sqoop2-1.99.5-cdh5.5.4.tar.gz的部署搭建
不多说,直接上干货!
首先,说下博主我,为什么,好端端的Sqoop1用的好好的,然后又安装和学习Sqoop2?
因为,在Cloudera Hue里的Sqoop,是需要Sqoop2。
HUE配置文件hue.ini 的sqoop模块详解(图文详解)(分HA集群)

Sqoop2安装简介
sqoop2的安装分为server端和client端。
server端:负责与hadoop集群通信进行数据的迁移,client端负责与用户和server交互。
client端:不用安装, 只需要将其安装包解压到集群中任何的机器上去,然后对其进行解压即可, 无需其他额外的配置。
Sqoop分client和server,server安装在Hadoop或Spark集群中的某个节点上,这个节点充当要连接sqoop的入口节点,
client端不需要安装hadoop。
本博文是个入门,即只在bigdatamaster上安装server端。当然你也可以假设认为server和client都在bigdatamaster上哈。
对于Sqoop和hive这样的组件,我一般都是安装在master节点,即在本博客里是bigdatamaster。
http://archive.cloudera.com/cdh5/cdh/5/sqoop2-1.99.5-cdh5.5.4.tar.gz

[hadoop@bigdatamaster app]$ cd sqoop
[hadoop@bigdatamaster sqoop]$ pwd
/home/hadoop/app/sqoop
[hadoop@bigdatamaster sqoop]$ ll
total
drwxr-xr-x hadoop hadoop Apr bin
-rw-r--r-- hadoop hadoop Apr CHANGELOG.txt
drwxr-xr-x hadoop hadoop Apr client
drwxr-xr-x hadoop hadoop Apr cloudera
drwxr-xr-x hadoop hadoop Apr common
drwxr-xr-x hadoop hadoop Apr common-test
drwxr-xr-x hadoop hadoop Apr connector
drwxr-xr-x hadoop hadoop Apr core
drwxr-xr-x hadoop hadoop Apr dev-support
drwxr-xr-x hadoop hadoop Apr dist
drwxr-xr-x hadoop hadoop Apr docs
drwxr-xr-x hadoop hadoop Apr execution
-rw-r--r-- hadoop hadoop Apr LICENSE.txt
-rw-r--r-- hadoop hadoop Apr NOTICE.txt
-rw-r--r-- hadoop hadoop Apr pom.xml
-rw-r--r-- hadoop hadoop Apr README.txt
drwxr-xr-x hadoop hadoop Apr repository
drwxr-xr-x hadoop hadoop Apr security
drwxr-xr-x hadoop hadoop Apr server
drwxr-xr-x hadoop hadoop Apr shell
drwxr-xr-x hadoop hadoop Apr submission
drwxr-xr-x hadoop hadoop Apr test
drwxr-xr-x hadoop hadoop Apr tomcat
drwxr-xr-x hadoop hadoop Apr tools
[hadoop@bigdatamaster sqoop]$
配置环境变量

[hadoop@bigdatamaster sqoop]$ su root
Password:
[root@bigdatamaster sqoop]# vim /etc/profile
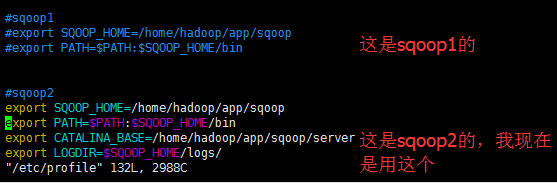
#sqoop1
#export SQOOP_HOME=/home/hadoop/app/sqoop
#export PATH=$PATH:$SQOOP_HOME/bin #sqoop2
export SQOOP_HOME=/home/hadoop/app/sqoop
export PATH=$PATH:$SQOOP_HOME/bin
export CATALINA_BASE=/home/hadoop/app/sqoop/server
export LOGDIR=$SQOOP_HOME/logs/
对于Sqoop2的server端安装配置(说明)
- 解压软件包到一个目录下。(我一般是放在/home/hadoop/app下)
- 修改环境变
export SQOOP_HOME=/home/hadoop/app/sqoop (因为我是用的软链接)
export PATH=$PATH:$SQOOP_HOME/bin
export CATALINA_BASE=$SQOOP_HOME/server
export LOGDIR=$SQOOP_HOME/logs/ - 生效环境变量的配置
- source 配置文件名
修改sqoop配置:
vi server/conf/sqoop.properties
将org.apache.sqoop.submission.engine.mapreduce.configuration.directory后面hadoop的位置修改为自己安装的hadoop配置文件位置,我的为:/home/hadoop/app/hadoop/修改sqoop读取hadoop的jar包的路径 vi /sqoop/server/conf/catalina.properties
将common.loader行后的/usr/lib/hadoop/lib/.jar改成自己的hadoop jar 包目录,我的为:
/home/hadoop/app/hadoop/share/hadoop/common/.jar,
/home/hadoop/app/hadoop/share/hadoop/common/lib/.jar,
/home/hadoop/app/hadoop/share/hadoop/hdfs/.jar,
/home/hadoop/app/hadoop/share/hadoop/hdfs/lib/.jar,
/home/hadoop/app/hadoop/share/hadoop/mapreduce/.jar,
/home/hadoop/app/hadoop/share/hadoop/mapreduce/lib/.jar,
/home/hadoop/app/hadoop/share/hadoop/tools/.jar,
/home/hadoop/app/hadoop/share/hadoop/tools/lib/.jar,
/home/hadoop/app/hadoop/share/hadoop/yarn/.jar,
/home/hadoop/app/hadoopshare/hadoop/yarn/lib/*.jar
注意: 在修改common.loader的过程中, 不能换行
本步骤的另外的一种方法是: 直接将上诉的包 拷贝到$SQOOP_HOME/server/lib文件夹内部- 将mysql的连接jar包拷贝的$SQOOP_HOME/lib文件夹中(lib文件夹需要自己创建)到此sqoop就基本配置完成可以直接运行.
下面是,对sqoop2的配置文件进行配置
1、修改$SQOOP_HOME/server/conf/catalina.properties文件中的common.loader属性,在其后增加(写到一行):
$HADOOP_HOME/share/hadoop/common/*.jar,
$HADOOP_HOME/share/hadoop/common/lib/*.jar,
$HADOOP_HOME/share/hadoop/yarn/*.jar,
$HADOOP_HOME/share/hadoop/hdfs/*.jar,
$HADOOP_HOME,/share/hadoop/mapreduce/*.jar

[hadoop@bigdatamaster conf]$ pwd
/home/hadoop/app/sqoop/server/conf
[hadoop@bigdatamaster conf]$ ll
total
-rw-r--r-- hadoop hadoop May catalina.policy
-rw-r--r-- hadoop hadoop Apr catalina.properties
-rw-r--r-- hadoop hadoop May context.xml
-rw-r--r-- hadoop hadoop May logging.properties
-rw-r--r-- hadoop hadoop Apr server.xml
-rw-r--r-- hadoop hadoop Apr sqoop_bootstrap.properties
-rw-r--r-- hadoop hadoop Apr sqoop.properties
-rw-r--r-- hadoop hadoop May tomcat-users.xml
-rw-r--r-- hadoop hadoop May web.xml
[hadoop@bigdatamaster conf]$ vim catalina.properties
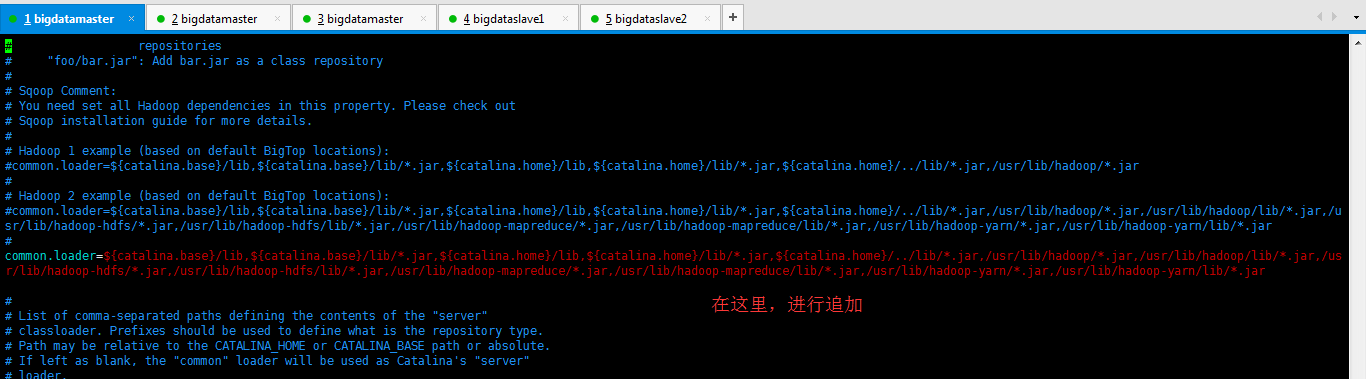

$HADOOP_HOME/share/hadoop/common/*.jar,$HADOOP_HOME/share/hadoop/common/lib/*.jar,$HADOOP_HOME/share/hadoop/yarn/*.jar,$HADOOP_HOME/share/hadoop/hdfs/*.jar,$HADOOP_HOME,/share/hadoop/mapreduce/*.jar
2、修改$SQOOP_HOME/server/conf/sqoop.properties文件org.apache.sqoop.submission.engine.mapreduce.configuration.directory属性,指向本机hadoop配置目录。
[hadoop@bigdatamaster conf]$ pwd
/home/hadoop/app/sqoop/server/conf
[hadoop@bigdatamaster conf]$ ll
total
-rw-r--r-- hadoop hadoop May catalina.policy
-rw-r--r-- hadoop hadoop May : catalina.properties
-rw-r--r-- hadoop hadoop May context.xml
-rw-r--r-- hadoop hadoop May logging.properties
-rw-r--r-- hadoop hadoop Apr server.xml
-rw-r--r-- hadoop hadoop Apr sqoop_bootstrap.properties
-rw-r--r-- hadoop hadoop Apr sqoop.properties
-rw-r--r-- hadoop hadoop May tomcat-users.xml
-rw-r--r-- hadoop hadoop May web.xml
[hadoop@bigdatamaster conf]$ vim sqoop.properties
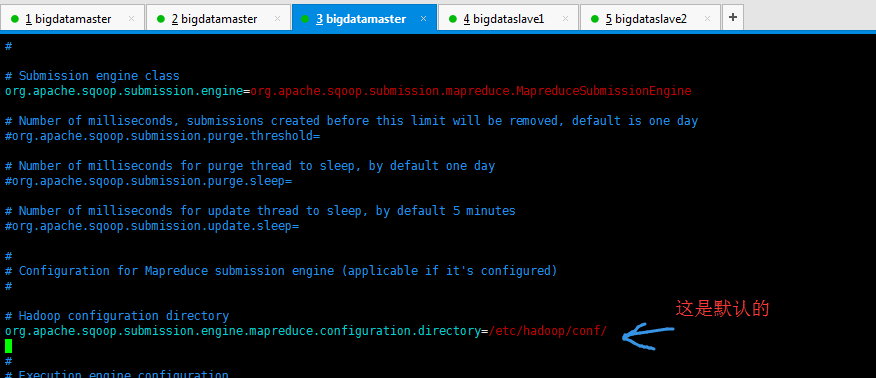
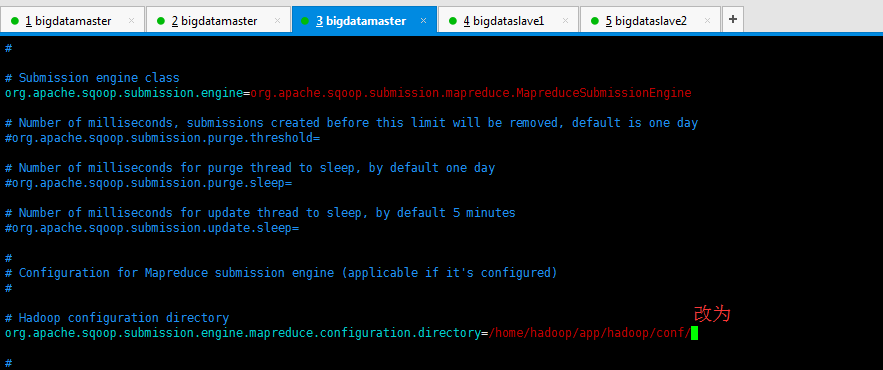
# Hadoop configuration directory
org.apache.sqoop.submission.engine.mapreduce.configuration.directory=/home/hadoop/app/hadoop/conf/
3、$SQOOP_HOME/server/conf/server.xml是Tomcat的配置文件,端口什么的可以在这个文件设置
这里,我暂时不设置。
4、复制mysql-connector-java-5.1.21.jar到$SQOOP_HOME/server/lib/下

[hadoop@bigdatamaster lib]$ pwd
/home/hadoop/app/sqoop2-1.99.-cdh5.5.4/server/lib
[hadoop@bigdatamaster lib]$ ls
annotations-api.jar catalina-ha.jar catalina-tribes.jar el-api.jar jasper.jar servlet-api.jar tomcat-coyote.jar tomcat-i18n-es.jar tomcat-i18n-ja.jar
catalina-ant.jar catalina.jar ecj-4.3..jar jasper-el.jar jsp-api.jar sqoop-tomcat-1.99.-cdh5.5.4.jar tomcat-dbcp.jar tomcat-i18n-fr.jar
[hadoop@bigdatamaster lib]$ rz [hadoop@bigdatamaster lib]$ ls
annotations-api.jar catalina.jar el-api.jar jsp-api.jar sqoop-tomcat-1.99.-cdh5.5.4.jar tomcat-i18n-es.jar
catalina-ant.jar catalina-tribes.jar jasper-el.jar mysql-connector-java-5.1..jar tomcat-coyote.jar tomcat-i18n-fr.jar
catalina-ha.jar ecj-4.3..jar jasper.jar servlet-api.jar tomcat-dbcp.jar tomcat-i18n-ja.jar
[hadoop@bigdatamaster lib]$
Sqoop2全部配置好之后,按照如下的顺序来
1、启动Sqoop2的server(我这里做个最简单的,在bigdatamaster上)。启动sqoop服务
$SQOOP_HOME/bin/sqoop.sh server start
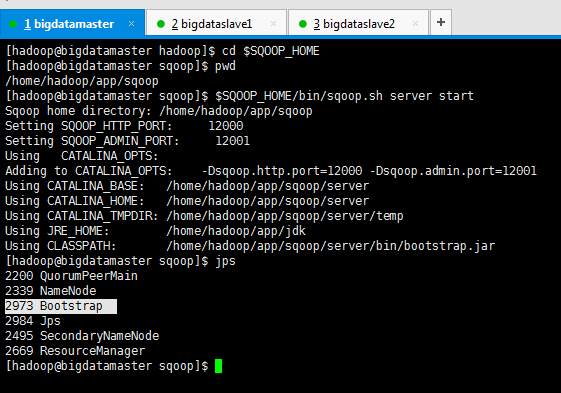
[hadoop@bigdatamaster hadoop]$ cd $SQOOP_HOME
[hadoop@bigdatamaster sqoop]$ pwd
/home/hadoop/app/sqoop
[hadoop@bigdatamaster sqoop]$ $SQOOP_HOME/bin/sqoop.sh server start
Sqoop home directory: /home/hadoop/app/sqoop
Setting SQOOP_HTTP_PORT:
Setting SQOOP_ADMIN_PORT:
Using CATALINA_OPTS:
Adding to CATALINA_OPTS: -Dsqoop.http.port= -Dsqoop.admin.port=
Using CATALINA_BASE: /home/hadoop/app/sqoop/server
Using CATALINA_HOME: /home/hadoop/app/sqoop/server
Using CATALINA_TMPDIR: /home/hadoop/app/sqoop/server/temp
Using JRE_HOME: /home/hadoop/app/jdk
Using CLASSPATH: /home/hadoop/app/sqoop/server/bin/bootstrap.jar
[hadoop@bigdatamaster sqoop]$ jps
QuorumPeerMain
NameNode
Bootstrap
Jps
SecondaryNameNode
ResourceManager
[hadoop@bigdatamaster sqoop]$
jsp命令看到Bootstrap进程。
2、启动Sqoop2的client(我这里做个最简单的,在bigdatamaster上),进入客户端交互模式。进入sqoop控制台
$SQOOP_HOME/bin/sqoop.sh client
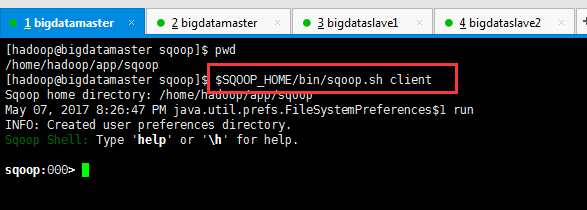
[hadoop@bigdatamaster sqoop]$ pwd
/home/hadoop/app/sqoop
[hadoop@bigdatamaster sqoop]$ $SQOOP_HOME/bin/sqoop.sh client
Sqoop home directory: /home/hadoop/app/sqoop
May , :: PM java.util.prefs.FileSystemPreferences$ run
INFO: Created user preferences directory.
Sqoop Shell: Type 'help' or '\h' for help. sqoop:>
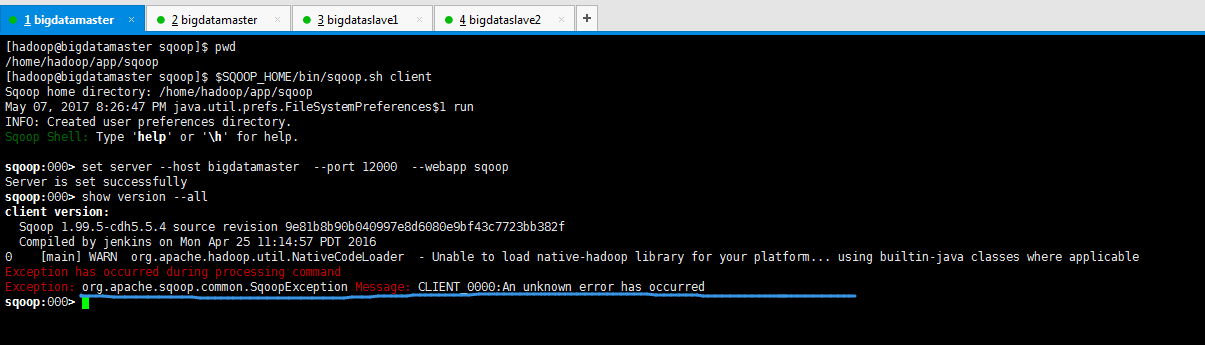
3、在Sqoop2的client连接Sqoop2的server 。 连接服务器
sqoop:> set server --host bigdatamaster --port --webapp sqoop
sqoop:000> set server --host localhost --port 12000 --webapp sqoop
sqoop:000> show version --all 当看到show version -all正确的显示 就说明了Sqoop2的client连接上了Sqoop2的服务器。
show version --all 显示服务器、客户端的版本信息,如果server显示错误,
重启一下 server./sqoop.sh server stop
[hadoop@bigdatamaster sqoop]$ pwd
/home/hadoop/app/sqoop
[hadoop@bigdatamaster sqoop]$ $SQOOP_HOME/bin/sqoop.sh client
Sqoop home directory: /home/hadoop/app/sqoop
May , :: PM java.util.prefs.FileSystemPreferences$ run
INFO: Created user preferences directory.
Sqoop Shell: Type 'help' or '\h' for help. sqoop:> set server --host bigdatamaster --port --webapp sqoop
Server is set successfully
sqoop:> show version --all
client version:
Sqoop 1.99.-cdh5.5.4 source revision 9e81b8b90b040997e8d6080e9bf43c7723bb382f
Compiled by jenkins on Mon Apr :: PDT
[main] WARN org.apache.hadoop.util.NativeCodeLoader - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Exception has occurred during processing command
Exception: org.apache.sqoop.common.SqoopException Message: CLIENT_0000:An unknown error has occurred
sqoop:>
sqoop:> show connector --all 查看连接器
sqoop:> show connection --all 查看连接
sqoop:> show connection --xid 查看id为1的连接
sqoop:> create connection --cid 创建id为1的连接
<pre name="code" class="java">Creating connection for connector with id
Please fill following values to create new connection object
Name: mysql --输入名称 Connection configuration JDBC Driver Class: com.mysql.jdbc.Driver --输入
JDBC Connection String: jdbc:mysql://bigdatamaster:3306/sqoop --输入
Username: root --输入
Password: ****** --输入
JDBC Connection Properties:
There are currently values in the map:
entry# Security related configuration options Max connections: --输入
New connection was successfully created with validation status FINE and persistent id
sqoop:> create job --xid --type import
Creating job for connection with id
Please fill following values to create new job object
Name: mysql_job Database configuration Schema name:
Table name: userinfo 要全量导出一张表,请填写表名,table name 和 table sql statement不能同时配置
Table SQL statement: 如果填写格式必须为 select * from userinfo where ${CONDITIONS}
Table column names:
Partition column name: id 使用哪个字段来填充过滤条件 userid
Nulls in partition column:
Boundary query: 如果选择sql方式,这里要写一个查询语句,返回值需为整形,sqoop运行job时,会自动填充${CONDITIONS} 这个占位符,如:select , from userinfo Output configuration Storage type:
: HDFS
Choose:
Output format:
: TEXT_FILE
: SEQUENCE_FILE
Choose:
Compression format:
: NONE
: DEFAULT
: DEFLATE
: GZIP
: BZIP2
: LZO
: LZ4
: SNAPPY
Choose:
Output directory: /home/hadoop/out Throttling resources Extractors:
Loaders:
New job was successfully created with validation status FINE and persistent id
sqoop:> start job --jid 启动
Submission details
Job ID:
Server URL: http://localhost:12000/sqoop/
<span style="font-family: Consolas, 'Courier New', Courier, mono, serif; line-height: 18px;">hadoop fs -ls /mysql/out </span>
更详细,请见
http://sqoop.apache.org/docs/1.99.5/Sqoop5MinutesDemo.html
sqoop2-1.99.5-cdh5.5.4.tar.gz的部署搭建的更多相关文章
- Apache版本hadoop-2.6.0.tar.gz平台下搭建Hue
不多说,直接上干货! http://archive.apache.org/dist/ http://www.cnblogs.com/smartloli/p/4527168.html http://ww ...
- ubuntu 16.04 jdk-8u201-linux-x64.tar.gz 安装部署
都是在普通用户加sudo代替root 1.sudo tar -zxvf jdk-8u201-linux-x64.tar.gz2.sudo chown make:make jdk1.8.0/3.sudo ...
- CDH版本大数据集群下搭建Hue(hadoop-2.6.0-cdh5.5.4.gz + hue-3.9.0-cdh5.5.4.tar.gz)(博主推荐)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- MySQL数据库安装(CentOS操作系统/tar.gz方式)
1. 上传Mysql安装包“mysql-5.5.40-linux2.6-x86_64.tar.gz”到部署机,位置任意: 2. 将Mysql安装包解压到其所在目录,命令如下: -linux2.-x86 ...
- hadoop-2.6.0.tar.gz + spark-1.5.2-bin-hadoop2.6.tgz 的集群搭建(3节点和5节点皆适用)
本人呕心沥血所写,经过好一段时间反复锤炼和整理修改.感谢所参考的博友们!同时,欢迎前来查阅赏脸的博友们收藏和转载,附上本人的链接.http://www.cnblogs.com/zlslch/p/584 ...
- 详细讲解Hadoop源码阅读工程(以hadoop-2.6.0-src.tar.gz和hadoop-2.6.0-cdh5.4.5-src.tar.gz为代表)
首先,说的是,本人到现在为止,已经玩过. 对于,这样的软件,博友,可以去看我博客的相关博文.在此,不一一赘述! Eclipse *版本 Eclipse *下载 Jd ...
- CDH版本大数据集群下搭建Avro(hadoop-2.6.0-cdh5.5.4.gz + avro-1.7.6-cdh5.5.4.tar.gz的搭建)
下载地址 http://archive.cloudera.com/cdh5/cdh/5/avro-1.7.6-cdh5.5.4.tar.gz
- centos7 安装Hadoop-2.6.0-cdh5.16.1.tar.gz
准备Hadoop-2.6.0-cdh5.16.1.tar.gz 下载网址 http://archive.cloudera.com/cdh5/cdh/5/Hadoop-2.6.0-cdh5.16.1.t ...
- linux commands - 一次性解压多个tar.gz文件
tar -zxvf list所有tar.gz文件,然后利用xargs将其作为参数传给tar命令.-n 1表示每次传一个参数. xargs: https://www.cnblogs.com/wangqi ...
随机推荐
- linux系统输入法设置
首先是要安装了中文输入法,下面以搜狗为例. 2 从system settings 进入language support ,在keyboard input method system 中是看不到自己安装 ...
- iOS开发:iOS中图片与视频一次性多选 - v2m
一.使用系统的Assets Library Framework这个是用来访问Photos程序中的图片和视频的库.其中几个类解释如下 ALAsset ->包含一个图片或视频的各种信息 ALAsse ...
- PyQt4工具栏
工具栏 菜单对程序中的所有命令进行分组防治,而工具栏则提供了快速执行最常用命令的方法. #!/usr/bin/python # -*- coding:utf-8 -*- import sys from ...
- Sencha Cmd创建Ext JS示例项目
Sencha提供了免费的Cmd工具,可以用来创建Ext JS项目并提供了一些便利的功能. Sencha也在官方文档中提供了一个示例来演示如何创建一个Sample Login App. 本文就介绍一下这 ...
- BNU4204:动物PK
稀奇稀奇真稀奇,动物园摆出了擂台赛.小动物们纷纷上台比试,谁能获得最后的冠军呢? 动物园长发现小动物们打擂只与自身的三项属性有关:血量,攻击力和防御力.此外,小动物在赛前都为自己准备了一系列的攻击计划 ...
- c++ 重载、重写、重定义(隐藏)
1.重载overload:函数名相同,参数列表不同. 重载只是在类的内部存在,或者同为全局范围.(同名,同参函数返回值不同时,会编译出错.因为系统无法知晓你到底要调用哪一个.) 2.重写overr ...
- vscode中的vue文件中emmet进行tab键不起作用
文件--首选项---设置 搜索: emmet.includeLanguages在右边修改 "emmet.triggerExpansionOnTab": true, "em ...
- SPOJ - DQUERY
题目链接:传送门 题目大意:一个容量 n 的数组, m次询问,每次询问 [x,y]内不同数的个数 题目思路:主席树(注意不是权值线段树而是位置线段树) 也就是按一般线段树的逻辑来写只是用主席树实现而已 ...
- 二、微信小游戏开发 多线程Worker
微信多线程Worker教程 微信多线程Worker API 一.创建Worker,并和当前线程通讯 多线程worker只能创建1个.能和当前线程互传数据. 创建worker 在微信开发者工具中,在当前 ...
- ehcache加载配置文件ehcache.xml的源码
package net.sf.ehcache.config; public final class ConfigurationFactory { public static Configuration ...