from ArticleSpider.items import JobBoleArticleItem from utils.common import get_md5 class JpbboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/all-posts/'] #先下载http://blog.jobbole.com/all-posts/这个页面,然后传给parse解析 def parse(self, response): #1.start_urls下载页面http://blog.jobbole.com/all-posts/,然后交给parse解析,parse里的post_urls获取这个页面的每个文章的url,Request下载每个文章的页面,然后callback=parse_detail,交给parse_detao解析
#2.等post_urls这个循环执行完,说明这一个的每个文章都已经解析完了, 就执行next_url,next_url获取下一页的url,然后Request下载,callback=self.parse解析,parse从头开始,先post_urls获取第二页的每个文章的url,然后循环每个文章的url,交给parse_detail解析 #获取http://blog.jobbole.com/all-posts/中所有的文章url,并交给Request去下载,然后callback=parse_detail,交给parse_detail解析
post_nodes = response.css("#archive .floated-thumb .post-thumb a")
for post_node in post_nodes:
image_url = post_node.css("img::attr(src)").extract_first("")
post_url = post_node.css("::attr(href)").extract_first("")
yield Request(url=parse.urljoin(response.url,post_url),meta={"front_image_url":image_url},callback=self.parse_detail) #获取下一页的url地址,交给Request下载,然后交给parse解析
next_url = response.css(".next.page-numbers::attr(href)").extract_first("")
if next_url:
yield Request(url=next_url,callback=self.parse) def parse_detail(self,response): article_item = JobBoleArticleItem() #实例化定义的items item_loader = ItemLoader(item=JobBoleArticleItem(),response=response) #实例化item_loader,把我们定义的item传进去,再把下载器下载的网页穿进去
#针对直接取值的情况
item_loader.add_value("url",response.url)
item_loader.add_value("url_object_id",get_md5(response.url))
item_loader.add_value("front_image_url",[front_image_url])
#针对css选择器
item_loader.add_css("title",".entry-header h1::text")
item_loader.add_css("create_date","p.entry-meta-hide-on-mobile::text")
item_loader.add_css("praise_nums",".vote-post-up h10::text")
item_loader.add_css("comment_nums","a[href='#article-comment'] span::text")
item_loader.add_css("fav_nums",".bookmark-btn::text")
#把结果返回给items
article_item = item_loader.load_item()
- .add_value:把直接获取到的值,复制给字段
- .add_css:需要通过css选择器获取到的值
- .add_xpath:需要通过xpath选择器获取到的值
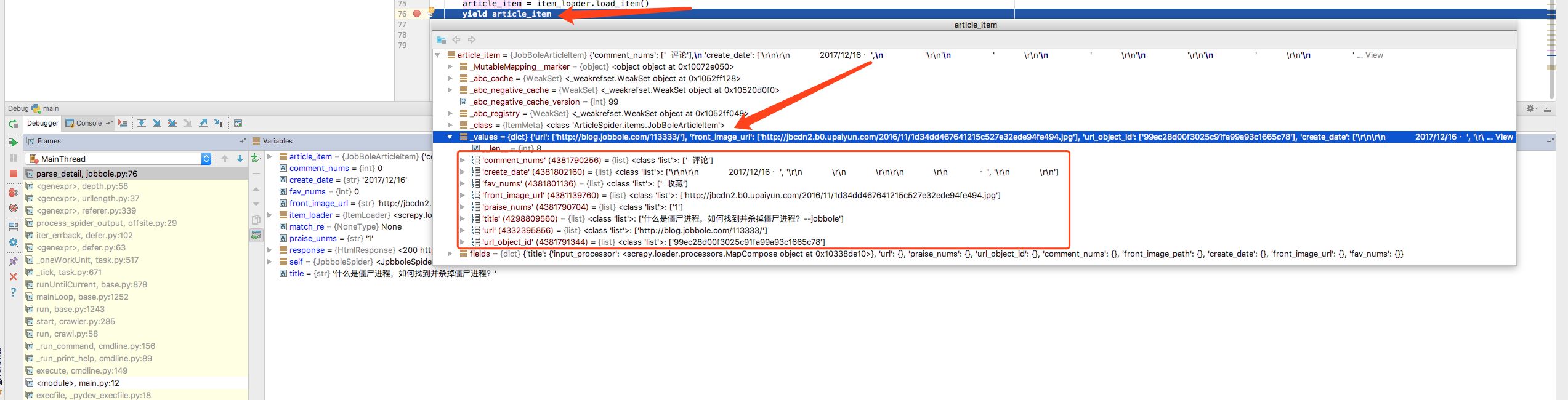
debug调试,可以看到拿到的信息
[scrapy]Item Loders的更多相关文章
- 第三百四十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制
第三百四十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制 用命令创建自动爬虫文件 创建爬虫文件是根据scrap ...
- 二十三 Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制
用命令创建自动爬虫文件 创建爬虫文件是根据scrapy的母版来创建爬虫文件的 scrapy genspider -l 查看scrapy创建爬虫文件可用的母版 Available templates: ...
- scrapy item
item item定义了爬取的数据的model item的使用类似于dict 定义 在items.py中,继承scrapy.Item类,字段类型scrapy.Field() 实例化:(假设定义了一个名 ...
- 第十篇 scrapy item loader机制
在我们执行scrapy爬取字段中,会有大量的和下面的代码,当要爬取的网站多了,要维护起来很麻烦,为解决这类问题,我们可以根据scrapy提供的loader机制 def parse_detail(sel ...
- scrapy item pipeline
item pipeline process_item(self, item, spider) #这个是所有pipeline都必须要有的方法在这个方法下再继续编辑具体怎么处理 另可以添加别的方法 ope ...
- 使用sqlalchemy用orm方式写pipeline将scrapy item快速存入 MySQL
传统的使用scrapy爬下来的数据存入mysql,用的是在pipeline里用pymysql存入数据库, 这种方法需要写sql语句,如果item字段数量非常多的 情况下,编写起来会造成很大的麻烦. 我 ...
- Scrapy Item用法示例(保存item到MySQL数据库,MongoDB数据库,使用官方组件下载图片)
需要学习的地方: 保存item到MySQL数据库,MongoDB数据库,下载图片 1.爬虫文件images.py # -*- coding: utf-8 -*- from scrapy import ...
- scrapy item处理----cooperator和parallel()函数
twisted的task之cooperator和scrapy的parallel()函数 本文是关于下载结果返回后调用item处理的过程实现研究. 从scrapy的结果处理说起 def handle_s ...
- Scrapy系列教程(2)------Item(结构化数据存储结构)
Items 爬取的主要目标就是从非结构性的数据源提取结构性数据,比如网页. Scrapy提供 Item 类来满足这种需求. Item 对象是种简单的容器.保存了爬取到得数据. 其提供了 类似于词典(d ...
随机推荐
- 蓝牙学习 (6) - Play with TI sensorTag (1)
硬件 cc2650 SensorTag Connect with App 在手机上安装Ti提供的sensorTag App即可和sensorTag 建立连接. 如下手机截图,
- laravel中对加载进行优化
在laravel中的模型与模型之间创建好关联关系会比较方便的方法 但是我们为了方便,有时也会忽略一些东西,比如: 我们在控制器中把整个一个文章对象传到了模板页面 在一次for循环下, 我们对数据进行了 ...
- python 中变量和对象
1. 在 python 中,类型属于对象,变量是没有类型的:a=[1,2,3] a="Runoob"以上代码中,[1,2,3] 是 List 类型,"Runoob&quo ...
- 模板<最小生成树>
转载 最小生成树浅谈 这里介绍最小生成树的两种方法:Prim和Kruskal. 两者区别:Prim在稠密图中比Kruskal优,在稀疏图中比Kruskal劣.Prim是以更新过的节点的连边找最小值,K ...
- Hive 执行sql命令报错
Failed with exception java.io.IOException:java.lang.IllegalArgumentException: java.net.URISyntaxExce ...
- 面试准备——redis
https://blog.csdn.net/yangzhong0808/article/details/81196472 http://www.imooc.com/article/36399 http ...
- SQL server游标基本结构
简单游标遍历数据: BEGIN DECLARE QZ_cursor CURSOR SCROLL FOR /*创建游标*/ SELECT NAME FROM USERINFO/*要遍历的数据*/ OPE ...
- AbstractFactory(抽象工厂模式)
AbstractFactory(抽象工厂模式) 有些情况下我们需要根据不同的选择逻辑提供不同的构造工厂,而对于多个工厂而言需要一个统一的抽象 <?php class Config { publi ...
- [uiautomator篇][python] wifi接口学习网址
https://wifi.readthedocs.io/en/latest/wifi_command.html#usage
- 【软考2】Java语言的基本知识汇总
导读:现在对于java这一模块,还没有相应的项目经验,只是通过各种类型的资料,对java有一个面上的了解.现在,对此做一个罗列总结,在以后的学习过程中,逐步完善! 一.语言的发展 1.1,机器语言 在 ...