python---基础知识回顾(十)进程和线程(多线程)
前戏:多线程了解
使用多线程处理技术,可以有效的实现程序并发,优化处理能力。虽然进程也可以在独立的内存空间并发执行,
但是生成一个新的进程必须为其分配独立的地址空间,并维护其代码段,堆栈段和数据段等,这种开销是很昂贵的。
其次,进程间的通信实现也是不太方便。而线程能更好的满足要求。
线程是轻量级的,一个进程中的线程使用同样的地址空间,且共享许多资源。
启动线程的事件远远小于启动进程的事件和空间。同时,线程间的切换要比进程间切换快得多。
由于使用了同样的地址空间,所以在通信上,更加方便。一个进程下的线程之间可以直接使用彼此的数据
多线程使用的一个重要目的:最大化CPU的资源利用,当某一线程在等待I/O时,另一个线程可以占用CPU资源。
多线程无论在GUI,网络还是嵌入式上的应用都是非常多的。一个简单的GUI程序,分为前台交互,和后台的处理。可以采用多线程模式
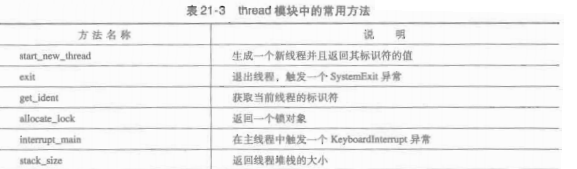
线程的状态:
(1)就绪状态:线程已经获取了处CPU外的其他资源,正在参与调度,等待被执行。当被调度选中后,将立即执行。
(2)运行状态:获取CPU资源,正在系统中运行。
(3)休眠状态:暂时不参与调度,等待特定的事件发生,如I/O事件。
(4)中止状态:线程已经结束运行,等待系统回收线程资源。
全局解释器锁:
python使用全局解释器锁GIL来保证在解释器中仅仅只有一个线程(缺点:不能很好利用CPU密集型),并在各个线程之间切换。当GIL可用的使用,处于就绪状态的线程在获取GIL后就可以运行了。
线程将在指定的间隔时间内运行。当事件到期后,重新进入就绪状态排队等候。(除了时间到期,像是信号灯特定事件也可以是正在运行的线程中断)
线程模块:
thread和threading两种。推荐threading模块。thread模块仅仅提供了一个最小的线程处理功能集。threading是一个高级的线程处理模块,大部分应用实现都是基于他
使用thread模块(简单了解,直接使用不多,但是threading也是基于他的,所以有必要了解)
由于大部分程序不需要有多线程处理的能力,所以在python启动时并不支持多线程。也就是说,python中支持多线程所需要的各种数据结构,特别是GIL还没有创建。(只有一个主线程<一个线程可以完成>,这样会使系统处理更加高效)。若是想要使用多线程,需要调用thread.start_new_thread等方法去通知python虚拟机去创建相关的数据结构和GIL
import _thread as thread
import time def work(index,create_time): #具体的线程
print(time.time()-create_time,"\t\t",index)
print("thread %d exit"%index) if __name__ == "__main__":
for index in range():
thr1 = thread.start_new_thread(work, (index,time.time())) # time.sleep()
print("Main thread exit")
Main thread exit
0.003000497817993164
thread exit
0.002500295639038086
主线程未使用sleep进行阻塞,子线程不一定会全部执行
import _thread as thread
import time def work(index,create_time): #具体的线程
print(time.time()-create_time,"\t\t",index)
print("thread %d exit"%index) if __name__ == "__main__":
for index in range():
thr1 = thread.start_new_thread(work, (index,time.time())) time.sleep()
print("Main thread exit")
----------------------------------------------------------
0.002000093460083008
0.0030002593994140625
0.0030002593994140625
0.0030002593994140625
0.0010001659393310547
thread exit
thread exit
thread exit
thread exit
thread exit
Main thread exit
主线程使用sleep进行阻塞,子线程全部执行
注意:线程的调用顺序是随机的,谁先抢到锁,谁就能先执行。当线程函数执行结束的时候线程就已经默认终止了。当然也可以使用模块中的exit方法显示退出。
开始进入正题:使用threading.Thread类
创建10个前台线程,然后控制器就交给了CPU,CPU根据算法进行调度。分片执行指令
import threading
import time def show(arg):
time.sleep()
print("thread"+str(arg)) if __name__ == "__main__":
t_list = [] for i in range():
t = threading.Thread(target=show,args=(i,))
t_list.append(t)
t.start() for i in range():
t_list[i].join() print("main thread stop")
thread0
thread1
thread3
thread2
thread4
thread5
thread6
thread7
thread8
thread9
main thread stop
输出结果
类的使用
import threading, time class MyThread(threading.Thread):
def __init__(self,num): #线程构造函数
threading.Thread.__init__(self)
self.num = num def run(self):
print("running on number:%s"%self.num)
time.sleep() if __name__ == "__main__":
thread1 = MyThread()
thread2 = MyThread()
thread1.start()
thread2.start() print("thread end")
running on number:
running on number:
thread end
输出结果,这里没有使用join等待子线程,所以执行顺序是随机的
class MyThread(threading.Thread):
def __init__(self,thread_name): #线程构造函数
threading.Thread.__init__(self,name=thread_name) #设置线程名
管理线程
在线程生成和终止之间,就是线程的运行时间。这段时间可以对指定的线程进行管理,从而更好的利用其并发性。
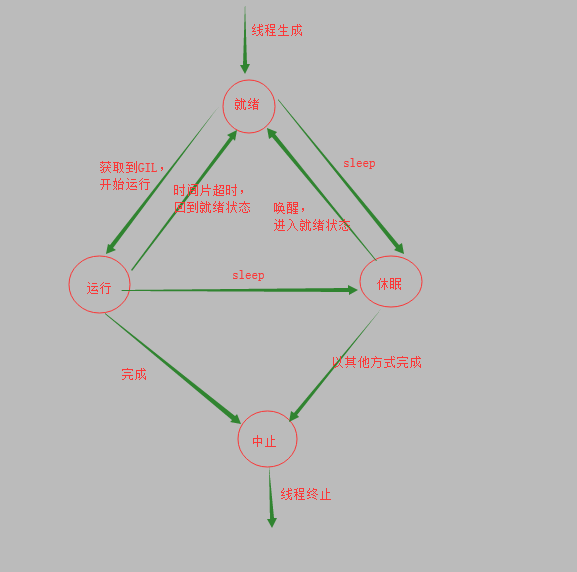
线程状态转变
- thread调用start方法后将生成线程,线程状态变为就绪状态。
- 在就绪状态中,如果此线程获取了GIL,将转变为运行状态,执行run中代码。
- 在执行过程中,如果遇到sleep函数,线程将进入睡眠状态,将CPU控制器(GIL)给其他线程,当过了一定时间后,系统将唤醒线程,该线程将进入就绪状态当再度获取GIL后,从睡眠位置开始(sleep中的时间一直在执行,会接着执行完剩余的时间),将所有代码执行完毕后,线程进入中止状态,然后比系统回收释放其线程资源
import threading, time def run1():
print("start")
time.sleep()
print(threading.currentThread().getName(),"is run")
print("end") def run2():
print(threading.currentThread().getName(),"is run") if __name__ == "__main__":
thread1 = threading.Thread(target=run1,name="线程一")
thread1.start() time.sleep() thread2 = threading.Thread(target=run2, name="线程二")
thread2.start() thread1.join()
thread2.join() print("end")
---------------------------------------------------------
start
线程二 is run
线程一 is run
end
endsleep阻塞后,进入睡眠状态,被唤醒后从当前位置开始执行
1.主线程等待所有子线程join
import threading, time class MyThread(threading.Thread):
def __init__(self,num): #线程构造函数
threading.Thread.__init__(self)
self.num = num def run(self):
print("running on number:%s start"%self.num)
time.sleep()
print("running on number:%s end"%self.num) if __name__ == "__main__":
thread1 = MyThread()
thread2 = MyThread()
thread1.start()
thread2.start() thread1.join() #阻塞,等待线程thread1结束
thread2.join() #阻塞,等待线程thread2结束 print("thread end")
running on number: start
running on number: start
running on number: end
running on number: end
thread end
输出结果
注意:
(1)join方法中有一个参数,可以设置超时。若有此参数。join无返回值(None),无法判断子线程是否结束,这时可以使用isAlive方法判断是否发生了超时。
import threading, time class MyThread(threading.Thread):
def __init__(self,num): #线程构造函数
threading.Thread.__init__(self)
self.num = num def run(self):
print("running on number:%s start"%self.num)
time.sleep()
print("running on number:%s end"%self.num) if __name__ == "__main__":
thread1 = MyThread()
thread2 = MyThread()
thread1.start()
thread2.start() thread1.join()
print(thread1.isAlive()) #由于此时thread1还没有执行完毕,所以True
thread2.join()
print(thread2.isAlive()) #这时由于堵塞,线程已经执行完毕,返回False print("thread end")
----------------------------------------------------------
running on number: start
running on number: start
True
running on number: end
running on number: end
False
thread end
isAlive的使用
(2)一个线程可以多次使用join方法
import threading, time class MyThread(threading.Thread):
def __init__(self,num): #线程构造函数
threading.Thread.__init__(self)
self.num = num def run(self):
print("running on number:%s start"%self.num)
time.sleep()
print("running on number:%s end"%self.num) if __name__ == "__main__":
thread1 = MyThread()
thread2 = MyThread()
thread1.start()
thread2.start() thread1.join()
thread1.join() #这个可以将上面没有接受的再次进行获取
thread1.join() #这个也是测试join可以使用多次的
print(thread1.isAlive()) thread2.join()
print(thread2.isAlive()) print("thread end")
----------------------------------------------------------
running on number: start
running on number: start
running on number: end
running on number: end
False
False
thread end
join可以使用多次
(3)线程不能在自己的运行代码中调用join方法,否则会造成死锁
class MyThread(threading.Thread):
def run(self):
print(threading.currentThread(),self)
-------------------------------------------------------------
<MyThread(Thread-, started )>
#currentThread
<MyThread(Thread-, started )>
#self
currentThread方法,指的是当前线程对象
def current_thread():
"""Return the current Thread object, corresponding to the caller's thread of control. If the caller's thread of control was not created through the threading
module, a dummy thread object with limited functionality is returned. """
try:
return _active[get_ident()]
except KeyError:
return _DummyThread() currentThread = current_thread
currentThread 方法源码
def join(self, timeout=None):
"""Wait until the thread terminates. This blocks the calling thread until the thread whose join() method is
called terminates -- either normally or through an unhandled exception
or until the optional timeout occurs. When the timeout argument is present and not None, it should be a
floating point number specifying a timeout for the operation in seconds
(or fractions thereof). As join() always returns None, you must call
isAlive() after join() to decide whether a timeout happened -- if the
thread is still alive, the join() call timed out. When the timeout argument is not present or None, the operation will
block until the thread terminates. A thread can be join()ed many times. join() raises a RuntimeError if an attempt is made to join the current
thread as that would cause a deadlock. It is also an error to join() a
thread before it has been started and attempts to do so raises the same
exception.在当前线程中执行join方法会导致死锁,在start之前也会出现同样的错误 """
if not self._initialized: #线程构造方法中设置其为True
raise RuntimeError("Thread.__init__() not called")
if not self._started.is_set(): #构造时,为false,线程start开始进入就绪状态时,将事件设置为True
raise RuntimeError("cannot join thread before it is started")
if self is current_thread(): #用于判断运行中的线程对象和self当前调用的线程是否一致
raise RuntimeError("cannot join current thread") if timeout is None:
self._wait_for_tstate_lock()
else:
# the behavior of a negative timeout isn't documented, but
# historically .join(timeout=x) for x< has acted as if timeout=
self._wait_for_tstate_lock(timeout=max(timeout, ))
(4)注意join方法的顺序,需要在线程先生成后start后面,才能去等待
if not self._started.is_set(): #构造时,为false,线程start开始时,将事件设置为True
- 构造函数中self._started = Event(),默认Event()对象中的表示Flag是False
class Event:
def __init__(self):
self._cond = Condition(Lock())
self._flag = FalseEvent中构造函数
线程开始start进入就绪状态
def start(self):
"""Start the thread's activity. It must be called at most once per thread object. It arranges for the
object's run() method to be invoked in a separate thread of control. This method will raise a RuntimeError if called more than once on the
same thread object. """
if not self._initialized: #构造函数中会进行设置为True
raise RuntimeError("thread.__init__() not called") if self._started.is_set(): #此时为False
raise RuntimeError("threads can only be started once")
with _active_limbo_lock:
_limbo[self] = self
try:
_start_new_thread(self._bootstrap, ()) #这里开始调用上面提及的thread模块中方法,生成线程,执行_bootstarp方法
except Exception:
with _active_limbo_lock:
del _limbo[self]
raise
self._started.wait()- 在start方法中何时将_started中Flag设置为True,看_bootstrap方法
def _bootstrap(self):
# Wrapper around the real bootstrap code that ignores
# exceptions during interpreter cleanup. Those typically
# happen when a daemon thread wakes up at an unfortunate
# moment, finds the world around it destroyed, and raises some
# random exception *** while trying to report the exception in
# _bootstrap_inner() below ***. Those random exceptions
# don't help anybody, and they confuse users, so we suppress
# them. We suppress them only when it appears that the world
# indeed has already been destroyed, so that exceptions in
# _bootstrap_inner() during normal business hours are properly
# reported. Also, we only suppress them for daemonic threads;
# if a non-daemonic encounters this, something else is wrong.
try:
self._bootstrap_inner()
except:
if self._daemonic and _sys is None:
return
raise_bootstrap指向_bootstrap_inner方法
def _bootstrap_inner(self):
try:
self._set_ident()
self._set_tstate_lock()
self._started.set() #将其Flag设置为True
with _active_limbo_lock:
_active[self._ident] = self
del _limbo[self]
...............
所以join需要在start方法后面去执行。
2.线程中的局部变量
线程也是需要自己的私有变量。
import threading,time def run(n_lst,num):
time.sleep()
n_lst.append(num)
print(n_lst) n_lst = []
t_list = [] for i in range():
thread = threading.Thread(target=run,args=(n_lst,i))
t_list.append(thread)
thread.start() print("main thread end")
----------------------------------------------------------
main thread end
[]
[, ]
[, , ]
[, , , ]
[, , , , ]
[, , , , , ]
[, , , , , , ]
[, , , , , , , ]
[, , , , , , , , ]
[, , , , , , , , , ]
全局变量,线程共享
import threading,time def run(n_lst,num):
time.sleep()
n_lst.lst=[] #根据线程局部变量对象,产生一个列表类型
n_lst.lst.append(num) #对这个局部变量进行操作
print(n_lst.lst) lcl = threading.local()
t_list = [] for i in range():
thread = threading.Thread(target=run,args=(lcl,i))
t_list.append(thread)
thread.start() print("main thread end")
main thread end
[]
[]
[]
[]
[]
[]
[]
[]
[]
[]
输出结果
import threading,time,random class ThreadLocal():
def __init__(self):
self.local = threading.local() #生成线程局部变量 def run(self): #用于线程调用
time.sleep(random.random())
self.local.number = []
for i in range():
self.local.number.append(random.choice(range()))
print(threading.currentThread(),self.local.number) if __name__ == "__main__": threadLocal = ThreadLocal()
t_list = [] for i in range():
thread = threading.Thread(target=threadLocal.run)
t_list.append(thread)
thread.start() for i in range():
t_list[i].join() print("main thread end")
----------------------------------------------------------
<Thread(Thread-, started )> [, , , , , , , , , ]
<Thread(Thread-, started )> [, , , , , , , , , ]
<Thread(Thread-, started )> [, , , , , , , , , ]
<Thread(Thread-, started )> [, , , , , , , , , ]
<Thread(Thread-, started )> [, , , , , , , , , ]
<Thread(Thread-, started )> [, , , , , , , , , ]
<Thread(Thread-, started )> [, , , , , , , , , ]
<Thread(Thread-, started )> [, , , , , , , , , ]
<Thread(Thread-, started )> [, , , , , , , , , ]
<Thread(Thread-, started )> [, , , , , , , , , ]
main thread end
另一种实现方法,将局部变量和需要运行的函数封装在同一个类中,生成线程时调用
线程之间的同步
为了防止脏数据的产生,我们有时需要允许线程独占性的访问共享数据,这就是线程同步。(进程也是,线程用得更多)
线程的同步机制:锁机制,条件变量,信号量,和同步队列。
1.临界资源和临界区
临界资源是指一次值允许一个线程访问的资源,如硬件资源和互斥变量一类的软件资源。
对临界资源的共享只能采用互斥的方式。也就是说,在一个线程访问的时候,其他线程必须等待。此时线程之间不能交替的使用该资源,否则会导致执行结果的不可预期和不一致性。
一般地,线程中访问临界资源的代码部分被成为临界区
临界区的代码不能同时执行。在线程进入临界区之前,需要先去检查是否有线程在访问临界区。若是临界资源空闲,才可以进入临界区执行,并且设置访问标识,使得其他线程不能在加入临界区。若是临界资源被占用了,该线程需要等待,知道临界资源被释放
import threading global_num = def func1():
global global_num
for i in range():
global_num +=
print('---------func1:global_num=%s--------' % global_num) def func2():
global global_num
for i in range():
global_num +=
print('--------fun2:global_num=%s' % global_num) print('global_num=%s' % global_num) t1 = threading.Thread(target=func1)
t1.start() t2 = threading.Thread(target=func2)
t2.start()
global_num=
---------func1:global_num=--------
--------fun2:global_num=
操作次数越大,越容易获取我们想要的结果。若是只去循环10000,那么可能无法看出结果
导致这个现象的原因:
A,B两个线程同时去获取全局变量资源,比如:在某一时刻,A,B获取的global_num都是1000(并发,同时获取到这个数),但是此时A先拿着这个数去执行一次,加一了-->1001,这时B也开始对这个全局变量进行了操作,但是B获取的这个数还是之前获取的1000,这时对其进行加一,在返回赋值给global_num,导致数据出错。
注意:将数据取出,再到运算是需要时间的,误差出现就在这段时间中
import threading,time num = def run():
global num
for i in range():
num +=
print(num) if __name__ == "__main__": t_list = [] for i in range():
thread = threading.Thread(target=run)
t_list.append(thread)
thread.start() for i in range():
t_list[i].join() print("main thread end")
---------------------------------------------------------- main thread end
越多线程对数据操作,产生的误差越大
解决方案:我们应该阻止线程同时去获取和改变变量。
2.锁机制Lock
锁机制是原子操作:就是不能被更高等级中断抢夺优先的操作。保证了临界区的进入部分和离开部分不会因为其他线程的中断而产生问题。在thread和threading中都有锁机制,threading是在thread基础上发展的。
缺点:锁状态只有“已锁”和“未锁”两种状态,说明其功能有限
import threading,time,random num =
lock = threading.RLock() def run():
lock.acquire()
global num
for i in range():
num +=
print(num)
lock.release() if __name__ == "__main__": t_list = [] for i in range():
thread = threading.Thread(target=run)
t_list.append(thread)
thread.start() for i in range():
t_list[i].join() print("main thread end")
main thread end
输出结果是符合要求的。
虽然锁机制是可以解决一些数据同步的问题,但是只是最低层次的同步。当线程变多,关系复杂的时候,就需要更加高级的同步机制。
3.信号量Semaphore
信号量是一种有效的数据同步机制。主要用在对优先的资源进行同步的时候。信号量内部维护了对于资源的一个计数器,原来表示还可以用的资源数。这个计数器不不会小于0的。
经常称用在信号量上的操作为P(获取),V(存放)操作,两者都会阻塞等待。实际上是和acquire和release是一样的。
推文:理解PV操作和信号量
上面的锁变量(互斥锁),同时值允许一个线程更改数据,而Semaphore信号量是允许移动数量的线程更改数据。就像一定数量的停车位,最多允许10个车停放,后面来的车只有当停车位中的车离开才能进入
import threading,time def run(sig,num):
sig.acquire() #计数值减一,若为0则阻塞
time.sleep()
print("run the thread: %s"%num)
sig.release() #计数值加一 if __name__ == "__main__": t_list = []
semaphore = threading.BoundedSemaphore(3) #允许一次进入3个线程进行操作,初始计数值为3 for i in range():
thread = threading.Thread(target=run,args=(semaphore,i))
t_list.append(thread)
thread.start() for i in range():
t_list[i].join() print("main thread end")
4.条件变量Condition
使用这种机制使得只有在特定的条件下才可以对临界区进行访问。条件变量通过允许线程阻塞和等待线程发送信号的方式弥补了锁机制中的锁状态不足的问题。
在条件变量同步机制中,线程可以使用条件变量来读取一个对象的状态进行监视,或者用其发出事件通知。当某个线程的条件变量被改变时,相应的条件变量将会唤醒一个或者多个被此条件变量阻塞的线程。然后这些线程将重新测试条件是否满足,从而完成线程之间的数据同步。
也可以用于锁机制,其中提供了acquire和release方法。除此之外,此同步机制还有wait,notify,notifyAll等常用方法。
import threading, time class Goods: #产品类
def __init__(self):
self.count = def produce(self,num=): #产品增加
self.count += num def consume(self): #产品减少
if self.count:
self.count -= def isEmpty(self): #判断是否为空
return not self.count class Produder(threading.Thread): #生产者模型
def __init__(self,condition,goods,sleeptime=):
threading.Thread.__init__(self)
self.cond = condition
self.goods = goods
self.sleeptime = sleeptime def run(self):
cond = self.cond
goods = self.goods
while True:
cond.acquire()
goods.produce()
print("Goods Count:",goods.count," Producer thread produces")
cond.notifyAll()
cond.release()
time.sleep(self.sleeptime) class Consumer(threading.Thread):
def __init__(self,index,condition,goods,sleeptime=):
threading.Thread.__init__(self)
self.goods = goods
self.cond = condition
self.sleeptime = sleeptime def run(self):
cond = self.cond
goods = self.goods
while True:
time.sleep(self.sleeptime)
cond.acquire()
while goods.isEmpty():
cond.wait() #如果为空则阻塞
goods.consume()
print("Goods Count: ",goods.count,"Consumer thread:",threading.currentThread().getName(),"Consume")
cond.release() if __name__ == "__main__":
goods = Goods()
cond = threading.Condition() producer = Produder(cond,goods) #生产者线程
producer.start() cons = []
for i in range():
consumer = Consumer(i,cond,goods)
consumer.start()
cons.append(consumer) producer.join()
for i in range():
cons[i].join()
生产者消费者模型
补充:
cond.acquire()
while goods.isEmpty():
cond.wait() #如果为空则阻塞
goods.consume()
print("Goods Count: ",goods.count,"Consumer thread:",threading.currentThread().getName(),"Consume")
cond.release()
cond.wait()方法,可以参考上面的线程状态转变,虽然此时是在运行状态,但是当wait()方法进入阻塞状态,会进入休眠状态。退出运行状态,
def wait(self, timeout=None):
"""Wait until notified or until a timeout occurs. If the calling thread has not acquired the lock when this method is
called, a RuntimeError is raised. This method releases the underlying lock, and then blocks until it is
awakened by a notify() or notify_all() call for the same condition
variable in another thread, or until the optional timeout occurs. Once
awakened or timed out, it re-acquires the lock and returns. When the timeout argument is present and not None, it should be a
floating point number specifying a timeout for the operation in seconds
(or fractions thereof). When the underlying lock is an RLock, it is not released using its
release() method, since this may not actually unlock the lock when it
was acquired multiple times recursively. Instead, an internal interface
of the RLock class is used, which really unlocks it even when it has
been recursively acquired several times. Another internal interface is
then used to restore the recursion level when the lock is reacquired. """
if not self._is_owned():
raise RuntimeError("cannot wait on un-acquired lock")
waiter = _allocate_lock()
waiter.acquire()
self._waiters.append(waiter)
saved_state = self._release_save()
gotit = False
try: # restore state no matter what (e.g., KeyboardInterrupt)
if timeout is None:
waiter.acquire()
gotit = True
else:
if timeout > :
gotit = waiter.acquire(True, timeout)
else:
gotit = waiter.acquire(False)
return gotit
finally:
self._acquire_restore(saved_state)
if not gotit:
try:
self._waiters.remove(waiter)
except ValueError:
pass
wait方法
在Condition中wait方法中,必须先获取到锁RLock,才能去wait,不然会触发RuntimeError,使用wait方法会释放release锁,将计数加一。直到被notify或者notifyAll后被唤醒。从wait位置向下执行代码。
注意:在release锁后,这个锁可能还是会被消费者获取,再进入wait等待,甚至会所有的消费者都进入wait阻塞状态后,生产者才能获取到锁,进行生产。
import threading def run(cond,i):
cond.acquire()
cond.wait()
print("run the thread: %s"%i)
cond.release() if __name__ == "__main__":
cond = threading.Condition() for i in range():
t = threading.Thread(target=run,args=(cond,i))
t.start() while True:
inp = input(">>>>")
if inp == "q":
break
elif inp == "a":
cond.acquire()
cond.notifyAll()
else:
cond.acquire()
cond.notify(int(inp)) #notify中参数代表的是一次通知几个。
cond.release() print("end")
5.同步队列
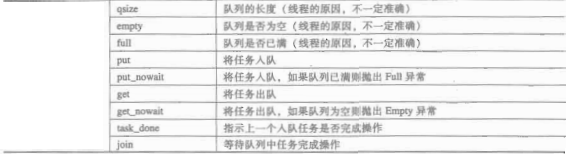
最容易处理的是同步队列。这是一个专门为多线程访问所设计的数据结构。可以安全有效的传递数据。
Queue模块中有一个Queue类。其构造函数中可以指定一个maxsize值,当其小于或等于0时,表示对队列的长度没有限制。当其大于0时,则是指定了队列的长度。当队列的长度达到最大长度而又有新的线程要加入队列的时候,则需要等待。
import threading
import time,random
from queue import Queue class Worker(threading.Thread):
def __init__(self,index,queue):
threading.Thread.__init__(self)
self.index = index
self.queue = queue def run(self):
while True:
time.sleep(random.random())
item = self.queue.get() #从同步队列中获取对象,没有获取到对象,则阻塞在此处
if item is None: #循环终止
break
print("index:",self.index,"task",item,"finished")
self.queue.task_done() #指示上一个入队的任务是否完成操作 if __name__ == "__main__":
queue = Queue() #生成一个不限制长度的同步队列
for i in range():
Worker(i,queue).start() for i in range():
queue.put(i) for i in range():
queue.put(None)
6.事件event
python线程的事件用于主线程控制其他线程的执行,事件主要提供了三个方法 set、wait、clear。
事件处理的机制:全局定义了一个“Flag”,如果“Flag”值为 False,那么当程序执行 event.wait 方法时就会阻塞,如果“Flag”值为True,那么event.wait 方法时便不再阻塞。
import threading def func(event):
print("start")
event.wait() #等待Flag变为True
print("exec") if __name__ == "__main__":
event = threading.Event()
for i in range():
t = threading.Thread(target=func,args=(event,))
t.start() event.clear() #默认是False,此处可不需要
inp = input(">>>")
if inp == "true":
event.set() #将其Flag设置为True
start
start
start
start
start
start
start
start
start
start
>>>true
exec
exec
exec
exec
exec
exec
exec
exec
exec
exec
输出结果
python---基础知识回顾(十)进程和线程(多线程)的更多相关文章
- python爬虫主要就是五个模块:爬虫启动入口模块,URL管理器存放已经爬虫的URL和待爬虫URL列表,html下载器,html解析器,html输出器 同时可以掌握到urllib2的使用、bs4(BeautifulSoup)页面解析器、re正则表达式、urlparse、python基础知识回顾(set集合操作)等相关内容。
本次python爬虫百步百科,里面详细分析了爬虫的步骤,对每一步代码都有详细的注释说明,可通过本案例掌握python爬虫的特点: 1.爬虫调度入口(crawler_main.py) # coding: ...
- Windows内核基础知识-8-监听进程、线程和模块
Windows内核基础知识-8-监听进程.线程和模块 Windows内核有一种强大的机制,可以在重大事件发送时得到通知,比如这里的进程.线程和模块加载通知. 本次采用链表+自动快速互斥体来实现内核的主 ...
- Py修行路 python基础 (二十五)线程与进程
操作系统是用户和硬件沟通的桥梁 操作系统,位于底层硬件与应用软件之间的一层 工作方式:向下管理硬件,向上提供接口 操作系统进行切换操作: 把CPU的使用权切换给不同的进程. 1.出现IO操作 2.固定 ...
- python基础知识回顾之列表
在python 中,主要的常用数据类型有列表,元组,字典,集合,字符串.对于这些基础知识,应该要能够足够熟练掌握. 如何创建列表: # 创建一个空列表:定义一个变量,然后在等号右边放一个中括号,就创建 ...
- python基础知识回顾之字符串
字符串是python中使用频率很高的一种数据类型,内置方法也是超级多,对于常用的方法,还是要注意掌握的. #author: Administrator #date: 2018/10/20 # pyth ...
- python基础知识回顾之元组
元组与列表的方法基本一样,只不过创建元组是用小括号()把元素括起来,两者的区别在于,元组的元素不可被修改. 元组被称为只读列表,即数据可以被查询,但不能被修改,列表的切片操作适用于元组. 元组写在小括 ...
- python基础知识回顾[1]
1.声明变量 # 声明一个变量name用来存储一个字符串'apollo' name = 'apollo' # 声明一个变量age用来存储一个数字20 age = 20 # 在控制台打印变量name中存 ...
- C#基础知识回顾--线程传参
C#基础知识回顾--线程传参 在不传递参数情况下,一般大家都使用ThreadStart代理来连接执行函数,ThreadStart委托接收的函数不能有参数, 也不能有返回值.如果希望传递参数给执行函数, ...
- Python 基础知识(一)
1.Python简介 1.1.Python介绍 python的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,吉多·范罗苏姆(中文名字:龟叔)为了在阿姆斯特丹打发时 ...
- Java基础知识回顾之七 ----- 总结篇
前言 在之前Java基础知识回顾中,我们回顾了基础数据类型.修饰符和String.三大特性.集合.多线程和IO.本篇文章则对之前学过的知识进行总结.除了简单的复习之外,还会增加一些相应的理解. 基础数 ...
随机推荐
- 第二阶段每日站立会议Second Day
昨天我在手机端安装cpp后进行界面效果测试以及进一步完善 今天对图片显示的大小进行调整 遇到的问题:当图片太小时,显示一块灰色区域,不美观
- 炸弹人 之 N A B C D
团队开发之个人——NABCD理解 项目名称:炸弹人(app)N(need): 随着移动终端的发展,各类软件的需求必然会有长期的需求,而游戏类软件是不同年龄阶段的人共同的需求,我们将要开发的这款游 ...
- Task 6.2冲刺会议四 /2015-5-17
今天主要是学习并熟悉了C#的开发流程,把他的文件的大体结构和每个组件之间的联系弄清楚之后.开始写服务器部分的内容.学习过程中,感觉网上的资料有些太鱼龙混杂了,不知道该怎么取舍.明天准备完善服务器的功能 ...
- linux 常用命令-配置登陆方式
使用阿里云服务器,启动实例(ubuntu 7.4,密码登录)后,通过xshell登陆,但是发现xshell中密码登录是灰色禁用的,很惆怅啊,明明设置的就是密码登录,在xshell中找了一通设置发现并没 ...
- HDU 1170 Shopping Offers 离散+状态压缩+完全背包
题目链接: http://poj.org/problem?id=1170 Shopping Offers Time Limit: 1000MSMemory Limit: 10000K 问题描述 In ...
- 16_常用API_第16天(正则表达式、Date、DateFormat、Calendar)_讲义
今日内容介绍 1.正则表达式的定义及使用 2.Date类的用法 3.Calendar类的用法 ==========================================第一阶段======= ...
- rpm安装和二进制安装
rpm包安装 Tomcat RPM安装(先安装JDK + 再安装Tomcat) 1:升级系统自带的JDK(也可以使用oracle的JDK) yum install -y java-1.8.0-open ...
- Beta阶段——4
一.提供当天站立式会议照片一张: 二. 每个人的工作 (有work item 的ID) (1) 昨天已完成的工作: 完善了用户管理模式的功能 (2) 今天计划完成的工作: 对用户功能的添加. (3) ...
- Delphi判断字符串中是否包含汉字,并返回汉字位置
//1,函数代码{判断字符串是否包含汉字// judgeStr:要判断的字符串//posInt:第一个汉字位置}function TForm2.IsHaveChinese(judgeStr: stri ...
- XLSReadWriteII5使用示例
之前一直是使用XLSReadWriteII4,今天更新到XLSReadWriteII5,测试了一下,发现一些操作变化比较大,现将XLSReadWriteII5的使用示例写一下,以下是代码和生成的exc ...