spark科普
普Spark,Spark是什么,如何使用Spark(1)转自:http://www.aboutyun.com/thread-6849-1-1.html
阅读本文章可以带着下面问题:
1.Spark基于什么算法的分布式计算(很简单)
2.Spark与MapReduce不同在什么地方
3.Spark为什么比Hadoop灵活
4.Spark局限是什么
5.什么情况下适合使用Spark
科普Spark,Spark核心是什么,如何使用Spark(2)转自:http://www.aboutyun.com/thread-6850-1-1.html
本篇文章很重要,也是spark为什么是Spark原因:
1.Spark的核心是什么?
2.RDD在内存不足时,是怎么处理的?
3.如何创建RDD,有几种方式
4.Spark编程支持几种语言
5.是否能够写出一个Driver程序
什么是Spark
Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于map reduce算法实现的分布式计算,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出和结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。其架构如下图所示:
<ignore_js_op>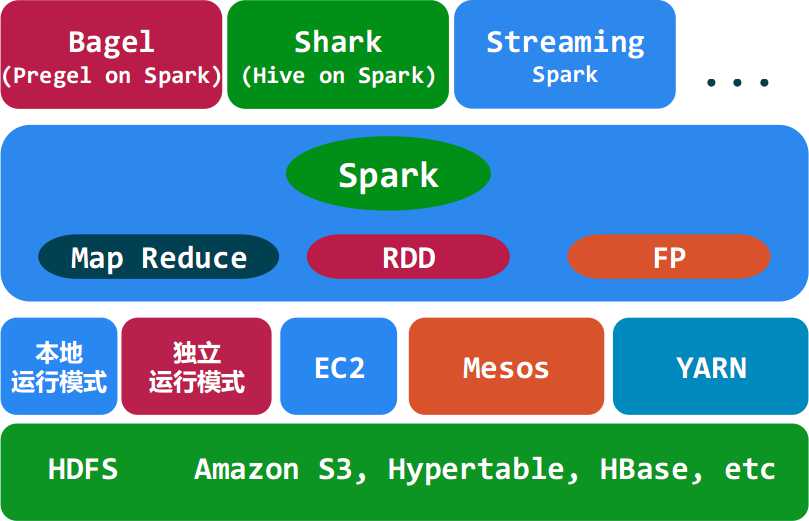
Spark与Hadoop的对比
- Spark的中间数据放到内存中,对于迭代运算效率更高。
Spark更适合于迭代运算比较多的ML和DM运算。因为在Spark里面,有RDD的抽象概念。
- Spark比Hadoop更通用
Spark提供的数据集操作类型有很多种,不像Hadoop只提供了Map和Reduce两种操作。比如map, filter, flatMap, sample, groupByKey, reduceByKey, union, join, cogroup, mapValues, sort,partionBy等多种操作类型,Spark把这些操作称为Transformations。同时还提供Count, collect, reduce, lookup, save等多种actions操作。
这些多种多样的数据集操作类型,给给开发上层应用的用户提供了方便。各个处理节点之间的通信模型不再像Hadoop那样就是唯一的Data Shuffle一种模式。用户可以命名,物化,控制中间结果的存储、分区等。可以说编程模型比Hadoop更灵活。
不过由于RDD的特性,Spark不适用那种异步细粒度更新状态的应用,例如web服务的存储或者是增量的web爬虫和索引。就是对于那种增量修改的应用模型不适合。
- 容错性。
在分布式数据集计算时通过checkpoint来实现容错,而checkpoint有两种方式,一个是checkpoint data,一个是logging the updates。用户可以控制采用哪种方式来实现容错。
- 可用性。
Spark通过提供丰富的Scala, Java,Python API及交互式Shell来提高可用性。
Spark与Hadoop的结合
Spark可以直接对HDFS进行数据的读写,同样支持Spark on YARN。Spark可以与MapReduce运行于同集群中,共享存储资源与计算,数据仓库Shark实现上借用Hive,几乎与Hive完全兼容。
Spark的适用场景
Spark是基于内存的迭代计算框架,适用于需要多次操作特定数据集的应用场合。需要反复操作的次数越多,所需读取的数据量越大,受益越大,数据量小但是计算密集度较大的场合,受益就相对较小(大数据库架构中这是是否考虑使用Spark的重要因素)
由于RDD的特性,Spark不适用那种异步细粒度更新状态的应用,例如web服务的存储或者是增量的web爬虫和索引。就是对于那种增量修改的应用模型不适合。
总的来说Spark的适用面比较广泛且比较通用。
运行模式
本地模式
Standalone模式
Mesoes模式
yarn模式
Spark生态系统
Shark ( Hive on Spark): Shark基本上就是在Spark的框架基础上提供和Hive一样的H iveQL命令接口,为了最大程度的保持和Hive的兼容性,Shark使用了Hive的API来实现query Parsing和 Logic Plan generation,最后的PhysicalPlan execution阶段用Spark代替Hadoop MapReduce。通过配置Shark参数,Shark可以自动在内存中缓存特定的RDD,实现数据重用,进而加快特定数据集的检索。同时,Shark通过UDF用户自定义函数实现特定的数据分析学习算法,使得SQL数据查询和运算分析能结合在一起,最大化RDD的重复使用。
Spark streaming: 构建在Spark上处理Stream数据的框架,基本的原理是将Stream数据分成小的时间片断(几秒),以类似batch批量处理的方式来处理这小部分数据。Spark Streaming构建在Spark上,一方面是因为Spark的低延迟执行引擎(100ms+)可以用于实时计算,另一方面相比基于Record的其它处理框架(如Storm),RDD数据集更容易做高效的容错处理。此外小批量处理的方式使得它可以同时兼容批量和实时数据处理的逻辑和算法。方便了一些需要历史数据和实时数据联合分析的特定应用场合。
Bagel: Pregel on Spark,可以用Spark进行图计算,这是个非常有用的小项目。Bagel自带了一个例子,实现了Google的PageRank算法。
下一篇:问题:
1.Spark的核心是什么?
2.RDD在内存不足时,是怎么处理的?
3.如何创建RDD,有几种方式
4.Spark编程支持几种语言
5.是否能够写出一个Driver程序
spark科普的更多相关文章
- 科普Spark,Spark核心是什么,如何使用Spark(1)
科普Spark,Spark是什么,如何使用Spark(1)转自:http://www.aboutyun.com/thread-6849-1-1.html 阅读本文章可以带着下面问题:1.Spark基于 ...
- 【转】科普Spark,Spark是什么,如何使用Spark
本博文是转自如下链接,为了方便自己查阅学习和他人交流.感谢原博主的提供! http://www.aboutyun.com/thread-6849-1-1.html http://www.aboutyu ...
- 科普Spark,Spark是什么,如何使用Spark
科普Spark,Spark是什么,如何使用Spark 1.Spark基于什么算法的分布式计算(很简单) 2.Spark与MapReduce不同在什么地方 3.Spark为什么比Hadoop灵活 4.S ...
- 【科普杂谈】一文看懂大数据的技术生态圈,Hadoop,hive,spark都有了
大数据本身是个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞生的.你可以把它比作一个厨房所以需要的各种工具.锅碗瓢盆,各有各的用处,互相之间又有重合.你可 ...
- Apache Spark是什么?
简单地说, Spark是发源于美国加州大学伯克利分校AMPLab的大数据分析平台,它立足于内存计算,从多迭代批量处理出发,兼顾数据仓库. 流处理和图计算等多种计算范式,是大数据系统领域的全栈计算平台. ...
- zhihu spark集群,书籍,论文
spark集群中的节点可以只处理自身独立数据库里的数据,然后汇总吗? 修改 我将spark搭建在两台机器上,其中一台既是master又是slave,另一台是slave,两台机器上均装有独立的mongo ...
- 大数据技术生态圈形象比喻(Hadoop、Hive、Spark 关系)
[摘要] 知乎上一篇很不错的科普文章,介绍大数据技术生态圈(Hadoop.Hive.Spark )的关系. 链接地址:https://www.zhihu.com/question/27974418 [ ...
- spark work目录处理 And HDFS空间都去哪了?
1.说在前面 过完今天就放假回家了(挺高兴),于是提前检查了下个服务集群的状况,一切良好.正在我想着回家的时候突然发现手机上一连串的告警,spark任务执行失败,spark空间不足.我的心突然颤抖了一 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(九)安装kafka_2.11-1.1.0
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
随机推荐
- 软件工程实践2018第六次作业——现场UML作图
团队信息 学号 姓名 博客链接 124 王彬(组长) 点击这里 206 赵畅 点击这里 215 胡展瑞 点击这里 320 李恒达 点击这里 131 佘岳昕 点击这里 431 王源 点击这里 206 陈 ...
- 使用Fabric自动化你的任务
Fabric是一个Python库,可以通过SSH在多个host上批量执行任务.你可以编写任务脚本,然后通过Fabric在本地就可以使用SSH在大量远程服务器上自动运行.这些功能非常适合应用的自动化部署 ...
- c++浅拷贝与深拷贝(LeetCode669)
之前上C++/C#课上老师讲过这个问题,只不过当时主要是跟着老师的节奏与情形,从理论上基本了解了其原理.不过当自己写代码的时候,还是遇到了这个非常坑的问题.因此再来分析一下. 今天第一次做LeetCo ...
- PHP导出sql文件
发现自己之前写的php导出sql数据为Excel文件在导出一些数据的时候出现了精度的问题,比如导出身份证号的时候会把后面变成0000.暂时先把这个问题留下,有空去看看到底是什么问题. 写了一个导出sq ...
- UVAlive5135_Mining Your Own Business
好题.给一个无向图,求最少染黑多少个点后,使得任意删除一个点,每一个点都有与至少一个黑点联通. 一开始的确不知道做.看白书,对于一个联通分量,如果它有两个或以上的割点,那么这个分量中间的任何一个点都是 ...
- Spring、MyBatis和SpringMVC整合的jar包下载
spring mvc的jar包下载:http://repo.springsource.org/libs-release-local/org/springframework/spring/我下载的5.0 ...
- js模块化的总结
从前端打包的历史谈起 在很长的一段前端历史里,是不存在打包这个说法的.那个时候页面基本是纯静态的或者服务端输出的, 没有 AJAX,也没有 jQuery.Google 推出 Gmail 的时候(200 ...
- 【BZOJ4774】修路(动态规划,斯坦纳树)
[BZOJ4774]修路(动态规划,斯坦纳树) 题面 BZOJ 题解 先讲怎么求解最小斯坦纳树. 先明白什么是斯坦纳树. 斯坦纳树可以认为是最小生成树的一般情况.最小生成树是把所有给定点都要加入到联通 ...
- FourAndSix: 2.01靶机入侵
0x01 前言 FourAndSix2是易受攻击的一个靶机,主要任务是通过入侵进入到目标靶机系统然后提权,并在root目录中并读取flag.tx信息 FourAndSix2.镜像下载地址: htt ...
- cgroup限制内存
cgroup有个memory子系统,有两组对应的文件,一组带 memsw ,另一组不带. # docker ps -a # cd /sys/fs/cgroup/memory/docker/4b5619 ...