MySQL-事务隔离级别设置
加锁研究:http://www.cnblogs.com/JohnABC/p/4377529.html
先了解下 第一类丢失更新、脏读、不可重复读、幻读、第二类丢失更新
第一类丢失更新
撤销一个事务时, 把其他事务已经提交的更新数据覆盖(此情况在事务中不可能出现, 因为一个事务中修改时此记录已加锁, 必须等待此事务完成后另一个事务才可以继续UPDATE)
脏读
一个事务读到另一个事务,尚未提交的修改,就是脏读。这里所谓的修改,除了Update操作,不要忘了,还包括Insert和Delete操作。脏读的后果:如果后一个事务回滚,那么它所做的修改,统统都会被撤销。前一个事务读到的数据,就是垃圾数据。
举个例子:预订房间。
有一张Reservation表,往表中插入一条记录,来订购一个房间。
事务1:在Reservation表中插入一条记录,用于预订99号房间。
事务2:查询,尚未预定的房间列表,因为99号房间,已经被事务1预订。所以不在列表中。
事务1:信用卡付款。由于付款失败,导致整个事务回滚。 所以插入到Reservation 表中的记录并不置为持久(即它将被删除)。
现在99号房间则为可用。
所以,事务2所用的是一个无效的房间列表,因为99号房间,已经可用。如果它是最后一个没有被预定的房间,那么这将是一个严重的失误。
注:脏读的后果很严重。
再例如
| 时间 | 取款事务 | 支票转账事务 |
| T1 | 开始事务 | |
| T2 | 开始事务 | |
| T3 | 查询账户余额为1000元 | |
| T4 | ||
| T5 | 取出100,把存款余额改为900元 | |
| T6 | 查询账户的存款余额为900元(脏读) | |
| T7 | 撤销该事务,把存款余额恢复为1000元 | |
| T8 | 汇入100元,把存款余额改为1000元 | |
| T9 | 提交事务 |
不可重复读
在同一个事务中,再次读取数据时【就是你的select操作】,所读取的数据,和第1次读取的数据,不一样了。就是不可重复读。
举个例子:
事务1:查询有双人床房间。99号房间,有双人床。
事务2:将99号房间,改成单人床房间。
事务1:再次执行查询,请求所有双人床房间列表,99号房间不再列表中了。也就是说,事务1,可以看到其他事务所做的修改。
在不可重复读,里面,可以看到其他事务所做的修改,而导致2次的查询结果不再一样了。这里的修改,是提交过的。也可以是没有提交的,这种情况同时也是脏读。
如果,数据库系统的隔离级别。允许,不可重复读。那么你启动一个事务,并做一个select查询操作。查询到的数据,就有可能,和你第2次,3次...n次,查询到的数据不一样。一般情况下,你只会做一次,select
查询,并以这一次的查询数据,作为后续计算的基础。因为允许出现,不可重复读。那么任何时候,查询到的数据,都有可能被其他事务更新,查询的结果将是不确定的。
注:如果允许,不可重复读,你的查询结果,将是不确定的。一个不确定的结果,你能容忍吗?
幻读
事务1读取指定的where子句所返回的一些行。然后,事务2插入一个新行,这个新行也满足事务1使用的查询where子句。然后事务1再次使用相同的查询读取行,但是现在它看到了事务2刚插入的行。这个行被称为幻象,因为对事务1来说,这一行的出现是不可思议的。
举个例子:
事务1:请求没有预定的,双人床房间列表。
事务2:向Reservation表中插入一个新纪录,以预订99号房间,并提交。
事务1:再次请求有双人床的未预定的房间列表,99号房间,不再位于列表中。
注:幻读,针对的是,Insert操作。如果事务2,插入的记录,没有提交。那么同时也是脏读。
第二类丢失更新
这是不可重复读中的特例, 一个事务覆盖另一个事务已提交的更新数据(以下会出现此情况)
| 时间 | 取款事务 | 支票转账事务 |
| T1 | 开始事务 | |
| T2 | 开始事务 | |
| T3 | 查询账户余额为1000元 | |
| T4 | 查询账户余额为1000元 | |
| T5 | 取出100,把存款余额改为900元 | |
| T6 | 提交事务 | |
| T7 | 汇入100元,把存款余额改为1100元 | |
| T8 | 提交事务 |
| No | 事务1 | 事务2 | 备注 |
| 1 | select * from tb2 where id=1; <NO> id name name2 1 1 a a |
||
| 2 |
update tb2 set name2='b' where id=1; 1 Rows updated! |
||
| 3 |
select * from tb2 where id=1; <NO> id name name2 1 1 a a |
很好:没有出现脏读 | |
| 4 | commit | ||
| 5 |
select * from tb2 where id=1; <NO> id name name2 1 1 a a |
很好:没有出现不可重复读 | |
| 6 |
update tb2 set name='a1' where id=1; 1 Rows updated! |
||
| 7 |
select * from tb2 where id=1; <NO> id name name2 1 1 a1 b |
糟糕:name2的值怎么跟以前不一样了。(即出现了不可重复读) | |
| 8 | commit |
应该明白 什么状况对什么加什么锁(可以分别思考和测试每个隔离级别下脏读、不可重复读、幻读的出现及不出现原因)
读完下面的内容可以回头来看此段:
不可重复读错误处理:通常可以用 set tran isolation level repeatable read 来设置隔离级别, 这样事务 A 在两次读取表T中的数据时, 事务B如果企图更改表T中的数据(细节到事务A读取数据)时, 就会被阻塞, 直到事务A提交! 这样就保证了, 事务A两次读取的数据的一致性
幻读错误处理:如果设置 repeatable read, 虽然可以防止事务B对数据进行修改, 但是事务B却可以向表T中插入新的数据, 如何防止这个问题, 我们可以考虑设置最高的事务隔离级别 set tran isolation level serializable, 于是乎, 事务B就只能乖乖的等待事务A的提交, 才能向表T中插入新的数据, 从而避免了幻读
不可重复读与幻读的区别:
脏读的重点是读另一个事务未提交的数据(假若那个事务RollBack, 则这数据就是无效的):某个事务已更新一份数据, 另一个事务在此时读取了同一份数据, 由于某些原因, 前一个RollBack了操作, 则后一个事务所读取的数据就会是不正确的
不可重复读的重点是修改: 同样的条件, 你读取过的数据, 再次读取出来发现值不一样了
幻读的重点在于新增或者删除: 同样的条件, 第1次和第2次读出来的记录数不一样
当然, 从总的结果来看, 似乎两者都表现为两次读取的结果不一致, 但如果你从控制的角度来看, 两者的区别就比较大, 对于不可重复读, 只需要锁住满足条件的记录, 对于幻读, 要锁住满足条件及其相近的记录
rollback;或者commit;都会退出事务!
更新记录的时候需要锁!
InnoDB中 只要此行在别的事务中产生了锁 本事务中就不允许进行修改 只能阻塞 等待别的事务提交
一般设置为Read Committed, 并且利用悲观锁(SELECT ... FOR UPDATE)或乐观锁(SET NUM=NUM+1, 而不是计算后再插入, 避免并发)来处理特殊情况
SQL标准定义了4类隔离级别,包括了一些具体规则,用来限定事务内外的哪些改变是可见的,哪些是不可见的。低级别的隔离级一般支持更高的并发处理,并拥有更低的系统开销。
Read Uncommitted(读取未提交内容)
在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少。读取未提交的数据,也被称之为脏读(Dirty Read)。
Read Committed(读取提交内容)
这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)。它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变。这种隔离级别
也支持所谓的不可重复读(Nonrepeatable
Read),因为同一事务的其他实例在该实例处理其间可能会有新的commit,所以同一select可能返回不同结果。
Repeatable Read(可重读)
这是MySQL的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。不过理论上,这会导致另一个棘手的问题:幻读
(Phantom
Read)。简单的说,幻读指当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影”
行。InnoDB和Falcon存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency
Control)机制解决了该问题。
Serializable(可串行化)
这是最高的隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争。只要操作产生了锁,就不允许其他事务读取和修改!(可以看看加锁处理分析http://hedengcheng.com/?p=771或者百度网盘http://pan.baidu.com/s/1mgN00Og)
这四种隔离级别采取不同的锁类型来实现,若读取的是同一个数据的话,就容易发生问题。例如:
脏读(Drity Read):某个事务已更新一份数据,另一个事务在此时读取了同一份数据,由于某些原因,前一个RollBack了操作,则后一个事务所读取的数据就会是不正确的。
不可重复读(Non-repeatable read):在一个事务的两次查询之中数据不一致,这可能是两次查询过程中间插入了一个事务更新的原有的数据。
幻读(Phantom Read):在一个事务的两次查询中数据笔数不一致,例如有一个事务查询了几列(Row)数据,而另一个事务却在此时插入了新的几列数据,先前的事务在接下来的查询中,就会发现有几列数据是它先前所没有的。
在MySQL中,实现了这四种隔离级别,分别有可能产生问题如下所示:

| 隔离级别 | 是否出现第一类丢失更新 | 是否出现脏读 | 是否出现不可重复读 | 是否出现幻读 | 是否出现第二类丢失更新 |
| Serializable | 否 | 否 | 否 | 否 | 否 |
| Repeatable Read | 否 | 否 | 否 | 是 | 否 |
| Read Commited | 否 | 否 | 是 | 是 | 是 |
| Read Uncommited | 否 | 是 | 是 | 是 | 是 |
下面,将利用MySQL的客户端程序,分别测试几种隔离级别。测试数据库为test,表为tx;表结构:
| id | int |
|
num |
int |
两个命令行客户端分别为A,B;不断改变A的隔离级别,在B端修改数据。
SET [SESSION|GLOBAL] TRANSACTION ISOLATION LEVEL [READ UNCOMMITTED|READ COMMITTED|REPEATABLE READ|SERIALIZABLE]
(一)、将A的隔离级别设置为read uncommitted(未提交读)
在B未更新数据之前:
客户端A: 
B更新数据:
客户端B:

客户端A:

经过上面的实验可以得出结论,事务B更新了一条记录,但是没有提交,此时事务A可以查询出未提交记录。造成脏读现象。未提交读是最低的隔离级别。
(二)、将客户端A的事务隔离级别设置为read committed(已提交读)
在B未更新数据之前:
客户端A:

B更新数据:
客户端B:

客户端A:

经过上面的实验可以得出结论,已提交读隔离级别解决了脏读的问题,但是出现了不可重复读的问题,即事务A在两次查询的数据不一致,因为在两次查询之间事务B更新了一条数据。已提交读只允许读取已提交的记录,但不要求可重复读。
(三)、将A的隔离级别设置为repeatable read(可重复读)
在B未更新数据之前:

B更新数据:
客户端B:

客户端A:

B插入数据:
客户端B:

客户端A:

由以上的实验可以得出结论,可重复读隔离级别只允许读取已提交记录,而且在一个事务两次读取一个记录期间,其他事务部的更新该记录。但该事务不要求与其他 事务可串行化。例如,当一个事务可以找到由一个已提交事务更新的记录,但是可能产生幻读问题(注意是可能,因为数据库对隔离级别的实现有所差别)。像以上 的实验,就没有出现数据幻读的问题。
(四)、将A的隔离级别设置为 可串行化 (Serializable)
A端打开事务,B端插入一条记录
事务A端:

事务B端:

因为此时事务A的隔离级别设置为serializable,开始事务后,并没有提交,所以事务B只能等待。
事务A提交事务:
事务A端

事务B端

serializable完全锁定字段,若一个事务来查询同一份数据就必须等待,直到前一个事务完成并解除锁定为止 。是完整的隔离级别,会锁定对应的数据表格,因而会有效率的问题。
利用悲观锁
| 时间 | 取款事务 | 支票转账事务 |
| T1 | 开始事务 | |
| T2 | 开始事务 | |
| T3 | select * from ACCOUNTS where ID = 1 for update; 查询账户余额为1000元;这条记录被锁定。 |
|
| T4 | select * from ACCOUNTS where ID = 1 for update; 执行该语句时,事务停下来等待取款事务解除对这条记录的锁定。 |
|
| T5 | 取出100,把存款余额改为900元 | |
| T6 | 提交事务 | |
| T7 | 事务恢复运行,查询结果显示存款余额为900.这条记录被锁定。 | |
| T8 | 汇入100元,把存款余额改为1000元。 | |
| T9 | 提交事务 |
用图展示隔离级别及对应缺陷:
READ UNCOMMITTED 在该隔离级别下,所有事务都可以看到其它未提交事务的执行结果。如下图所示: 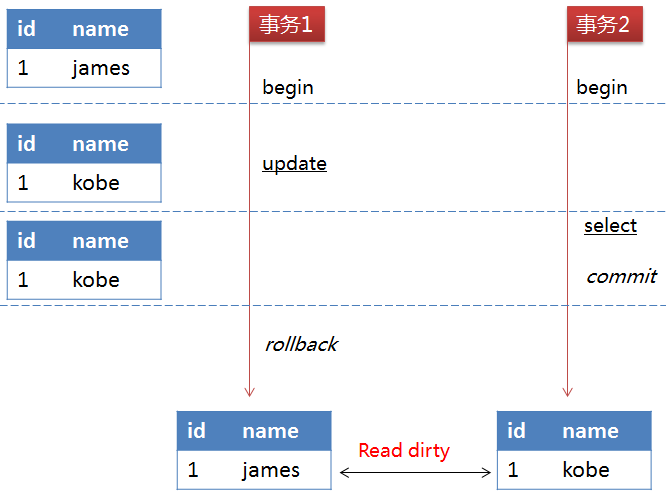
缺陷:事务2查询到的数据是事务1中修改但未提交的数据,但因为事务1回滚了数据,所以事务2查询的数据是不正确的,因此出现了脏读的问题。
READ COMMITTED 在该隔离级别下,一个事务从开始到提交之前对数据所做的改变对其它事务是不可见的,这样就解决在READ-UNCOMMITTED级别下的脏读问题。但如果一个事务在执行过程中,其它事务的提交对该事物中的数据发生改变,那么该事务中的一个查询语句在两次执行过程中会返回不一样的结果。如下图所示:
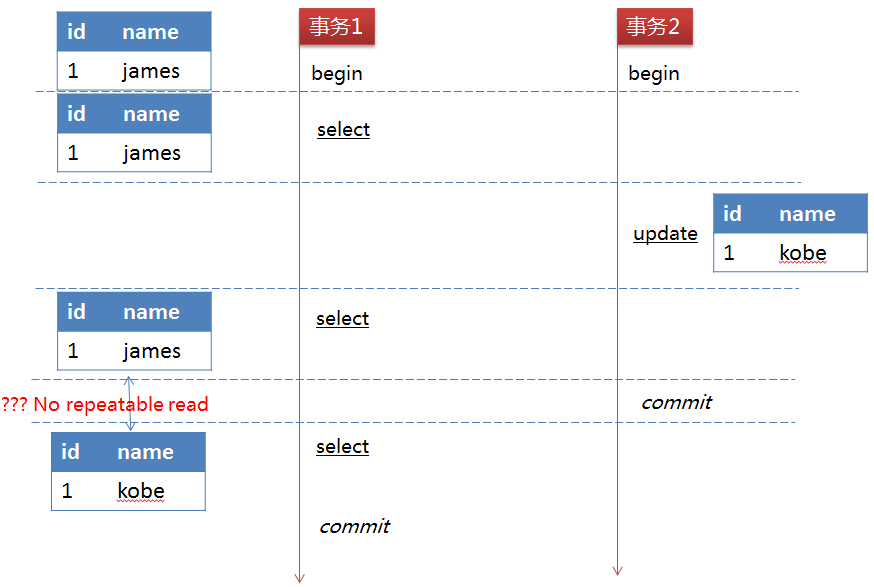
缺陷:事务2执行update语句但未提交前,事务1的前两个select操作返回结果是相同的。但事务2执行commit操作后,事务1的第三个select操作就读取到事务2对数据的改变,导致与前两次select操作返回不同的数据,因此出现了不可重复读的问题。
REPEATABLE READ 这是MySQL的默认事务隔离级别,能确保事务在并发读取数据时会看到同样的数据行,解决了READ-COMMITTED隔离级别下的不可重复读问题。mysql的InnoDB存储引擎通过多版本并发控制(Multi_Version Concurrency Control, MVCC)机制来解决该问题。在该机制下,事务每开启一个实例,都会分配一个版本号给它,如果读取的数据行正在被其它事务执行DELETE或UPDATE操作(即该行上有排他锁),这时该事物的读取操作不会等待行上的锁释放,而是根据版本号去读取行的快照数据(记录在undo log中),这样,事务中的查询操作返回的都是同一版本下的数据,解决了不可重复读问题。其原理如下图所示:
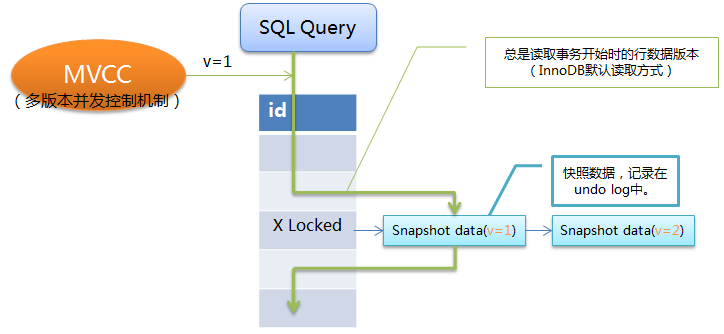
缺陷:虽然该隔离级别下解决了不可重复读问题,但理论上会导致另一个问题:幻读(Phantom Read)。正如上面所讲,一个事务在执行过程中,另一个事物对已有数据行的更改,MVCC机制可保障该事物读取到的原有数据行的内容相同,但并不能阻止另一个事务插入新的数据行,这就会导致该事物中凭空多出数据行,像出现了幻读一样,这便是幻读问题。如下图所示:
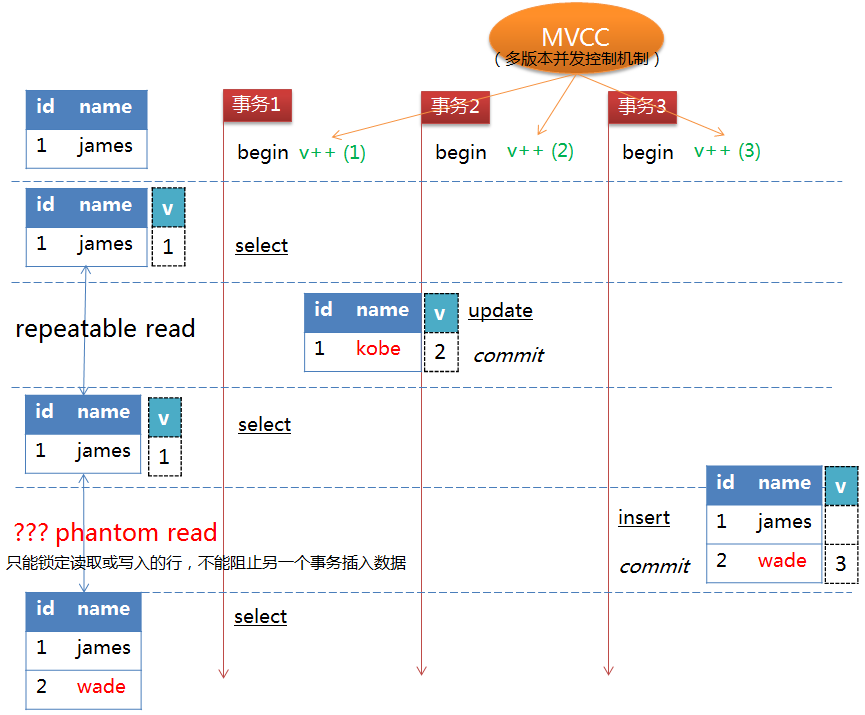
缺陷:事务2对id=1的行内容进行了修改并且执行了commit操作,事务1中的第二个select操作在MVCC机制的作用下返回的仍是v=1的数据。但事务3执行了insert操作,事务1第三次执行select操作时便返回了id=2的数据行,与前两次的select操作返回的值不一样。需要说明的是,REPEATABLE-READ隔离级别下的幻读问题是SQL标准定义下理论上会导致的问题,MySQL的InnoDB存储引擎在该隔离级别下,采用了Next-Key Locking锁机制避免了幻读问题。Next-Key Locking锁机制将在后面的锁章节中讲到。
SERIALIZABLE 这是事务的最高隔离级别,通过强制事务排序,使之不可能相互冲突,就是在每个读的数据行加上共享锁来实现。在该隔离级别下,可以解决前面出现的脏读、不可重复读和幻读问题,但也会导致大量的超时和锁竞争现象,一般不推荐使用。
转自:http://xm-king.iteye.com/blog/770721
参考:http://blog.csdn.net/u013235478/article/details/50625602
更多测试:
http://blog.csdn.net/wangsifu2009/article/details/6715120
http://www.2cto.com/database/201412/359238.html
MySQL-事务隔离级别设置的更多相关文章
- mysql事务隔离级别设置
设置innodb的事务级别方法是:set 作用域 transaction isolation level 事务隔离级别: 若没有输入作用域直接修改transaction isolation,显示修改成 ...
- mysql事务隔离级别与设置
mysql数据库,当且仅当引擎是InnoDB,才支持事务: 1.隔离级别 事务的隔离级别分为:未提交读(read uncommitted).已提交读(read committed).可重复读(repe ...
- MySQL事务隔离级别详解
原文地址:http://xm-king.iteye.com/blog/770721 SQL标准定义了4类隔离级别,包括了一些具体规则,用来限定事务内外的哪些改变是可见的,哪些是不可见的.低级别的隔离级 ...
- Mysql事务隔离级别学习
这篇文章主要谈谈Mysql事务隔离级别的区别,以及自己的一些感受. 自己一直以来没搞懂“可重复读”和可提交读“两者之间的区别,通过此次的实践,清楚了两者之间的区别.废话不说,先上图看看这几个事务隔离级 ...
- 五分钟搞清楚MySQL事务隔离级别
好久没碰数据库了,只是想起自己当时在搞数据库的时候在事务隔离级别这块老是卡,似懂非懂的.现在想把这块整理出来,尽量用最简洁的语言描述出来,供新人参考. 首先创建一个表account.创建表的过程略过( ...
- MySQL事务隔离级别详解(转)
原文: http://xm-king.iteye.com/blog/770721 SQL标准对事务定义了4种隔离级别,包括了一些具体规则,用来限定事务内外的哪些改变是可见的,哪些是不可见的.低级别的隔 ...
- 查询mysql事务隔离级别
查询mysql事务隔离级别 查询mysql事务隔离级别 分类: DB2011-11-26 13:12 2517人阅读 评论(0) 收藏 举报 mysqlsessionjava 1.查看当前会话隔离 ...
- Mysql事务-隔离级别
MYSQL事务-隔离级别 事务是什么? 事务简言之就是一组SQL执行要么全部成功,要么全部失败.MYSQL的事务在存储引擎层实现. 事务都有ACID特性: 原子性(Atomicity):一个事务必须被 ...
- MySQL事务隔离级别(二)
搞清楚MySQL事务隔离级别 首先创建一个表 account.创建表的过程略过(由于 InnoDB 存储引擎支持事务,所以将表的存储引擎设置为 InnoDB).表的结构如下: 为了说明问题,我们打开两 ...
- MySQL事务隔离级别(一)
本文实验的测试环境:Windows 10+cmd+MySQL5.6.36+InnoDB 一.事务的基本要素(ACID) 1.原子性(Atomicity):事务开始后所有操作,要么全部做完,要么全部不做 ...
随机推荐
- 基于Java IO 序列化方案的memcached-session-manager多memcached节点配置
在公司项目里想要在前端通过nginx将请求负载均衡,而后台的几组tomcat的session通过memcached(non-sticky模式)进行统一管理,这几组tomcat部署的web app是同一 ...
- Git 学习(三)本地仓库操作——git add & commit
Git 学习(三)本地仓库操作——git add & commit Git 和其他版本控制系统如SVN的一个不同之处就是有暂存区的概念.这在上文已有提及,本文具体说明什么是工作区及暂存区,以及 ...
- 支持按行号区域文本选择的NotePad++插件开发
近期发现NotePad++不支持按行号区间的文本复制,就想自己动手开发一个NotePad++插件,支持输入起始行号和结束行号,然后复制该区域的文本到新文档或者拷贝到系统剪切板,方便文本的操作. 效果例 ...
- file not found app文件
昨天svn迁移.然后又一次check out之后编译遇到这个错误. Ld Build/Products/Debug-iphonesimulator/wiseCloudCrmTests.xctest/w ...
- WIN32 SDK对COM的支持
- Drupal 通过API动态的加入样式文件
前面几篇文章中讲到关于样式的载入方式.已经了解到能够通过 theme.info 载入样式文件,但都须要更新缓存才干够使用.因些这样子没有办法动态的载入一些样式文件,在DP中提供了两个API操作样式文件 ...
- Memcached 的一些用法
public interface ICache { object Get(string key); /// <summary> /// 根据 key 从缓存中读取数据 /// </s ...
- [算法][LeetCode]Spiral Matrix
题目要求 Given a matrix of m x n elements (m rows, n columns), return all elements of the matrix in spir ...
- uni-app 生命周期
生命周期分为:页面生命周期和应用生命周期 生命周期可参考:uni-app官方API 注意平台支持,仅某个平台支持会显示,5+App是超HTML5+的App方案. 例如分享:只有小程序支持.这时我们就要 ...
- Idea Spring-boot gradle lombok
1:build.gradle compile("org.projectlombok:lombok:1.16.16") 2:idea安装lombok插件 3:设置 4:重启