浅析Postgres中的并发控制(Concurrency Control)与事务特性(下)
上文我们讨论了PostgreSQL的MVCC相关的基础知识以及实现机制。关于PostgreSQL中的MVCC,我们只讲了元组可见性的问题,还剩下两个问题没讲。一个是"Lost Update"问题,另一个是PostgreSQL中的序列化快照隔离机制(SSI,Serializable Snapshot Isolation)。今天我们就来继续讨论。
3.2 Lost Update
所谓"Lost Update"就是写写冲突。当两个并发事务同时更新同一条数据时发生。"Lost Update"必须在REPEATABLE READ 和 SERIALIZABLE 隔离级别上被避免,即拒绝并发地更新同一条数据。下面我们看看在PostgreSQL上如何处理"Lost Update"
有关PostgreSQL的UPDATE操作,我们可以看看ExecUpdate()这个函数。然而今天我们不讲具体的函数,我们形而上一点。只从理论出发。我们只讨论下UPDATE执行时的情形,这意味着,我们不讨论什么触发器啊,查询重写这些杂七杂八的,只看最"干净"的UPDATE操作。而且,我们讨论的是两个并发事务的UPDATE操作。
请看下图,下图显示了两个并发事务中UPDATE同一个tuple时的处理。
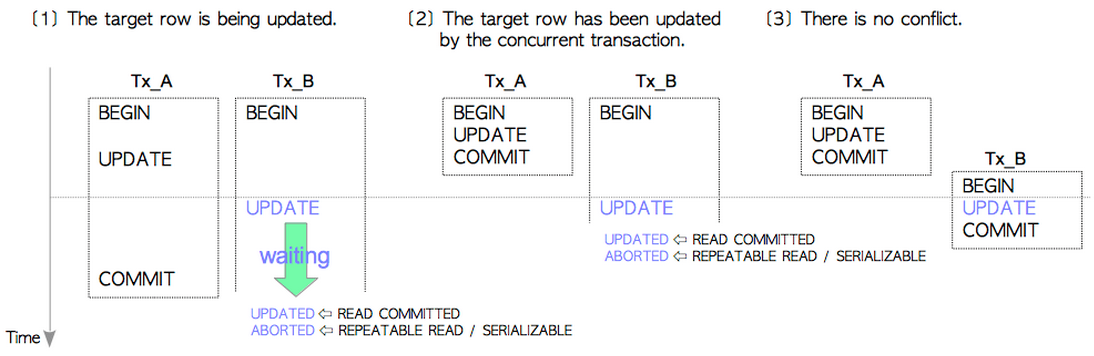
- [1]目标tuple处于正在更新的状态
我们看到Tx_A和Tx_B在并发执行,Tx_A先更新了tuple,这时Tx_B准备去更新tuple,发现Tx_A更新了tuple,但是还没有提交。于是,Tx_B处于等待状态,等待Tx_A结束(commit或者abort)。
当Tx_A提交时,Tx_B解除等待状态,准备更新tuple,这时分两个情况:如果Tx_B的隔离级别是READ COMMITTED,那么OK,Tx_B进行UPDATE(可以看出,此时发生了Lost Update)。如果Tx_B的隔离级别是REPEATABLE READ或者是SERIALIZABLE,那么Tx_B会立即被abort,放弃更新。从而避免了Lost Update的发生。
当Tx_A和Tx_B的隔离级别都为READ COMMITTED时的例子:
| Tx_A | Tx_B |
|---|---|
| postgres=# START TRANSACTION ISOLATION LEVEL READ COMMITTED ; START TRANSACTION postgres=# update test set b = b+1 where a =1; UPDATE 1 postgres=# commit; COMMIT |
postgres=# START TRANSACTION ISOLATION LEVEL READ COMMITTED; START TRANSACTION postgres=# update test set b = b+1; ↓ ↓this transaction is being blocked ↓ UPDATE 1 |
当Tx_A的隔离级别为READ COMMITTED,Tx_B的隔离级别为REPEATABLE READ时的例子:
| Tx_A | Tx_B |
|---|---|
| postgres=# START TRANSACTION ISOLATION LEVEL READ COMMITTED ; START TRANSACTION postgres=# update test set b = b+1 where a =1; UPDATE 1 postgres=# commit; COMMIT |
postgres=# START TRANSACTION ISOLATION LEVEL REPEATABLE READ; START TRANSACTION postgres=# update test set b = b+1; ↓ ↓this transaction is being blocked ↓ ERROR:couldn't serialize access due to concurrent update |
- [2]目标tuple已经被并发的事务更新
我们看到Tx_A和Tx_B在并发执行,Tx_A先更新了tuple并且已经commit,Tx_B再去更新tuple时发现它已经被更新过了并且已经提交。如果Tx_B的隔离级别是READ COMMITTED,根据我们前面说的,,Tx_B在执行UPDATE前会重新获取snapshot,发现Tx_A的这次更新对于Tx_B是可见的,因此Tx_B继续更新Tx_A更新过得元组(Lost Update)。而如果Tx_B的隔离级别是REPEATABLE READ或者是SERIALIZABLE,那么显然我们会终止当前事务来避免Lost Update。
当Tx_A的隔离级别为READ COMMITTED,Tx_B的隔离级别为REPEATABLE READ时的例子:
| Tx_A | Tx_B |
|---|---|
| postgres=# START TRANSACTION ISOLATION LEVEL READ COMMITTED ; START TRANSACTION postgres=# update test set b = b+1 where a =1; UPDATE 1 postgres=# commit; COMMIT |
postgres=# START TRANSACTION ISOLATION LEVEL REPEATABLE READ; START TRANSACTION postgres=# select * from test ; a b ---+--- 1 5 (1 row) postgres=# update test set b = b+1 ERROR: could not serialize access due to concurrent update |
- [3]更新无冲突
这个很显然,没有冲突就没有伤害。Tx_A和Tx_B照常更新,不会有Lost Update。
从上面我们也可以看出,在使用SI(Snapshot Isolation)机制时,两个并发事务同时更新一条记录时,先更新的那一方获得更新的优先权。但是在下面提到的SSI机制中会有所不同,先提交的事务获得更新的优先权。
3.3 SSI(Serializable Snapshot Isolation)
SSI,可序列化快照隔离,是PostgreSQL在9.1之后,为了实现真正的SERIALIZABLE(可序列化)隔离级别而引入的。
对于SERIALIZABLE隔离级别,官方介绍如下:
可序列化隔离级别提供了最严格的事务隔离。这个级别为所有已提交事务模拟序列事务执行;就好像事务被按照序列一个接着另一个被执行,而不是并行地被执行。但是,和可重复读级别相似,使用这个级别的应用必须准备好因为序列化失败而重试事务。事实上,这个隔离级别完全像可重复读一样地工作,除了它会监视一些条件,这些条件可能导致一个可序列化事务的并发集合的执行产生的行为与这些事务所有可能的序列化(一次一个)执行不一致。这种监控不会引入超出可重复读之外的阻塞,但是监控会产生一些负荷,并且对那些可能导致序列化异常的条件的检测将触发一次序列化失败。
讲的比较繁琐,我的理解是:
1.只针对隔离级别为SERIALIZABLE的事务;
2.并发的SERIALIZABLE事务与按某一个顺序单独的一个一个执行的结果相同。
条件1很好理解,系统只判断并发的SERIALIZABLE的事务之间的冲突;
条件2我的理解就是并发的SERIALIZABLE的事务不能同时修改和读取同一个数据,否则由并发执行和先后按序列执行就会不一致。
但是这个不能同时修改和读取同一个数据要限制在多大的粒度呢?
我们分情况讨论下。
- [1] 读写同一条数据
似乎没啥问题嘛,根据前面的论述,这里的一致性在REPEATABLE READ阶段就保证了,不会有问题。
以此类推,我们同时读写2,3,4....n条数据,没问题。
- [2]读写闭环
啥是读写闭环?这我我造的概念,类似于操作系统中的死锁,即事务Tx_A读tuple1,更新tuple2,而Tx_B恰恰相反,读tuple2, 更新tuple1.
我们假设事务开始前的tuple1,tuple2为tuple1_1,tuple2_1,Tx_A和Tx_B更新后的tuple1,tuple2为tuple1_2,tuple2_2。
这样在并发下:
Tx_A读到的tuple1是tuple1_1,tuple2是tuple2_1。
同理,Tx_B读到的tuple1是tuple1_1,tuple2是tuple2_1。
而如果我们以Tx_A,Tx_B的顺序串行执行时,结果为:
Tx_A读到的tuple1是tuple1_1,tuple2是tuple2_1。
Tx_B读到的tuple1是tuple1_2(被Tx_A更新了),tuple2是tuple2_1。
反之,而如果我们以Tx_B,Tx_A的顺序串行执行时,结果为:
Tx_B读到的tuple1是tuple1_1,tuple2是tuple2_1。
Tx_A读到的tuple1是tuple1_1,tuple2是tuple2_2(被Tx_B更新了)。
可以看出,这三个结果都不一样,不满足条件2,即并发的Tx_A和Tx_B不能被模拟为Tx_A和Tx_B的任意一个序列执行,导致序列化失败。
其实我上面提到的读写闭环,更正式的说法是:序列化异常。上面说的那么多,其实下面两张图即可解释。
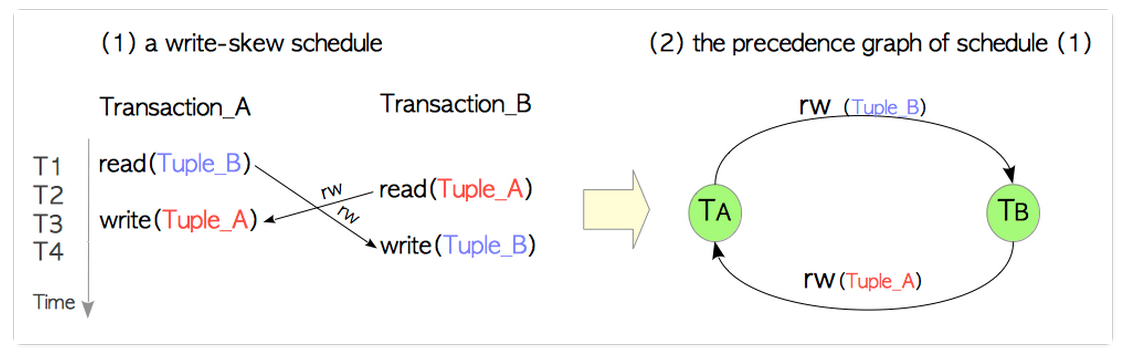
关于这个*-conflicts我们遇到好几个了。我们先总结下:
wr-conflicts (Dirty Reads)
ww-conflicts (Lost Updates)
rw-conflicts (serialization anomaly)
下面说的SSI机制,就是用来解决rw-conflicts的。
好的,下面就开始说怎么检测这个序列化异常问题,也就是说,我们要开始了解下SSI机制了。
在PostgreSQL中,使用以下方法来实现SSI:
利用SIREAD LOCK(谓词锁)记录每一个事务访问的对象(tuple、page和relation);
在事务写堆表或者索引元组时利用SIREAD LOCK监测是否存在冲突;
如果发现到冲突(即序列化异常),abort该事务。
从上面可以看出,SIREAD LOCK是一个很重要的概念。解释了这个SIREAD LOCK,我们也就基本上理解了SSI。
所谓的SIREAD LOCK,在PostgreSQL内部被称为谓词锁。他的形式如下:
SIREAD LOCK := { tuple|page|relation, {txid [, ...]} }
也就是说,一个谓词锁分为两个部分:前一部分记录被"锁定"的对象(tuple、page和relation),后一部分记录同时访问了该对象的事务的virtual txid(有关它和txid的区别,这里就不做多介绍了)。
SIREAD LOCK的实现在函数CheckForSerializableConflictOut中。该函数在隔离级别为SERIALIZABLE的事务中发生作用,记录该事务中所有DML语句所造成的影响。
例如,如果txid为100的事务读取了tuple_1,则创建一个SIREAD LOCK为{tuple_1, {100}}。此时,如果另一个txid为101的事务也读取了tuple_1,则该SIREAD LOCK升级为{tuple_1, {100,101}}。需要注意的是如果在DML语句中访问了索引,那么索引中的元组也会被检测,创建对应的SIREAD LOCK。
SIREAD LOCK的粒度分为三级:tuple|page|relation。如果同一个page中的所有tuple都被创建了SIREAD LOCK,那么直接创建page级别的SIREAD LOCK,同时释放该page下的所有tuple级别的SIREAD LOCK。同理,如果一个relation的所有page都被创建了SIREAD LOCK,那么直接创建relation级别的SIREAD LOCK,同时释放该relation下的所有page级别的SIREAD LOCK。
当我们执行SQL语句使用的是sequential scan时,会直接创建一个relation 级别的SIREAD LOCK,而使用的是index scan时,只会对heap tuple和index page创建SIREAD LOCK。
同时,我还是要说明的是,对于index的处理时,SIREAD LOCK的最小粒度是page,也就是说你即使只访问了index中的一个index tuple,该index tuple所在的整个page都被加上了SIREAD LOCK。这个特性常常会导致意想不到的序列化异常,我们可以在后面的例子中看到。
有了SIREAD LOCK的概念,我们现在使用它来检测rw-conflicts。
所谓rw-conflicts,简单地说,就是有一个SIREAD LOCK,还有分别read和write这个SIREAD LOCK中的对象的两个并发的Serializable事务。
这个时候,另外一个函数闪亮登场:CheckForSerializableConflictIn()。每当隔离级别为Serializable事务中执行INSERT/UPDATE/DELETE语句时,则调用该函数判断是否存在rw-conflicts。
例如,当txid为100的事务读取了tuple_1,创建了SIREAD LOCK : {tuple_1, {100}}。此时,txid为101的事务更新tuple_1。此时调用CheckForSerializableConflictIn()发现存在这样一个状态: {r=100, w=101, {Tuple_1}}。显然,检测出这是一个rw-conflicts。
下面是举例时间。
首先,我们有这样一个表:
testdb=# CREATE TABLE tbl (id INT primary key, flag bool DEFAULT false);
testdb=# INSERT INTO tbl (id) SELECT generate_series(1,2000);
testdb=# ANALYZE tbl;
并发执行的Serializable事务像下面那样执行:

假设所有的SQL语句都走的index scan。这样,当SQL语句执行时,不仅要读取对应的heap tuple,还要读取heap tuple 对应的index tuple。如下图:
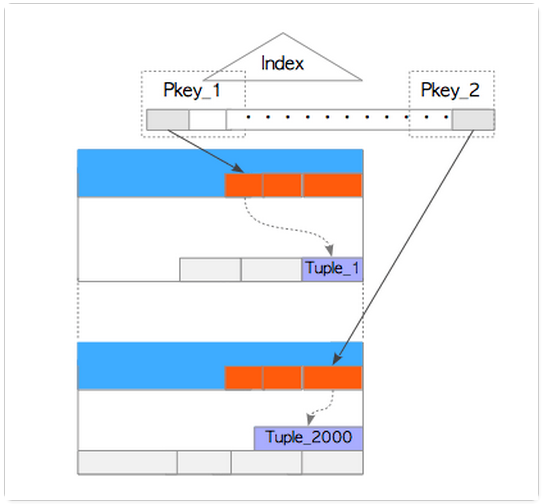
执行状态如下:
T1: Tx_A执行SELECT语句,该语句读取了heap tuple(Tuple_2000)和index page(Pkey2);
T2: Tx_B执行SELECT语句,该语句读取了heap tuple(Tuple_1)和index page(Pkey1);
T3: Tx_A执行UPDATE语句,该语句更新了Tuple_1;
T4: Tx_B执行UPDATE语句,该语句更新了Tuple_2000;
T5: Tx_A commit;
T6: Tx_B commit; 由于序列化异常,commit失败,状态为abort。
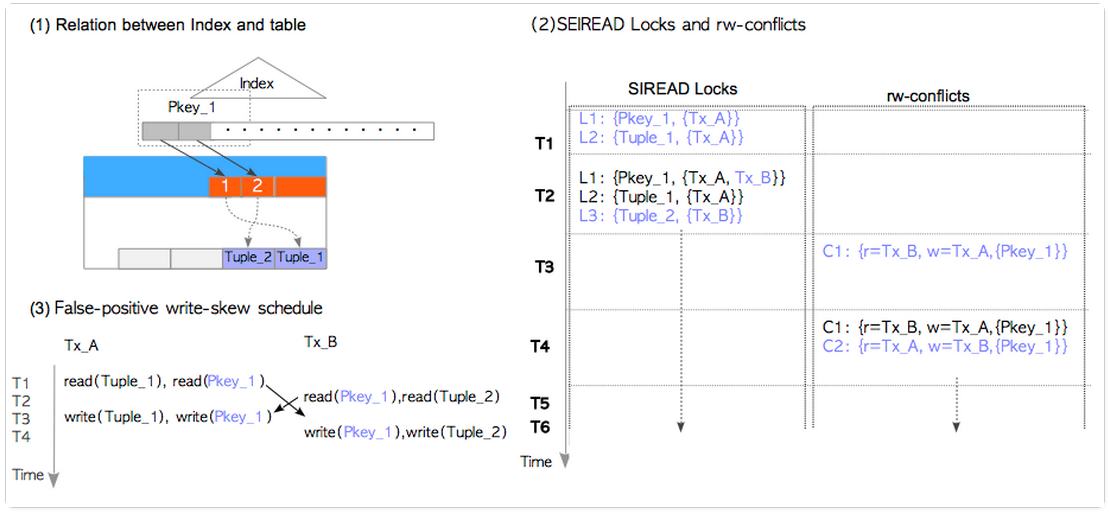
这时我们来看一下SIREAD LOCK的情况。

T1: Tx_A执行SELECT语句,调用CheckForSerializableConflictOut()创建了SIREAD LOCK:L1={Pkey_2,{Tx_A}} 和 L2={Tuple_2000,{Tx_A}};
T2: Tx_B执行SELECT语句,调用CheckForSerializableConflictOut创建了SIREAD LOCK:L3={Pkey_1,{Tx_B}} 和 L4={Tuple_1,{Tx_B}};
T3: Tx_A执行UPDATE语句,调用CheckForSerializableConflictIn(),发现并创建了rw-conflict :C1={r=Tx_B, w=Tx_A,{Pkey_1,Tuple_1}}。这很显然,因为Tx_B和TX_A分别read和write这两个object。
T4: Tx_A执行UPDATE语句,调用CheckForSerializableConflictIn(),发现并创建了rw-conflict :C1={r=Tx_A, w=Tx_B,{Pkey_2,Tuple_2000}}。到这里,我们发现C1和C2构成了precedence graph中的一个环。因此,Tx_A和Tx_B这两个事务都进入了non-serializable状态。但是由于Tx_A和Tx_B都未commit,因此CheckForSerializableConflictIn()并不会abort Tx_B(为什么不abort Tx_A?因此PostgreSQL的SSI机制中采用的是first-committer-win,即发生冲突后,先提交的事务保留,后提交的事务abort。)
T5: Tx_A commit;调用PreCommit_CheckForSerializationFailure()函数。该函数也会检测是否存在序列化异常。显然此时Tx_A和Tx_B处于序列化冲突之中,而由于发现Tx_B仍然在执行中,所以,允许Tx_A commit。
T6: Tx_B commit; 由于序列化异常,且和Tx_B存在序列化冲突的Tx_A已经被提交。因此commit失败,状态为abort。
更多更复杂的例子,可以参考这里.
前面在讨论SIREAD LOCK时,我们谈到对于index的处理时,SIREAD LOCK的最小粒度是page。这个特性会导致意想不到的序列化异常。更专业的说法是"False-Positive Serialization Anomalies"。简而言之实际上并没有发生序列化异常,但是我们的SSI机制不完善,产生了误报。
下面我们来举例说明。

对于上图,如果SQL语句走的是sequential scan,情形如下:

如果是index scan呢?还是有可能出现误报:
这篇就是这样。依然还是有很多问题没有讲清楚。留待下次再说吧(拖延症晚期)。
浅析Postgres中的并发控制(Concurrency Control)与事务特性(下)的更多相关文章
- 浅析Postgres中的并发控制(Concurrency Control)与事务特性(上)
转载:https://www.cnblogs.com/flying-tiger/p/9567213.html#4121483#undefined PostgreSQL为开发者提供了一组丰富的工具来管理 ...
- 浅析Postgres中的并发控制(Concurrency Control)与事务特性(上)(转)
这篇博客将MVCC讲的很透彻,以前自己懂了,很难给别人讲出来,但是这篇文章给的例子就让人很容易的复述出来,因此想记录一下,转载给更多的人 转自:https://www.cnblogs.com/flyi ...
- postgres中的中文分词zhparser
postgres中的中文分词zhparser postgres中的中文分词方法 基本查了下网络,postgres的中文分词大概有两种方法: Bamboo zhparser 其中的Bamboo安装和使用 ...
- 数据访问模式:数据并发控制(Data Concurrency Control)
1.数据并发控制(Data Concurrency Control)简介 数据并发控制(Data Concurrency Control)是用来处理在同一时刻对被持久化的业务对象进行多次修改的系统.当 ...
- Optimistic Concurrency VS. Pessimistic Concurrency Control
原创地址:http://www.cnblogs.com/jfzhu/p/4009918.html 转载请注明出处 (一)为什么需要并发控制机制 并发控制机制是为了防止多个用户同时更改同一条数据,也 ...
- [转]NHibernate之旅(7):初探NHibernate中的并发控制
本节内容 什么是并发控制? 悲观并发控制(Pessimistic Concurrency) 乐观并发控制(Optimistic Concurrency) NHibernate支持乐观并发控制 实例分析 ...
- 浅析JDK中ServiceLoader的源码
前提 紧接着上一篇<通过源码浅析JDK中的资源加载>,ServiceLoader是SPI(Service Provider Interface)中的服务类加载的核心类,也就是,这篇文章先介 ...
- MVCC(Multi-Version Concurrency Control)多版本并发控制机
MVCC(Multi-Version Concurrency Control)是一种多版本并发控制机制.
- NHibernate之旅(7):初探NHibernate中的并发控制
本节内容 什么是并发控制? 悲观并发控制(Pessimistic Concurrency) 乐观并发控制(Optimistic Concurrency) NHibernate支持乐观并发控制 实例分析 ...
随机推荐
- 关于html与body的高度问题
转自https://blog.csdn.net/javaloveiphone/article/details/51098972 一.html,body{height:100%} 今天看到一个CSS样式 ...
- SNAT和DNAT的区别
SNAT: Source Network Address Translation,是修改网络包源ip地址的.DNAT: Destination Network Address Translation, ...
- Multithreading in C
Multithreading in C, POSIX(可移植操作系统接口Portable Operating System Interface X ) style Multithreading - A ...
- URL Scheme
[URL Scheme] 可以通过info.plist注册url types来实现程序自定义的协议,以供外部程序调起. NSURL *myURL = [NSURL URLWithString:@&qu ...
- web api control注册及重写DefaultHttpControllerSelector、ApiControllerActionSelector、ApiControllerActionInvoker(转)
出处:http://www.cnblogs.com/kingCpp/p/4651154.html namespace EWorkpal.WebApi { public class HttpNotFou ...
- cxf的一些使用说明
/** * Licensed to the Apache Software Foundation (ASF) under one * or more contributor license agree ...
- JQuery中button提交表单报TypeError: elem[type] is not a function jquery
错误: TypeError: elem[type] is not a function jquery 解决: 出现这种现象的原因是,提交的表单中,有标签的name,有以submit命名的 name中不 ...
- Hadoop中Writable类之二
1.ASCII.Unicode.UFT-8 在看Text类型的时候,里面出现了上面三种编码,先看看这三种编码: ASCII是基于拉丁字母的一套电脑编码系统.它主要用于显示现代英语和其他西欧语言.它是现 ...
- idea jvm 优化
修改对应配置文件 64位的是idea64.exe.vmoptions -Xms2048m -Xmx2048m -Xmn1024m -XX:PermSize=512m -XX:MaxPermSize=5 ...
- 作业二:注册软件github
注册Github