为什么要重写hashcode方法和equals方法
我们可能经常听到说重写equals方法必须重写hashcode方法,这是为什么呢?java中所有的类都是Object的子类,直接上object源码
/*
* Copyright (c) 1994, 2012, Oracle and/or its affiliates. All rights reserved.
* ORACLE PROPRIETARY/CONFIDENTIAL. Use is subject to license terms.
*
*/ package java.lang; /**
* Class {@code Object} is the root of the class hierarchy.
* Every class has {@code Object} as a superclass. All objects,
* including arrays, implement the methods of this class.
*
* @author unascribed
* @see java.lang.Class
* @since JDK1.0
*/
public class Object { private static native void registerNatives();
static {
registerNatives();
}
public final native Class<?> getClass(); public native int hashCode(); public boolean equals(Object obj) {
return (this == obj);
} protected native Object clone() throws CloneNotSupportedException; public String toString() {
return getClass().getName() + "@" + Integer.toHexString(hashCode());
} public final native void notify(); public final native void notifyAll(); public final native void wait(long timeout) throws InterruptedException; public final void wait(long timeout, int nanos) throws InterruptedException {
if (timeout < 0) {
throw new IllegalArgumentException("timeout value is negative");
} if (nanos < 0 || nanos > 999999) {
throw new IllegalArgumentException(
"nanosecond timeout value out of range");
} if (nanos > 0) {
timeout++;
} wait(timeout);
} public final void wait() throws InterruptedException {
wait(0);
} protected void finalize() throws Throwable { }
}
首先来复习下hash算法和hashmap
在一个长度为n(假设是10000)的线性表(假设是ArrayList)里,存放着无序的数字;如果我们要找一个指定的数字,就不得不通过从头到尾依次遍历来查找,这样的平均查找次数是n除以2(这里是5000)。
我们再来观察Hash表(这里的Hash表纯粹是数据结构上的概念,和Java无关)。它的平均查找次数接近于1,代价相当小,关键是在Hash表里,存放在其中的数据和它的存储位置是用Hash函数关联的。
我们假设一个Hash函数是x*x%5。当然实际情况里不可能用这么简单的Hash函数,我们这里纯粹为了说明方便,而Hash表是一个长度是11的线性表。如果我们要把6放入其中,那么我们首先会对6用Hash函数计算一下,结果是1,所以我们就把6放入到索引号是1这个位置。同样如果我们要放数字7,经过Hash函数计算,7的结果是4,那么它将被放入索引是4的这个位置。这个效果如下图所示。

这样做的好处非常明显。比如我们要从中找6这个元素,我们可以先通过Hash函数计算6的索引位置,然后直接从1号索引里找到它了。
不过我们会遇到“Hash值冲突”这个问题。比如经过Hash函数计算后,7和8会有相同的Hash值,对此Java的HashMap对象采用的是”链地址法“的解决方案。效果如下图所示。
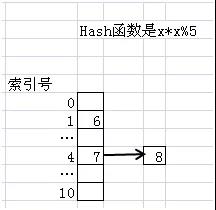
具体的做法是,为所有Hash值是i的对象建立一个同义词链表。假设我们在放入8的时候,发现4号位置已经被占,那么就会新建一个链表结点放入8。同样,如果我们要找8,那么发现4号索引里不是8,那会沿着链表依次查找。
虽然我们还是无法彻底避免Hash值冲突的问题,但是Hash函数设计合理,仍能保证同义词链表的长度被控制在一个合理的范围里。这里讲的理论知识并非无的放矢,大家能在后文里清晰地了解到重写hashCode方法的重要性。
举一个简单例子
当我们用HashMap存入自定义的类时,如果不重写这个自定义类的equals和hashCode方法,得到的结果会和我们预期的不一样。我们来看WithoutHashCode.java这个例子。
在其中的第2到第18行,我们定义了一个Key类;在其中的第3行定义了唯一的一个属性id。当前我们先注释掉第9行的equals方法和第16行的hashCode方法。
1 import java.util.HashMap;
2 class Key {
3 private Integer id;
4 public Integer getId()
5 {return id; }
6 public Key(Integer id)
7 {this.id = id; }
8 //故意先注释掉equals和hashCode方法
9 // public boolean equals(Object o) {
10 // if (o == null || !(o instanceof Key))
11 // { return false; }
12 // else
13 // { return this.getId().equals(((Key) o).getId());}
14 // }
15
16 // public int hashCode()
17 // { return id.hashCode(); }
18 }
19
20 public class WithoutHashCode {
21 public static void main(String[] args) {
22 Key k1 = new Key(1);
23 Key k2 = new Key(1);
24 HashMap<Key,String> hm = new HashMap<Key,String>();
25 hm.put(k1, "Key with id is 1");
26 System.out.println(hm.get(k2));
27 }
28 }
在main函数里的第22和23行,我们定义了两个Key对象,它们的id都是1,就好比它们是两把相同的都能打开同一扇门的钥匙。
在第24行里,我们通过泛型创建了一个HashMap对象。它的键部分可以存放Key类型的对象,值部分可以存储String类型的对象。
在第25行里,我们通过put方法把k1和一串字符放入到hm里; 而在第26行,我们想用k2去从HashMap里得到值;这就好比我们想用k1这把钥匙来锁门,用k2来开门。这是符合逻辑的,但从当前结果看,26行的返回结果不是我们想象中的那个字符串,而是null。
原因有两个—没有重写。第一是没有重写hashCode方法,第二是没有重写equals方法。
当我们往HashMap里放k1时,首先会调用Key这个类的hashCode方法计算它的hash值,随后把k1放入hash值所指引的内存位置。
关键是我们没有在Key里定义hashCode方法。这里调用的仍是Object类的hashCode方法(所有的类都是Object的子类),而Object类的hashCode方法返回的hash值其实是k1对象的内存地址(假设是1000)。

如果我们随后是调用hm.get(k1),那么我们会再次调用hashCode方法(还是返回k1的地址1000),随后根据得到的hash值,能很快地找到k1。
但我们这里的代码是hm.get(k2),当我们调用Object类的hashCode方法(因为Key里没定义)计算k2的hash值时,其实得到的是k2的内存地址(假设是2000)。由于k1和k2是两个不同的对象,所以它们的内存地址一定不会相同,也就是说它们的hash值一定不同,这就是我们无法用k2的hash值去拿k1的原因。
当我们把第16和17行的hashCode方法的注释去掉后,会发现它是返回id属性的hashCode值,这里k1和k2的id都是1,所以它们的hash值是相等的。
我们再来更正一下存k1和取k2的动作。存k1时,是根据它id的hash值,假设这里是100,把k1对象放入到对应的位置。而取k2时,是先计算它的hash值(由于k2的id也是1,这个值也是100),随后到这个位置去找。
但结果会出乎我们意料:明明100号位置已经有k1,但第26行的输出结果依然是null。其原因就是没有重写Key对象的equals方法。
HashMap是用链地址法来处理冲突,也就是说,在100号位置上,有可能存在着多个用链表形式存储的对象。它们通过hashCode方法返回的hash值都是100。

当我们通过k2的hashCode到100号位置查找时,确实会得到k1。但k1有可能仅仅是和k2具有相同的hash值,但未必和k2相等(k1和k2两把钥匙未必能开同一扇门),这个时候,就需要调用Key对象的equals方法来判断两者是否相等了。
由于我们在Key对象里没有定义equals方法,系统就不得不调用Object类的equals方法。由于Object的固有方法是根据两个对象的内存地址来判断,所以k1和k2一定不会相等,这就是为什么依然在26行通过hm.get(k2)依然得到null的原因。
为什么重写equals方法一般必须重写hashcode方法
首先来看下上文提到的integer的源码
@Override
public int hashCode() {
return Integer.hashCode(value);
} public static int hashCode(int value) {
return value;
} public boolean equals(Object obj) {
if (obj instanceof Integer) {
return value == ((Integer)obj).intValue();
}
return false;
}
如Integer类中equals方法和hashcode方法均被重写,Integer类中的hashcode方法就是返回它本身的值,equals方法比较的是它本身的值是否相等。
而equals方法必须要满足以下几个特性
1.自反性:x.equals(x) == true,自己和自己比较相等
2.对称性:x.equals(y) == y.equals(x),两个对象调用equals的的结果应该一样
3.传递性:如果x.equals(y) == true y.equals(z) == true 则 x.equals(z) == true,x和y相等,y和z相等,则x和z相等
4.一致性 : 如果x对象和y对象有成员变量num1和num2,其中重写的equals方法只有num1参加了运算,则修改num2不影响x.equals(y)的值
而这时如果某个类没有重写hashcode方法的话,equals判断两个值相等,但是hashcode的值不相等,如String类,这样就会造成歧义
为什么要重写hashcode方法和equals方法的更多相关文章
- 为什么要重写hashCode()方法和equals()方法及如何重写
我想写的问题有三个: 1.首先我们为什么需要重写hashCode()方法和equals()方法 2.在什么情况下需要重写hashCode()方法和equals()方法 3.如何重写这两个方法 **** ...
- Java 重写hashCode 方法和equals方法
package Container; import java.util.HashSet; import java.util.Iterator; /* Set 元素是无序的(存入和取出的顺序不一定一致) ...
- hashCode()方法和equals方法的重要性。
在Object中有两个重要的方法:hashCode()和equals(Object obj)方法,并且当你按ctrl+alt+s时会有Generator hashCode()和equals().我们不 ...
- java 集合 HashSet 实现随机双色球 HashSet addAll() 实现去重后合并 HashSet对象去重 复写 HashCode()方法和equals方法 ArrayList去重
package com.swift.lianxi; import java.util.HashSet; import java.util.Random; /*训练知识点:HashSet 训练描述 双色 ...
- hashCode方法和equals方法比较
为什么用HashCode比较比用equals方法比较要快呢?我们要想比较hashCode与equals的性能,得先了解HashCode是什么. HashCode HashCode是jdk根据对象的地址 ...
- 【转】为什么要重写hashcode()方法和toString()方法
Object 类 包含toString()和hashCode()方法. 一.toString(): 在Object类里面定义toString()方法的时候返回的对象的哈希code码,这个hashcod ...
- 集合hashCode()方法和equals()办法
1.哈希码: Object中的HashCode方法会返回该对象的的内存真实地址的整数化表示,这个形象的不是真正抵制的整数值就是哈希码. 2.利用哈希码向集合中插入数据的顺序? ...
- java数组、java.lang.String、java.util.Arrays、java.lang.Object的toString()方法和equals()方法详解
public class Test { public static void main(String[] args) { int[] a = {1, 2, 4, 6}; int[] b = a; in ...
- Object、String、数组的 toString() 方法和 equals() 方法及java.util.Arrays
public class Test { public static void main(String[] args) { int[] a = {1, 2, 4, 6}; int[] b = a; in ...
随机推荐
- AngularJs2.0
AngularJs2.0中文官网站发布了. 官网地址:https://angular.cn/ 官网点击任何中文地方都可以显示英文原文,中文文档暂时只有 TypeScript的,JavaScript和d ...
- Hdu1547 Bubble Shooter 2017-01-20 18:38 44人阅读 评论(0) 收藏
Bubble Shooter Time Limit : 2000/1000ms (Java/Other) Memory Limit : 65536/32768K (Java/Other) Tota ...
- Delphi 文件拷贝
function DoCopyDir(sDirName:String;sToDirName:String):Boolean;var hFindFile:Cardinal; t,tfile:String ...
- centos 虚拟机中修改屏幕分辨率
1.$ vi /boot/grub/grub.conf(路径可能会不一样,也可以是 /etc/grub.conf),打开grub.conf文件 2.我们修改分辨率,需要在kernel那行加入 vga= ...
- 安装Greenplum-perfmon-web监控软件遇到的问题及解决
环境 Product Version Pivotal Greenplum (GPDB) 4.3.x Pivotal Greenplum Command Center (GPCC) Others ...
- 45 Useful JavaScript Tips, Tricks and Best Practices
<45 Useful JavaScript Tips, Tricks and Best Practices> http://flippinawesome.org/2013/12/23/45 ...
- apache mpm的一些问题
win2003系统下apache环境,mpm_winnt.c模式,优化参数: ThreadsPerChild 说明:每个子进程建立的线程数,默认值:64,最大值:1920.网上查询资料建议设置在100 ...
- HTML 属性绑定
- asp.net——Base64加密解密
/// <summary> /// 实现Base64加密解密 /// </summary> public sealed class Base64 { /// <summa ...
- django系列2--下载安装、项目创建、配置、启动
Django下载与安装 一.使用pip: 1.下载: django的官网下载页:https://www.djangoproject.com/download/ 1.使用pip安装, 在cmd命令行中输 ...