RPN网络
Region Proposal Network
RPN的实现方式:在conv5-3的卷积feature map上用一个n*n的sliding window(论文中n=3)生成一个长度为256(ZF网络)或512(对应于VGG网络)维长度的全连接特征。然后再这个256维或512维的特征后产生两个分支的全连接层:
- 1. reg-layer:用于预测proposal的中心锚点对应的proposal的坐标x,y和宽高w,h;
- 2. cls-layer:用于判定该proposal是前景还是背景。sliding window的处理方式保证reg-layer和cls-layer关联了conv5-3的全部特征空间。事实上,作者用全连接层实现方式介绍RPN层实现容易帮助我们理解这一过程,但在实现时,作者选用了卷积层实现全连接层的功能。
- 3. 个人理解:全连接层本来就是特殊的卷积层,如果产生256或512维的fc特征,事实上可以用Num_out=256或512,kernel_size=33,stride=1的卷积层实现conv5-3到第一个全连接特征的映射。然后再用两个Num_out分别为 29=18 和 49=36,kernel_size=11,stride=1的卷积层实现上一层特征到两个分支cls层和reg层的特征映射。
- 4. attention:这里29中的2指cls层的分类结果包含前后背景两类,49的4表示一个Proposal的中心点坐标x,y和宽高w,h四个参数。采用卷积的方式实现全连接处理并不会减少参数的数量,但是使得输入的图像的尺寸可以更加灵活。在RPN网络中,需要重点理解其中的anchors概念,Loss functions计算方式和RPN层训练数据生成的具体细节。
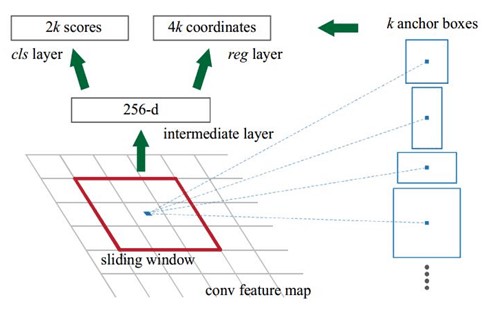
Anchors: 锚点,位于之前提到的nn的sliding window的中心处。对于一个sliding window,我们可以同时预测多个proposal,假定有k个proposal,即k个reference boxes,每一个reference box又可以用一个scale,一个aspect_ratio和sliding window中的锚点唯一确定。所以,后面说一个anchor,就理解成一个anchor box 或 一个reference box。论文中定义k=9,即3种scales和3种aspect_ratio确定出当前sliding window 位置处对应的9个reference boxes,4k个reg-layer的输出和2k个cls-layer的score输出。对于一幅WH的feature map,对应WHk个锚点,所有的锚点都具有尺度不变性。
Loss functions:
在计算Loss值之前,作者设置了anchors的标定方法。正样本标定规则:
1) 如果Anchor对应的refrence box 与 ground truth 的 IOU值最大,标记为正样本;
2)如果Anchor对应的refrence box与ground truth的IoU>0.7,标定为正样本。事实上,采用第2个规则基本上可以找到足够的正样本,但是对于一些极端情况,例如所有的Anchor对应的reference box与groud truth的IoU不大于0.7,可以采用第一种规则生成.
3)负样本标定规则:如果Anchor对应的reference box 与 ground truth的IoU<0.3,标记为负样本。
4)剩下的既不是正样本也不是负样本,不用于最终训练。
5)训练RPN的Loss是有classification loss(即softmax loss)和 regression loss(即L1 loss)按一定比重组成的。
计算softmax loss需要的是anchors对应的ground truth 标定结果和预测结果,计算regression loss需要三组信息:
i. 预测框,即RPN网络预测出的proposal的中心位置坐标x,y和宽高w,h;
ii. 锚点reference box:
之前的9个锚点对应9个不同scale和aspect_ratio的reference boxes,每一个reference boxes都有一个中心点位置坐标x_a,y_a和宽高w_a,h_a;
iii. ground truth:标定的框也对应一个中心点位置坐标x,y和宽高w,h.因此计算regression loss和总Loss方式如下:
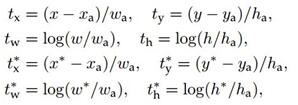
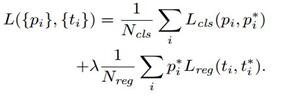
- RPN训练设置:
(1)在训练RPN时,一个Mini-batch是由一幅图像中任意选取的256个proposal组成的,其中正负样本的比例为1:1.
(2)如果正样本不足128,则多用一些负样本以满足有256个Proposal可以用于训练,反之亦然.
(3)训练RPN时,与VGG共有的层参数可以直接拷贝经ImageNet训练得到的模型中的参数;剩下没有的层参数用标准差=0.01的高斯分布初始化.
RPN网络的更多相关文章
- Caffe RPN:把RPN网络layer添加到caffe基础结构中
在测试MIT Scene Parsing Benchmark (SceneParse150)使用FCN网络时候,遇到Caffe错误. 遇到错误:不可识别的网络层crop 网络层 CreatorRegi ...
- r-cnn学习(六):RPN及AnchorTargetLayer学习
RPN网络是faster与fast的主要区别,输入特征图,输出region proposals以及相应的分数. # ------------------------------------------ ...
- 目标检测网络之 YOLOv2
YOLOv1基本思想 YOLO将输入图像分成SxS个格子,若某个物体 Ground truth 的中心位置的坐标落入到某个格子,那么这个格子就负责检测出这个物体. 每个格子预测B个bounding b ...
- Faster R-CNN 的 RPN 是啥子?
 Faster R-CNN,由两个模块组成: 第一个模块是深度全卷积网络 RPN,用于 region proposal; 第二个模块是Fast R-CNN检测器,它使用了RPN产生的region p ...
- 目标检测网络之 YOLOv3
本文逐步介绍YOLO v1~v3的设计历程. YOLOv1基本思想 YOLO将输入图像分成SxS个格子,若某个物体 Ground truth 的中心位置的坐标落入到某个格子,那么这个格子就负责检测出这 ...
- 第三节,目标检测---R-CNN网络系列
1.目标检测 检测图片中所有物体的 类别标签 位置(最小外接矩形/Bounding box) 区域卷积神经网络R-CNN 模块进化史 2.区域卷积神经网络R-CNN Region proposals+ ...
- 『计算机视觉』Mask-RCNN_推断网络其四:FPN和ROIAlign的耦合
一.模块概述 上节的最后,我们进行了如下操作获取了有限的proposal, # [IMAGES_PER_GPU, num_rois, (y1, x1, y2, x2)] # IMAGES_PER_GP ...
- 『计算机视觉』Mask-RCNN_推断网络其二:基于ReNet101的FPN共享网络暨TensorFlow和Keras交互简介
零.参考资料 有关FPN的介绍见『计算机视觉』FPN特征金字塔网络. 网络构架部分代码见Mask_RCNN/mrcnn/model.py中class MaskRCNN的build方法的"in ...
- 对faster rcnn 中rpn层的理解
1.介绍 图为faster rcnn的rpn层,接自conv5-3 图为faster rcnn 论文中关于RPN层的结构示意图 2 关于anchor: 一般是在最末层的 feature map 上再用 ...
随机推荐
- PHP json_decode 无法解析特殊问号字符
在通过别人接口请求信息的时候,偶尔会遇到由于部分字符,如以下情况,则通过json_decode是会返回null的 但是这种情况通常不是由于整体编码的问题,因为在解析的时候就是以utf-8的编码解析的 ...
- Linux 权限修改
chown -R 用户名:组名 文件夹名chown -R xu:hadoop hadoop 将hadoop目录(以及其下的所有子目录/文件)的属主用户设为xu, xu 的组名为group
- 在express项目中使用formidable & multiparty实现文件上传
安装 formidable,multiparty 模块 npm install formidable,multiparty –save -d 表单上传 <form id="addFor ...
- SVN目录权限配置
1.如果要使用SVN,需要有一个项目的保存目录,例如把该目录设为“C:\MyPro”文件夹 2.把该目录发布为SVN项目目录,则需要通过以下命令行 svnadmin create c:\mypro ...
- 高级类特性----抽象类(abstract class)
抽象类(abstract class) 随着继承层次中一个个新子类的定义,类变得越来越具体,而父类则更一般,更通用.类的设计应该保证父类和子类能够共享特征.有时将一个父类设计得非常抽象,以至于它没有具 ...
- 在Extjs中动态增加控件
Ext.onReady(function () { Ext.QuickTips.init(); Ext.form.Field.prototype.msgTarget = 'side'; var aut ...
- swift - 利用UIDatePicker实现定时器的效果
效果图如下: 可以通过UIDatePicker调整倒计时的时间,然后点击UIButton开始倒计时,使用NSTimer进行倒计时的时间展示,我是声明了一个label也进行了标记, 然后点击按钮开始倒计 ...
- vue 组件库
iView https://www.iviewui.com/ Radon UI https://luojilab.github.io/radon-ui/#!/ Element http://eleme ...
- mac 安装mysql 修改密码
我草!!! 上网查资料,安装mysql,一大推废话,简直就是他妈的瞎扯淡,真是能他妈的瞎编,草! 为了不让后面的同学看到那些狗屁不通的资料,我把自己安装mysql的步骤,以及修改mysql密码的方法梳 ...
- Win7下使用Putty代替超级终端通过COM串口连接开发板方法
1.如果电脑(笔记本)没有串口接口,则需要使用一个 USB-Serial 转换线,这里使用 prolific usb-serial USB--串口转换线,首先需要在win7上安装对应的 USB--串口 ...