第2节 hive基本操作:6、7、8
第1节 hive安装:6、hive的基本操作;7、创建数据库的语法;8、hive当中创建内部表的语法。
hive的基本操作:
创建数据库与创建数据库表操作
创建数据库操作:create database if not exists xxx;
创建数据库表的操作:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name 创建表的三个关键字段
[(col_name data_type [COMMENT col_comment], ...)] 定义我们的列名,以及列的类型
[COMMENT table_comment] 注释信息,只能用英文或者拼音,不接受中文
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] 分区:这里的是hive的分区,分的是文件夹
[CLUSTERED BY (col_name, col_name, ...) 分桶:按照字段进行划分文件
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] stored by 划分到多少个桶里面去
[ROW FORMAT row_format] 指定字段之间的分隔符
[STORED AS file_format] 数据的存储格式为哪一种
[LOCATION hdfs_path] 指定我们这个表在hdfs的哪一个位置
hive当中的第一种表模型:管理表 又叫做 内部表
最明显的一个特征:删除表的时候,会把hdfs的数据同步删除
创建内部表的语法 create table stu (id int ,name string);
注意创建内部表不要带external关键字
创建内部表:指定分隔符,指定文件存储格式,指定hdfs的存放位置
create table if not exists stu2(id int ,name string ) row format delimited fields terminated by '\t' stored as textfile location '/user/stu2';
根据查询结果创建表
create table stu3 as select * from stu2; 这种语法就会把我们stu2里面的数据以及表结构都复制到stu3里面来
复制表结构
create table stu4 like stu2; 只会把stu2的表结构复制给stu4 ,不会复制数据
======================================================================
3.1、创建数据库与创建数据库表
创建数据库操作
创建数据库
create database if not exists myhive;
use myhive;
说明:hive的表存放位置模式是由hive-site.xml当中的一个属性指定的
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value> 《不配置的话,默认值就是这个》
创建数据库并指定hdfs存储位置
create database myhive2 location '/myhive2';
修改数据库
可以使用alter database 命令来修改数据库的一些属性。但是数据库的元数据信息是不可更改的,包括数据库的名称以及数据库所在的位置
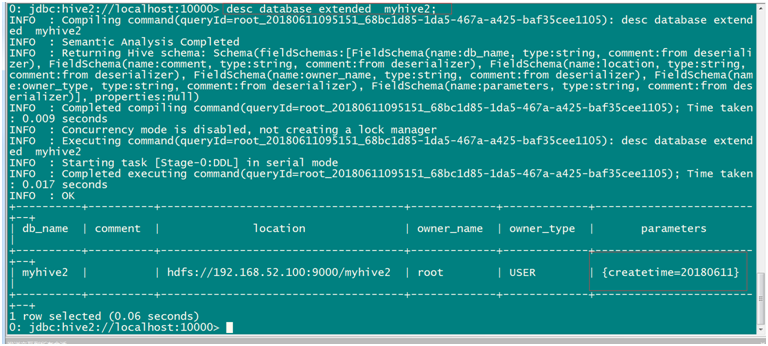
alter database myhive2 set dbproperties('createtime'='20180611');
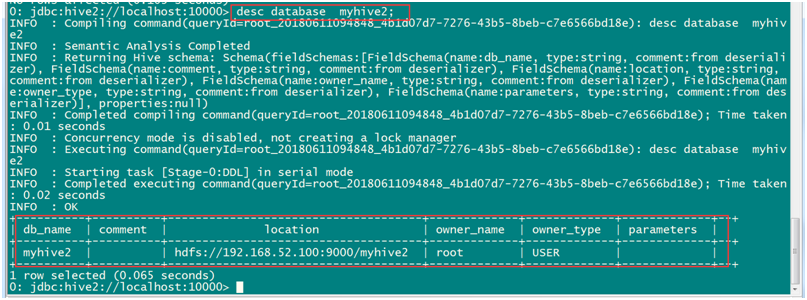
查看数据库详细信息
查看数据库基本信息
desc database myhive2;
查看数据库更多详细信息
desc database extended myhive2;
删除数据库
删除一个空数据库,如果数据库下面有数据表,那么就会报错
drop database myhive2;
强制删除数据库,包含数据库下面的表一起删除
drop database myhive cascade; 不要执行了
创建数据库表操作
创建数据库表语法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
说明:
1、CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXISTS 选项来忽略这个异常。
2、EXTERNAL关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION),Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。
3、LIKE 允许用户复制现有的表结构,但是不复制数据。
4、ROW FORMAT DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char] [MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char] | SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
用户在建表的时候可以自定义 SerDe 或者使用自带的 SerDe。如果没有指定 ROW FORMAT 或者 ROW FORMAT DELIMITED,将会使用自带的 SerDe。在建表的时候,用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的 SerDe,Hive通过 SerDe 确定表的具体的列的数据。
5、STORED AS
SEQUENCEFILE|TEXTFILE|RCFILE
如果文件数据是纯文本,可以使用 STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCEFILE。
6、CLUSTERED BY
对于每一个表(table)或者分区, Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分。Hive也是 针对某一列进行桶的组织。Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
把表(或者分区)组织成桶(Bucket)有两个理由:
(1)获得更高的查询处理效率。桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map-side join)高效的实现。比如JOIN操作。对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量。
(2)使取样(sampling)更高效。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便。
管理表
hive建表初体验
use myhive;
create table stu(id int,name string);
insert into stu values (1,"zhangsan");
select * from stu;
Hive建表时候的字段类型
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Types
|
分类 |
类型 |
描述 |
字面量示例 |
|
原始类型 |
BOOLEAN |
true/false |
TRUE |
|
TINYINT |
1字节的有符号整数 -128~127 |
1Y |
|
|
SMALLINT |
2个字节的有符号整数,-32768~32767 |
1S |
|
|
INT |
4个字节的带符号整数 |
1 |
|
|
BIGINT |
8字节带符号整数 |
1L |
|
|
FLOAT |
4字节单精度浮点数1.0 |
||
|
DOUBLE |
8字节双精度浮点数 |
1.0 |
|
|
DEICIMAL |
任意精度的带符号小数 |
1.0 |
|
|
STRING |
字符串,变长 |
“a”,’b’ |
|
|
VARCHAR |
变长字符串 |
“a”,’b’ |
|
|
CHAR |
固定长度字符串 |
“a”,’b’ |
|
|
BINARY |
字节数组 |
无法表示 |
|
|
TIMESTAMP |
时间戳,毫秒值精度 |
122327493795 |
|
|
DATE |
日期 |
‘2016-03-29’ |
|
|
时间频率间隔 |
|||
|
复杂类型 |
ARRAY |
有序的的同类型的集合 |
array(1,2) |
|
MAP |
key-value,key必须为原始类型,value可以任意类型 |
map(‘a’,1,’b’,2) |
|
|
STRUCT |
字段集合,类型可以不同 |
struct(‘1’,1,1.0), named_stract(‘col1’,’1’,’col2’,1,’clo3’,1.0) |
|
|
UNION |
在有限取值范围内的一个值 |
create_union(1,’a’,63) |
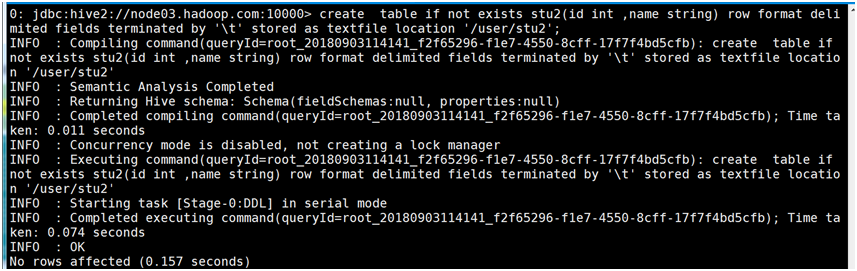
创建表并指定字段之间的分隔符
create table if not exists stu2(id int ,name string) row format delimited fields terminated by '\t' stored as textfile location '/user/stu2';
根据查询结果创建表
create table stu3 as select * from stu2;(拷贝表结构和数据)
根据已经存在的表结构创建表
create table stu4 like stu2; (只拷贝表结构)
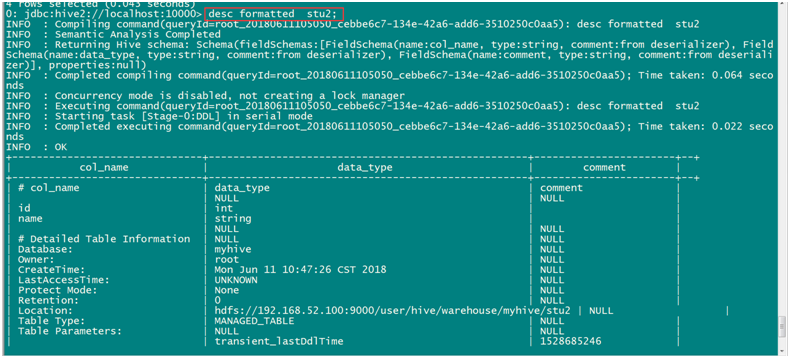
查询表的类型
desc formatted stu2;
第2节 hive基本操作:6、7、8的更多相关文章
- 第2节 hive基本操作:12、hive当中的hql语法
3.2. hive查询语法 3.2.1.SELECT https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Select 基本 ...
- 第2节 hive基本操作:11、hive当中的分桶表以及修改表删除表数据加载数据导出等
分桶表 将数据按照指定的字段进行分成多个桶中去,说白了就是将数据按照字段进行划分,可以将数据按照字段划分到多个文件当中去 开启hive的桶表功能 set hive.enforce.bucketing= ...
- 第2节 hive基本操作:10、外部分区表综合练习
外部分区表综合练习: 需求描述:现在有一个文件score.csv文件,存放在集群的这个目录下/export/servers/scoredatas/month=201806,这个文件每天都会生成,存放到 ...
- 第2节 hive基本操作:9、hive当中创建外部表的语法及外部表的操作&分区表的语法和操作
外部表: 外部表说明: 外部表因为是指定其他的hdfs路径的数据加载到表当中来,所以hive表会认为自己不完全独占这份数据,所以删除hive表的时候,数据仍然存放在hdfs当中,不会删掉 管理表和外部 ...
- 第3节 hive高级用法:16、17、18
第3节 hive高级用法:16.hive当中常用的几种数据存储格式对比:17.存储方式与压缩格式相结合:18.总结 hive当中的数据存储格式: 行式存储:textFile sequenceFile ...
- 第1节 hive安装:2、3、4、5、(多看几遍)
第1节 hive安装: 2.数据仓库的基本概念: 3.hive的基本介绍: 4.hive的基本架构以及与hadoop的关系以及RDBMS的对比等 5.hive的安装之(使用mysql作为元数据信息存储 ...
- hive学习3(hive基本操作)
hive基本操作 hive的数据类型 1)基本数据类型 TINYINT,SMALLINT,INT,BIGINT FLOAT/DOUBLE BOOLEAN STRING 2)复合类型 ARRAY:一组有 ...
- 第4节 hive调优:2、数据倾斜
数据的倾斜: 主要就是合理的控制我们的map个数以及reduce个数 第一个问题:maptask的个数怎么定的???与我们文件的block块相关,默认一个block块就是对应一个maptask 第二个 ...
- 【hive】——Hive基本操作
阅读本文章可以带着下面问题:1.与传统数据库对比,找出他们的区别2.熟练写出增删改查(面试必备) 创建表:hive> CREATE TABLE pokes (foo INT, bar STRIN ...
随机推荐
- BZOJ_3881_[Coci2015]Divljak_AC自动机+dfs序+树状数组
BZOJ_3881_[Coci2015]Divljak_AC自动机+dfs序+树状数组 Description Alice有n个字符串S_1,S_2...S_n,Bob有一个字符串集合T,一开始集合是 ...
- HDU 4891 The Great Pan (题意题+模拟)
题意:给定一个文章,问你有多少种读法,计算方法有两种,如果在$中,如果有多个空格就算n+1,如果是一个就算2的次方,如果在{}中, 那么就是把每个空格数乘起来. 析:直接模拟,每次计算一行,注意上一行 ...
- bzoj 3629: [JLOI2014]聪明的燕姿【线性筛+dfs】
数论+爆搜 详见这位大佬https://blog.csdn.net/eolv99/article/details/39644419 #include<iostream> #include& ...
- 徐州联赛选拔赛 - 计算IP地址值
题目链接 思路:这是一道非常简单的题目,直接用公式计算就好了.对于IP地址a.b.c.d,转换为十进制数就是(a<<24)|(b<<16)|(c<<8)|d.唯一要 ...
- 百度地图API详细介绍
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <t ...
- [ZPG TEST 117] 跑路【构图】
一看懵了,求一条路的长度whose二进制位中1的个数最小?什么鬼. 其实这种n这么小的图论题,应该往Floyd上想了.令f(p, i, j)为从i走长度为2^p长度的路能否到j,若能,则在一张新的图上 ...
- CodeForces 923C Perfect Security
C. Perfect Security time limit per test3.5 seconds memory limit per test512 megabytes inputstandard ...
- multiset || 线段树 HDOJ 4302 Holedox Eating
题目传送门 题意:一个长度L的管子,起点在0.n次操作,0 p表示在p的位置放上蛋糕,1表示去吃掉最近的蛋糕(如果左右都有蛋糕且距离相同,那么吃同方向的蛋糕),问最终走了多少路程 分析:用multis ...
- 找规律 Codeforces Round #309 (Div. 2) A. Kyoya and Photobooks
题目传送门 /* 找规律,水 */ #include <cstdio> #include <iostream> #include <algorithm> #incl ...
- IOS利用Core Text对文字进行排版 - 转
原贴地址:http://hi.baidu.com/jwq359699768/blog/item/5df305c893413d0a7e3e6f7b.html core text 这个包默认是没有的,要自 ...