使用Python编写简单网络爬虫抓取视频下载资源
我第一次接触爬虫这东西是在今年的5月份,当时写了一个博客搜索引擎。所用到的爬虫也挺智能的,起码比电影来了这个站用到的爬虫水平高多了!
回到用Python写爬虫的话题。
Python一直是我主要使用的脚本语言,没有之中的一个。
Python的语言简洁灵活,标准库功能强大。寻常能够用作计算器,文本编码转换,图片处理,批量下载,批量处理文本等。总之我非常喜欢,也越用越上手,这么好用的一个工具,一般人我不告诉他。。
。很多其它网络编程教程请上网维教程网
由于其强大的字符串处理能力,以及urllib2,cookielib,re,threading这些模块的存在。用Python来写爬虫就简直易于反掌了。简单到什么程度呢。
我当时跟某同学说。我写电影来了用到的几个爬虫以及数据整理的一堆零零散散的脚本代码行数总共不超过1000行,写电影来了这个站点也仅仅有150来行代码。由于爬虫的代码在另外一台64位的黑苹果上,所以就不列出来,仅仅列一下VPS上站点的代码。tornadoweb框架写的
- [xiaoxia@307232 movie_site]$ wc -l *.py template/*
- 156 msite.py
- 92 template/base.html
- 79 template/category.html
- 94 template/id.html
- 47 template/index.html
- 77 template/search.html
以下直接show一下爬虫的编写流程。
以下内容仅供交流学习使用,没有别的意思。
以某湾的最新视频下载资源为例,其网址是
http://某piratebay.se/browse/200
由于该网页里有大量广告,仅仅贴一下正文部分内容:
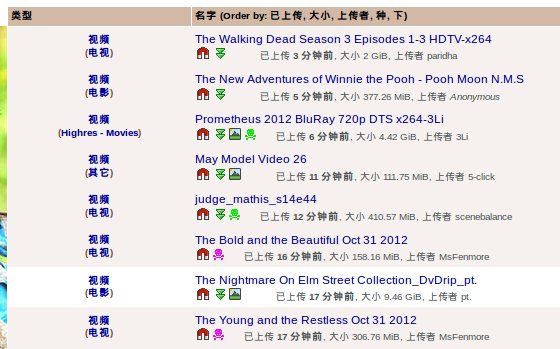
对于一个python爬虫,下载这个页面的源码,一行代码足以。
这里用到urllib2库。
- >>> import urllib2
- >>> html = urllib2.urlopen('http://某piratebay.se/browse/200').read()
- >>> print 'size is', len(html)
- size is 52977
当然,也能够用os模块里的system函数调用wget命令来下载网页内容。对于掌握了wget或者curl工具的同学是非常方便的。
使用Firebug观察网页结构,能够知道正文部分html是一个table。
每个资源就是一个tr标签。
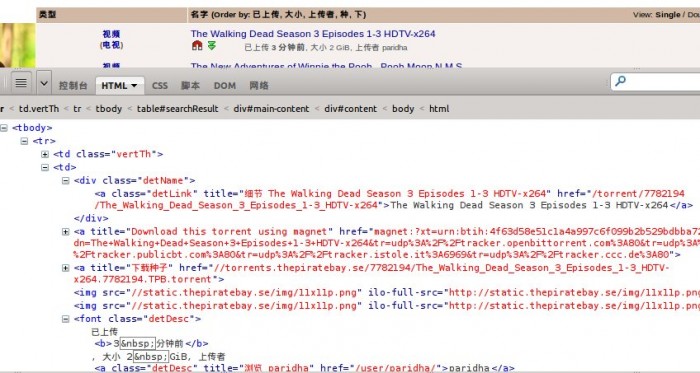
而对于每个资源。须要提取的信息有:
1、视频分类
2、资源名称
3、资源链接
4、资源大小
5、上传时间
就这么多就够了,假设有须要。还能够添加。
首先提取一段tr标签里的代码来观察一下。
- <tr>
- <td class="vertTh">
- <center>
- <a href="/browse/200" title="此文件夹中很多其它">视频</a><br />
- (<a href="/browse/205" title="此文件夹中很多其它">电视</a>)
- </center>
- </td>
- <td>
- <div class="detName"> <a href="/torrent/7782194/The_Walking_Dead_Season_3_Episodes_1-3_HDTV-x264" class="detLink" title="细节 The Walking Dead Season 3 Episodes 1-3 HDTV-x264">The Walking Dead Season 3 Episodes 1-3 HDTV-x264</a>
- </div>
- <a href="magnet:?xt=urn:btih:4f63d58e51c1a4a997c6f099b2b529bdbba72741&dn=The+Walking+Dead+Season+3+Episodes+1-3+HDTV-x264&tr=udp%3A%2F%2Ftracker.openbittorrent.com%3A80&tr=udp%3A%2F%2Ftracker.publicbt.com%3A80&tr=udp%3A%2F%2Ftracker.istole.it%3A6969&tr=udp%3A%2F%2Ftracker.ccc.de%3A80" title="Download this torrent using magnet"><img src="//static.某piratebay.se/img/icon-magnet.gif" alt="Magnet link" /></a> <a href="//torrents.某piratebay.se/7782194/The_Walking_Dead_Season_3_Episodes_1-3_HDTV-x264.7782194.TPB.torrent" title="下载种子"><img src="//static.某piratebay.se/img/dl.gif" class="dl" alt="下载" /></a><img src="//static.某piratebay.se/img/11x11p.png" /><img src="//static.某piratebay.se/img/11x11p.png" />
- <font class="detDesc">已上传 <b>3 分钟前</b>, 大小 2 GiB, 上传者 <a class="detDesc" href="/user/paridha/" title="浏览 paridha">paridha</a></font>
- </td>
- <td align="right">0</td>
- <td align="right">0</td>
- </tr>
以下用正則表達式来提取html代码中的内容。对正則表達式不了解的同学。能够去 http://docs.python.org/2/library/re.html 了解一下。
为何要用正則表達式而不用其它一些解析HTML或者DOM树的工具是有原因的。我之前试过用BeautifulSoup3来提取内容,后来发觉速度实在是慢死了啊。一秒钟可以处理100个内容。已经是我电脑的极限了。
。。而换了正則表達式,编译后处理内容,速度上直接把它秒杀了!
提取这么多内容,我的正則表達式要怎样写呢?
依据我以往的经验,“.*?”或者“.+?”这个东西是非常好使的。只是也要注意一些小问题,实际用到的时候就会知道
对于上面的tr标签代码。我首先须要让我的表达式匹配到的符号是
<tr>
表示内容的開始,当然也能够是别的,仅仅要不要错过须要的内容就可以。
然后我要匹配的内容是以下这个,获取视频分类。
(<a href="/browse/205" title="此文件夹中很多其它">电视</a>)
接着我要匹配资源链接了,
<a href="..." class="detLink" title="...">...</a>
再到其它资源信息,
font class="detDesc">已上传 <b>3 分钟前</b>, 大小 2 GiB, 上传者
最后匹配
</tr>
大功告成。
当然。最后的匹配能够不须要在正則表達式里表示出来,仅仅要開始位置定位正确了,后面获取信息的位置也就正确了。
对正則表達式比較了解的朋友。可能知道怎么写了。我Show一下我写的表达式处理过程,
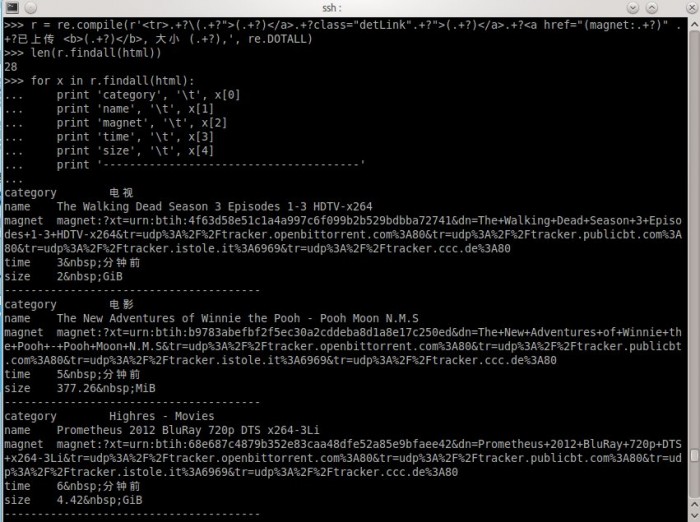
就这么简单。结果出来了,自我感觉挺欢喜的。
当然,这样设计的爬虫是有针对性的,定向爬取某一个站点的内容。也没有不论什么一个爬虫不会对收集到的链接进行筛选。
通常能够使用BFS(宽度优先搜索算法)来爬取一个站点的全部页面链接。
完整的Python爬虫代码,爬取某湾最新的10页视频资源:
- # coding: utf8
- import urllib2
- import re
- import pymongo
- db = pymongo.Connection().test
- url = 'http://某piratebay.se/browse/200/%d/3'
- find_re = re.compile(r'<tr>.+?
- \(.+?
- ">(.+?)</a>.+?class="detLink".+?">(.+?
- )</a>.+?
- <a href="(magnet:.+?
- )" .+?已上传 <b>(.+?)</b>, 大小 (.+?
- ),', re.DOTALL)
- # 定向爬去10页最新的视频资源
- for i in range(0, 10):
- u = url % (i)
- # 下载数据
- html = urllib2.urlopen(u).read()
- # 找到资源信息
- for x in find_re.findall(html):
- values = dict(
- category = x[0],
- name = x[1],
- magnet = x[2],
- time = x[3],
- size = x[4]
- )
- # 保存到数据库
- db.priate.save(values)
- print 'Done!'
以上代码仅供思路展示。实际执行使用到mongodb数据库,同一时候可能由于无法訪问某湾站点而无法得到正常结果。
所以说,电影来了站点用到的爬虫不难写,难的是获得数据后怎样整理获取实用信息。比如。怎样匹配一个影片信息跟一个资源。怎样在影片信息库和视频链接之间建立关联,这些都须要不断尝试各种方法。最后选出比較靠谱的。
曾有某同学发邮件想花钱也要得到我的爬虫的源码。
要是我真的给了,我的爬虫就几百来行代码。一张A4纸。他不会说,坑爹啊。!!
……
都说如今是信息爆炸的时代,所以比的还是谁的数据挖掘能力强 
好吧。那么问题来了学习挖掘机(数据)技术究竟哪家强?
使用Python编写简单网络爬虫抓取视频下载资源的更多相关文章
- [Python学习] 简单网络爬虫抓取博客文章及思想介绍
前面一直强调Python运用到网络爬虫方面很有效,这篇文章也是结合学习的Python视频知识及我研究生数据挖掘方向的知识.从而简介下Python是怎样爬去网络数据的,文章知识很easy ...
- Python 利用Python编写简单网络爬虫实例3
利用Python编写简单网络爬虫实例3 by:授客 QQ:1033553122 实验环境 python版本:3.3.5(2.7下报错 实验目的 获取目标网站“http://bbs.51testing. ...
- Python 利用Python编写简单网络爬虫实例2
利用Python编写简单网络爬虫实例2 by:授客 QQ:1033553122 实验环境 python版本:3.3.5(2.7下报错 实验目的 获取目标网站“http://www.51testing. ...
- 使用selenium实现简单网络爬虫抓取MM图片
撸主听说有个网站叫他趣,里面有个社区,其中有一项叫他趣girl,撸主点进去看了下,还真不错啊,图文并茂,宅男们自己去看看就知道啦~ 接下来当然就是爬取这些妹子的图片啦,不仅仅是图片,撸主发现里面的对话 ...
- 如何利用Python网络爬虫抓取微信好友数量以及微信好友的男女比例
前几天给大家分享了利用Python网络爬虫抓取微信朋友圈的动态(上)和利用Python网络爬虫爬取微信朋友圈动态——附代码(下),并且对抓取到的数据进行了Python词云和wordart可视化,感兴趣 ...
- 如何利用Python网络爬虫抓取微信朋友圈的动态(上)
今天小编给大家分享一下如何利用Python网络爬虫抓取微信朋友圈的动态信息,实际上如果单独的去爬取朋友圈的话,难度会非常大,因为微信没有提供向网易云音乐这样的API接口,所以很容易找不到门.不过不要慌 ...
- 利用Python网络爬虫抓取微信好友的签名及其可视化展示
前几天给大家分享了如何利用Python词云和wordart可视化工具对朋友圈数据进行可视化,利用Python网络爬虫抓取微信好友数量以及微信好友的男女比例,以及利用Python网络爬虫抓取微信好友的所 ...
- 利用Python网络爬虫抓取微信好友的所在省位和城市分布及其可视化
前几天给大家分享了如何利用Python网络爬虫抓取微信好友数量以及微信好友的男女比例,感兴趣的小伙伴可以点击链接进行查看.今天小编给大家介绍如何利用Python网络爬虫抓取微信好友的省位和城市,并且将 ...
- 基于Thinkphp5+phpQuery 网络爬虫抓取数据接口,统一输出接口数据api
TP5_Splider 一个基于Thinkphp5+phpQuery 网络爬虫抓取数据接口 统一输出接口数据api.适合正在学习Vue,AngularJs框架学习 开发demo,需要接口并保证接口不跨 ...
随机推荐
- css伪类和伪元素的区别,:before和::before的区别
伪类用于选择DOM树之外的信息,或是不能用简单选择器进行表示的信息.前者包含那些匹配指定状态的元素,比如:visited,:active:后者包含那些满足一定逻辑条件的DOM树中的元素,比如:firs ...
- cordova打包安卓或IOS应用
1,先搞个java jdk.我先用的1.7版本的,用cordova打包的时候各种报错,应该是向下不兼容吧.又换了个1.8版本.装jdk一定要注意jdk跟jre不能都装在目标文件夹的根目录下,jdk跟j ...
- CentOS7系列--1.4CentOS7服务
CentOS7服务管理 1. 查看服务 1.1. 查看所有运行的服务 [root@centos7 ~]# systemctl -t service UNIT LOAD ACTIVE SUB DESCR ...
- arcgis 加载高德地图 es6的方式
目前很多arcgis 加载高德地图是dojo的方式 外部引入文件,现在改成这种方式 /** * Created by Administrator on 2018/5/14 0014. */ impor ...
- MIPS rop gadgets记录贴&&持续更新
前言 本帖记录一些常用的,效果好的 rop gadgets. uClibc 从栈中设置$t9 并跳到 $t9 的gadgets , __thread_start 函数第二行 使用 案例 使用tips: ...
- 重装系统,打开VS进行程序调试运行的时候 Unable to find manifest signing certificate in the certificate store
重装系统,打开VS进行程序调试运行的时候 Unable to find manifest signing certificate in the certificate store. 项目的属性-> ...
- 创建完美SDK的10个技巧
[编者按]本文作者为 Gal Lavinsky,文中将列出10个零基础小技巧,帮你创建完美的Java SDK.文章系国内 ITOM 管理平台 OneAPM 编译呈现.以下为正文. 本文起源于笔者朋友的 ...
- DevOps 发展融合运维可视化
DevOps,是开发(Development)和运维(Operations)的组合,代表一种文化.运动或实践,旨在促进软件交付和基础设施变更软件开发人员(Dev)和 IT 运维技术人员(Ops)之间的 ...
- 转载:https://blog.csdn.net/qq_22706515/article/details/52595027
https://blog.csdn.net/qq_22706515/article/details/52595027 包含直播,即时通讯. 大平台都有免费版或基础版,对于需求不大的情况比较适合.
- Android组件系列----Activity的生命周期
[声明] 欢迎转载,但请保留文章原始出处→_→ 生命壹号:http://www.cnblogs.com/smyhvae/ 文章来源:http://www.cnblogs.com/smyhvae/p/3 ...