softmax 杂谈
在多分类问题中,我们可以使用 softmax 函数,对输出的值归一化为概率值。下面举个例子:
import sys
sys.path.append("E:/zlab/")
from plotnet import plot_net, DynamicShow
num_node_list = [10, 7, 5]
figsize = (15, 6)
plot_net(num_node_list, figsize, 'net')
Press `c` to save figure to "net.svg", `Ctrl+d` to break >>
> c:\programdata\anaconda3\lib\site-packages\viznet\context.py(45)__exit__()
-> plt.savefig(self.filename, dpi=300)
(Pdb) c
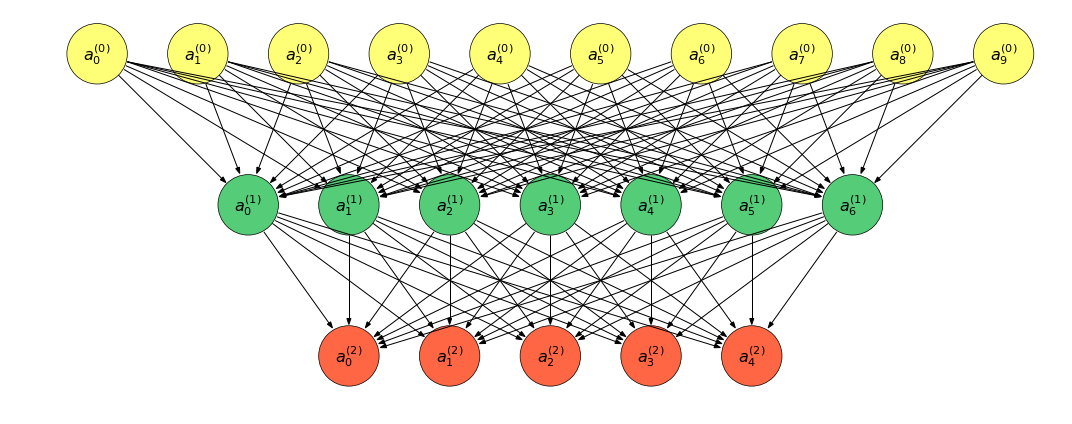
上图转换为表达式:
&a^{(0)} = (a_0^{(0)}, a_1^{(0)}, \cdots, a_9^{(0)})^T\\
&a^{(1)} = (a_0^{(1)}, a_1^{(1)}, \cdots, a_6^{(1)})^T\\
&a^{(2)} = (a_0^{(2)}, a_1^{(2)}, \cdots, a_4^{(2)})^T\\
\end{aligned}
\]
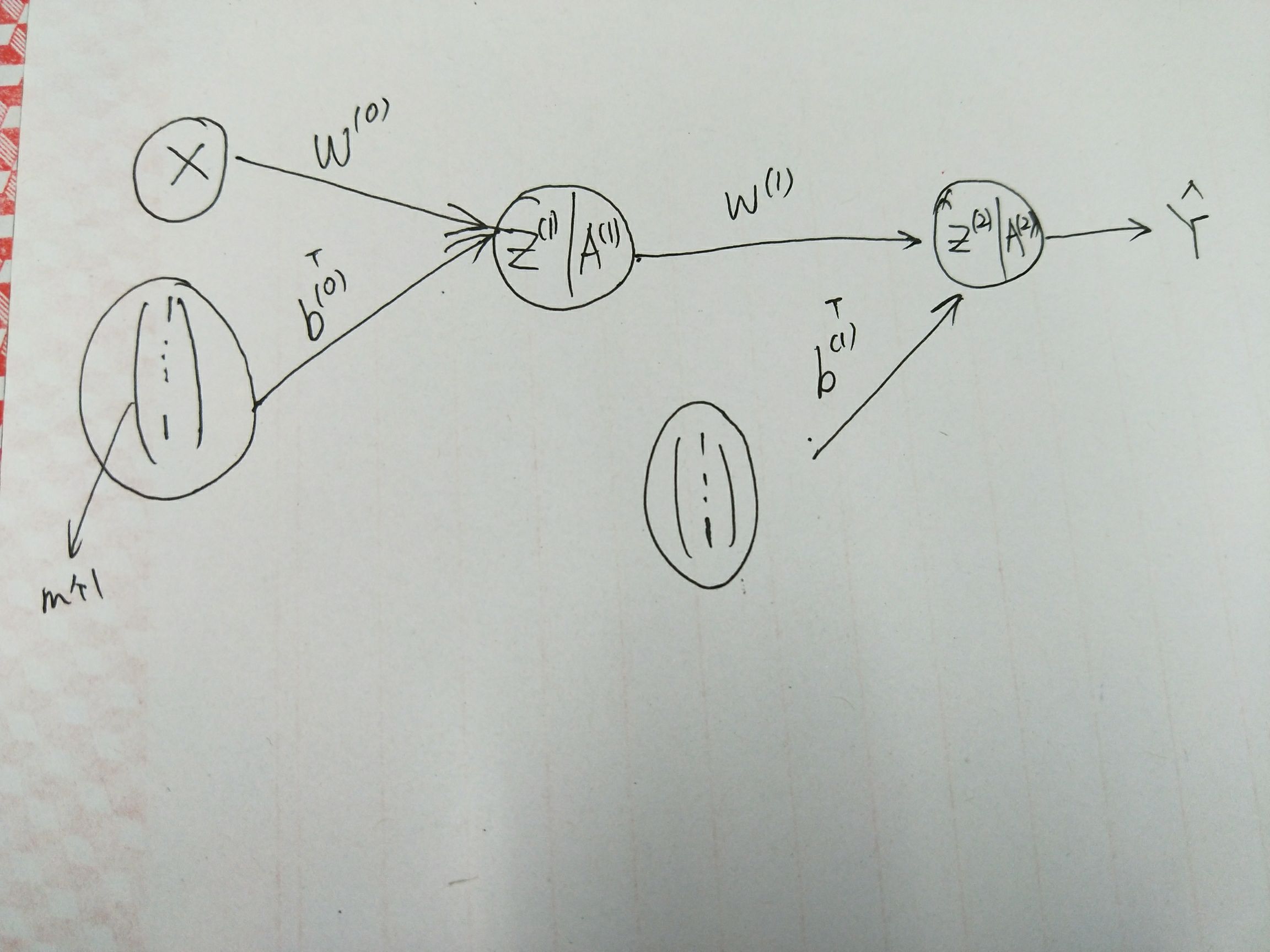
对于任意的 \(0 \leq i \leq 2\), 有前向传播的表达式:
&z^{(i+1)} = W^{(i)}a^{(i)} + b^{(i)}\\
&a^{(i+1)} = f^{(i+1)}(z^{(i+1)})
\end{aligned}
\]
其中,\(f^{(j)}\) 表示激活函数,除了输出层外,一般使用 ReLU 函数;\(W^{(i)}, b^{(i)}\) 为模型参数。
如若我们有 \(m\) 个样本 \(\{x^{(j)}\}_{j=1}^m\) 组成的数据集 \(D\), 称 \(X = (x^{(1)}, x^{(2)}, \cdots, x^{(m)})^T\) 为数据集 \(D\) 的设计矩阵。
这样,前向传播可以改写为:
Z^{(1+i)} = Z^{(i)}W^{(0)} + (b^{(i)})^T\\
A^{(1+i)} = f^{(1+i)}(Z^{(1+i)})
\end{cases}
\]
- \(Z^{(i)} = (z_1^{(i)}, z_2^{(i)}, \cdots, z_m^{(i)})^T\), 这里对 \(z^{(i)}\) 添加下标以区别不同的样本;
- 这里对列向量 \(b^{(i)}\) 进行了 broadcast 操作;
- 且 \(Z^{(0)} = X\).
对于多分类问题,一般输出层对应的激活函数的 softmax 函数:
求解 \(A^{(2)}\):
- 计算 \(exp = \exp(Z^{(1)})\);
- 对 \(exp\) 按列做归一化, 便可得到 \(\text{softmax}(A^{(1)})\).
import numpy as np
def softmax(X):
X_exp = np.exp(X)
partition = X_exp.sum(axis=1, keepdims=True)
return X_exp / partition # 这里应用了广播机制。
softmax([[2, 3,4], [3, 5, 7]])
array([[0.09003057, 0.24472847, 0.66524096],
[0.01587624, 0.11731043, 0.86681333]])
但如果输入值较大或较小时,会出现内存溢出的现象:
softmax([1000, 1000, 100])
C:\ProgramData\Anaconda3\lib\site-packages\ipykernel\__main__.py:5: RuntimeWarning: overflow encountered in exp
C:\ProgramData\Anaconda3\lib\site-packages\ipykernel\__main__.py:7: RuntimeWarning: invalid value encountered in true_divide
array([nan, nan, 0.])
softmax([-10000, -1020, 100, -70220])
array([0., 0., 1., 0.])
一种简单有效避免该问题的方法就是让 \(\exp(z_j)\) 中的 \(z_j\) 替换为 \(z_j - \max_{i} \{z_i\}\), 由于 \(\max_{i}\) 是个固定的常数,所以 \(\exp(z_j)\) 的值没有改变。但是,此时避免了溢出现象的出现。
def softmax(X):
X = np.asanyarray(X)
X -= X.max(axis=-1, keepdims=True)
X_exp = np.exp(X)
print(X_exp)
partition = X_exp.sum(axis=-1, keepdims=True)
return X_exp / partition # 这里应用了广播机制。
softmax([1000, 1000, 100])
[1. 1. 0.]
array([0.5, 0.5, 0. ])
softmax([-10000, -1020, 100, -7220])
[0. 0. 1. 0.]
array([0., 0., 1., 0.])
softmax([-10000, -1020, 100, -70220])
[0. 0. 1. 0.]
array([0., 0., 1., 0.])
当然这种做法也不是最完美的,因为 softmax 函数不可能产生 0 值,但这总比出现 nan 的结果好,并且真实的结果也是非常接近 \(0\) 的。
除此之外,还有一个问题:如果我们计算 \(\log \text{softmax} (z_j)\) 时,先计算 \(\text{softmax}\) 再将其传递给 \(\log\),会错误的得到 \(-\infty\)
np.log(softmax([-10000, -1020, 100, -70220]))
[0. 0. 1. 0.]
C:\ProgramData\Anaconda3\lib\site-packages\ipykernel\__main__.py:1: RuntimeWarning: divide by zero encountered in log
if __name__ == '__main__':
array([-inf, -inf, 0., -inf])
最简单的处理方式是直接加一个很小的常数:
np.log(softmax([-10000, -1020, 100, -70220])+ 1e-7)
[0. 0. 1. 0.]
array([-1.61180957e+01, -1.61180957e+01, 9.99999951e-08, -1.61180957e+01])
为了解决此数值计算的不稳定,MXNet 提供了:
from mxnet.gluon import loss as gloss
loss = gloss.SoftmaxCrossEntropyLoss()
解决计算交叉熵时出现的数值不稳定的问题。
更多数据挖掘内容见:datamining
softmax 杂谈的更多相关文章
- 基于Caffe的Large Margin Softmax Loss的实现(中)
小喵的唠叨话:前一篇博客,我们做完了L-Softmax的准备工作.而这一章,我们开始进行前馈的研究. 小喵博客: http://miaoerduo.com 博客原文: http://www.miao ...
- 基于Caffe的Large Margin Softmax Loss的实现(上)
小喵的唠叨话:在写完上一次的博客之后,已经过去了2个月的时间,小喵在此期间,做了大量的实验工作,最终在使用的DeepID2的方法之后,取得了很不错的结果.这次呢,主要讲述一个比较新的论文中的方法,L- ...
- [Machine Learning] logistic函数和softmax函数
简单总结一下机器学习最常见的两个函数,一个是logistic函数,另一个是softmax函数,若有不足之处,希望大家可以帮忙指正.本文首先分别介绍logistic函数和softmax函数的定义和应用, ...
- 前馈网络求导概论(一)·Softmax篇
Softmax是啥? Hopfield网络的能量观点 1982年的Hopfiled网络首次将统计物理学的能量观点引入到神经网络中, 将神经网络的全局最小值求解,近似认为是求解热力学系统的能量最低点(最 ...
- 【转】PHP 杂谈《重构-改善既有代码的设计》之一 重新组织你的函数
原文地址: PHP 杂谈<重构-改善既有代码的设计>之一 重新组织你的函数 思维导图 点击下图,可以看大图. 介绍 我把我比较喜欢的和比较关注的地方写下来和大家分享.上次我写 ...
- Derivative of the softmax loss function
Back-propagation in a nerual network with a Softmax classifier, which uses the Softmax function: \[\ ...
- Softmax回归
Reference: http://ufldl.stanford.edu/wiki/index.php/Softmax_regression http://deeplearning.net/tutor ...
- softmax分类器+cross entropy损失函数的求导
softmax是logisitic regression在多酚类问题上的推广,\(W=[w_1,w_2,...,w_c]\)为各个类的权重因子,\(b\)为各类的门槛值.不要想象成超平面,否则很难理解 ...
- 【管理心得之三十二】PMP杂谈---------爱情必胜术
这次一反常态,没有场景设计,我想借此文普及一下PMP是什么? 但我不知道这样枯燥的话题能否能引起你的兴趣,我不得不套用“标题党”<爱情必胜术>来博你眼球. 我真没有说谎,此文是献给那些孤身 ...
随机推荐
- JS比较两个数字大小
js不能直降比较两·个数大小,要先转化为整数再比较大小. parseInt()转化. 出处:http://www.jb51.net/article/98251.htm
- Linux基础-Shell脚本
任务一目标:自动部署.初始配置.并启动nginx反向代理服务 把任务拆分来看-自动部署部分,就是先下载安装Nginx 首先建立一个很NB霸气的目录还有一个同样NB霸气的.sh文件 /NBshell/M ...
- C#反射-Assembly.Load、LoadFrom与LoadFile
反射Demo: public class Person { public int Age; public void SayHello() { Console.WriteLine("Hello ...
- 使用solrJ管理索引——(十四)
a) 什么是solrJ solrj是访问Solr服务的java客户端,提供索引和搜索的请求方法,SolrJ通常在嵌入在业务系统中,通过SolrJ的API接口操作Solr服务,如下图:
- 使用RegSetValueEx修改注册表时遇到的问题(转)
原文转自 http://blog.csdn.net/tracyzhongcf/article/details/4076870 1.今天在使用RegSetValueEx时发现一个问题: RegSetVa ...
- 如何编译和安装libevent【转】
转自:http://www.open-open.com/lib/view/open1455522194089.html 来自: http://blog.csdn.net/yangzhenping/ar ...
- python基础===一行 Python 代码实现并行(转)
原文:https://medium.com/building-things-on-the-internet/40e9b2b36148 译文:https://segmentfault.com/a/119 ...
- Python匿名函数详解
python 使用 lambda 来创建匿名函数. lambda这个名称来自于LISP,而LISP则是从lambda calculus(一种符号逻辑形式)取这个名称的. 在Python中,lambda ...
- H5新特性:video与audio的使用
HTML5 DOM 为 <audio> 和 <video> 元素提供了方法.属性和事件. 这些方法.属性和事件允许您使用 JavaScript 来操作 <audio> ...
- Python学习笔记:lambda表达式
lambda表达式:通常是在需要一个函数,但又不想去命名一个函数的时候使用,即匿名函数. 示例如下: add = lambda x,y : x+ y add(1,2) # 结果为3 1.应用在函数式编 ...