ceph 分布式存储安装
[root@localhost ~]# rm -rf /etc/yum.repos.d/*.repo
下载阿里云的base源
[root@localhost ~]# wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
[root@localhost ~]# wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
[root@localhost ~]# sed -i '/aliyuncs/d' /etc/yum.repos.d/CentOS-Base.repo
[root@localhost ~]# sed -i '/aliyuncs/d' /etc/yum.repos.d/epel.repo
[root@localhost ~]# sed -i 's/$releasever/7.3.1611/g' /etc/yum.repos.d/CentOS-Base.repo
[root@localhost ~]# vi /etc/yum.repos.d/ceph.repo
添加
[ceph]
name=ceph
baseurl=http://mirrors.163.com/ceph/rpm-jewel/el7/x86_64/
gpgcheck=
[ceph-noarch]
name=cephnoarch
baseurl=http://mirrors.163.com/ceph/rpm-jewel/el7/noarch/
gpgcheck=
进行yum的makecache
[root@localhost ~]# yum makecache
[root@admin ceph-cluster]# yum -y install ceph-deploy
1.在管理节点上,进入刚创建的放置配置文件的目录,用 ceph-deploy 执行如下步骤
mkdir /opt/cluster-ceph
cd /opt/cluster-ceph
ceph-deploy new monitor1 monitor2 monitor3
2. 把 Ceph 配置文件里的默认副本数从 3 改成 2 ,这样只有两个 OSD 也可以达到 active + clean 状态。
把下面这行加入 [global] 段:
osd_pool_default_size = 2
3. 如果你有多个网卡,可以把 public network 写入 Ceph 配置文件的 [global] 段下
public network = {ip-address}/{netmask}
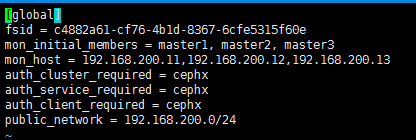
[global]
fsid = 251e2c73---8f3b-7377341d60b1
mon_initial_members = master1, master2, master3
mon_host = 172.16.8.185,172.16.8.186,172.16.8.187
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
public_network = 172.16.8.0/
osd_pool_default_size =
mon_pg_warn_max_per_osd =
osd pool default pg num =
osd pool default pgp num =
mon clock drift allowed =
mon clock drift warn backoff =
4.安装 Ceph
方法一
[root@admin ceph-cluster]# ceph-deploy install monitor1 monitor2 monitor3 osd1 osd2 admin
//
如果下载不了
方法二
下载ceph的相关rpm到本地
[root@localhost ~]# yum install --downloadonly --downloaddir=/tmp/ceph ceph
在每台主机上安装ceph
[root@localhost ~]# yum localinstall -C -y --disablerepo=* /tmp/ceph/*.rpm
方法三
# 替换 ceph 源 为 163 源
sed -i 's/download\.ceph\.com/mirrors\.163\.com\/ceph/g' /etc/yum.repos.d/ceph.repo
yum -y install ceph ceph-radosgw
//
5. 配置初始 monitor(s)、并收集所有密钥:
# 请务必在 ceph-cluster 目录下
[root@admin ceph-cluster]# ceph-deploy mon create-initial
[ceph_deploy.gatherkeys][INFO ] Storing ceph.client.admin.keyring
[ceph_deploy.gatherkeys][INFO ] Storing ceph.bootstrap-mds.keyring
[ceph_deploy.gatherkeys][INFO ] Storing ceph.bootstrap-mgr.keyring
[ceph_deploy.gatherkeys][INFO ] keyring 'ceph.mon.keyring' already exists
[ceph_deploy.gatherkeys][INFO ] Storing ceph.bootstrap-osd.keyring
[ceph_deploy.gatherkeys][INFO ] Storing ceph.bootstrap-rgw.keyring
[ceph_deploy.gatherkeys][INFO ] Destroy temp directory /tmp/tmpJ9K9Z2
6. 初始化 ceph.osd 节点
创建存储空间
[root@osd1 ~]# mkdir -p /opt/ceph-osd
[root@osd1 ~]# chown ceph.ceph /opt/ceph-osd/ -R
[root@osd2 ~]# mkdir -p /opt/ceph-osd
[root@osd2 ~]# chown ceph.ceph /opt/ceph-osd/ -R
创建OSD:
[root@admin ceph-cluster]# ceph-deploy osd prepare osd1:/opt/ceph-osd osd2:/opt/ceph-osd
激活 OSD
[root@admin ceph-cluster]# ceph-deploy osd activate osd1:/opt/ceph-osd osd2:/opt/ceph-osd
用 ceph-deploy 把配置文件和 admin 密钥拷贝到管理节点和 Ceph 节点,这样你每次执行 Ceph 命令行时就无需指定 monitor 地址和 ceph.client.admin.keyring 了
[root@admin ceph-cluster]# ceph-deploy admin monitor1 monitor2 monitor3 osd1 osd2 admin
确保你对 ceph.client.admin.keyring 有正确的操作权限。
chmod +r /etc/ceph/ceph.client.admin.keyring (所有机器)
如果配置文件更改,需要同步配置文件到所有节点
[root@admin ceph-cluster]# ceph-deploy --overwrite-conf admin monitor1 monitor2 monitor3 osd1 osd2 admin
7.检查集群的健康状况。
[root@admin ceph-cluster]# ceph health
查看状态
[root@admin ceph-cluster]# ceph -s
cluster 33411039-d7cb-442d-be2a-77fb9e90eb0a
health HEALTH_OK
monmap e1: 3 mons at {monitor1=192.168.20.223:6789/0,monitor2=192.168.20.224:6789/0,monitor3=192.168.20.225:6789/0}
election epoch 6, quorum 0,1,2 monitor1,monitor2,monitor3
osdmap e12: 2 osds: 2 up, 2 in
flags sortbitwise,require_jewel_osds
pgmap v26: 64 pgs, 1 pools, 0 bytes data, 0 objects
26445 MB used, 63614 MB / 90060 MB avail
64 active+clean
8.查看osd tree
[root@admin ceph-cluster]# ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 0.08578 root default
-2 0.04289 host osd1
0 0.04289 osd.0 up 1.00000 1.00000
-3 0.04289 host osd2
1 0.04289 osd.1 up 1.00000 1.00000
monitor 进程为 /usr/bin/ceph-mon -f --cluster ceph --id monitor1 --setuser ceph --setgroup ceph
systemctl start ceph-mon.target
systemctl enable ceph-mon.target
systemctl start ceph-osd.target
systemctl enable ceph-osd.target
9.扩展集群(扩容)
增加一个 元数据osd
[root@admin ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub root@osd3
[root@osd3 ~]# rm /etc/yum.repos.d/* -rf
[root@admin ~]# scp /etc/yum.repos.d/*.repo root@osd3:/etc/yum.repos.d/
[root@osd3 ~]# yum makecache
[root@osd3 ~]# yum -y update && yum -y install ceph-deploy
[root@osd3 ~]# yum localinstall -C -y --disablerepo=* /tmp/ceph/*.rpm
[root@osd3 ~]# mkdir -p /opt/ceph-osd
[root@osd3 ~]# chown ceph.ceph /opt/ceph-osd/ -R
[root@admin ~]# ceph-deploy admin osd3
使用ceph-deploy 节点准备 OSD
[root@admin ceph-cluster]# ceph-deploy osd prepare osd3:/opt/ceph-osd
激活 OSD
[root@admin ceph-cluster]# ceph-deploy osd activate osd3:/opt/ceph-osd
##注意: ntp 时间一定要同步
检查Ceph monitor仲裁状态
[root@admin ceph-cluster]# ceph quorum_status --format json-pretty
{
"election_epoch": ,
"quorum": [
,
,
],
"quorum_names": [
"monitor1",
"monitor2",
"monitor3"
],
"quorum_leader_name": "monitor1",
"monmap": {
"epoch": ,
"fsid": "33411039-d7cb-442d-be2a-77fb9e90eb0a",
"modified": "2017-12-21 17:28:21.134905",
"created": "2017-12-21 17:28:21.134905",
"mons": [
{
"rank": ,
"name": "monitor1",
"addr": "192.168.20.223:6789\/0"
},
{
"rank": ,
"name": "monitor2",
"addr": "192.168.20.224:6789\/0"
},
{
"rank": ,
"name": "monitor3",
"addr": "192.168.20.225:6789\/0"
}
]
}
}
CEPH 块设备
块是一个字节序列(例如,一个 512 字节的数据块)。基于块的存储接口是最常见的存储数据方法,它们基于旋转介质,像硬盘、 CD 、软盘、甚至传统的 9 磁道磁带。无处不在的块设备接口使虚拟块设备成为与 Ceph 这样的海量存储系统交互的理想之选。
Ceph 块设备是精简配置的、大小可调且将数据条带化存储到集群内的多个 OSD 。 Ceph 块设备利用 RADOS 的多种能力,如快照、复制和一致性。 Ceph 的 RADOS 块设备( RBD )使用内核模块或 librbd 库与 OSD 交互。
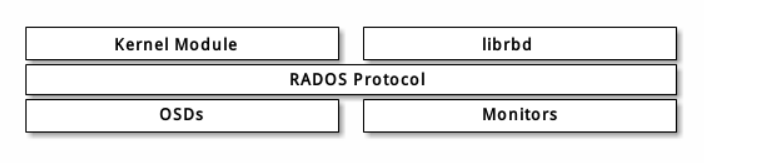
创建存储池 ----- 创建块设备image --------ceph客户端挂载
存储池
如果你开始部署集群时没有创建存储池, Ceph 会用默认存储池存数据。存储池提供的功能:
- 自恢复力: 你可以设置在不丢数据的前提下允许多少 OSD 失效,对多副本存储池来说,此值是一对象应达到的副本数。典型配置存储一个对象和它的一个副本(即 size = 2),但你可以更改副本数;对纠删编码的存储池来说,此值是编码块数(即纠删码配置里的 m=2 )。
- 归置组: 你可以设置一个存储池的归置组数量。典型配置给每个 OSD 分配大约 100 个归置组,这样,不用过多计算资源就能得到较优的均衡。配置了多个存储池时,要考虑到这些存储池和整个集群的归置组数量要合理。
- CRUSH 规则: 当你在存储池里存数据的时候,与此存储池相关联的 CRUSH 规则集可控制 CRUSH 算法,并以此操纵集群内对象及其副本的复制(或纠删码编码的存储池里的数据块)。你可以自定义存储池的 CRUSH 规则。
- 快照: 用 ceph osd pool mksnap 创建快照的时候,实际上创建了某一特定存储池的快照。
- 设置所有者: 你可以设置一个用户 ID 为一个存储池的所有者。
要把数据组织到存储池里,你可以列出、创建、删除存储池,也可以查看每个存储池的利用率。
列出存储池
ceph osd lspools
归置组
确定 pg_num 取值是强制性的,因为不能自动计算。下面是几个常用的值: 少于 个 OSD 时可把 pg_num 设置为
OSD 数量在 到 个时,可把 pg_num 设置为
OSD 数量在 到 个时,可把 pg_num 设置为
OSD 数量大于 时,你得理解权衡方法、以及如何自己计算 pg_num 取值
自己计算 pg_num 取值时可借助 pgcalc 工具
随着 OSD 数量的增加,正确的 pg_num 取值变得更加重要,因为它显著地影响着集群的行为、以及出错时的数据持久性(即灾难性事件导致数据丢失的概率)
归置组是如何使用
储池内的归置组( PG )把对象汇聚在一起,因为跟踪每一个对象的位置及其元数据需要大量计算——即一个拥有数百万对象的系统,不可能在对象这一级追踪位置
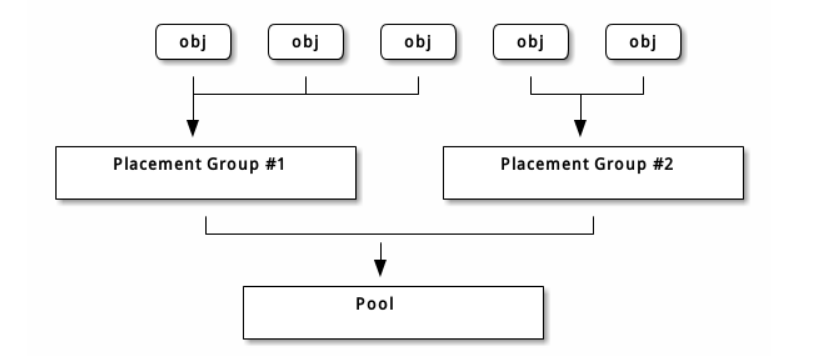
Ceph客户端会计算某一对象应该位于哪个归置组里,它是这样实现的,先给对象ID做哈希操作,然后再根据指定存储池里的PG数量,存储池ID做一个运算。详情见PG映射到OSD。
放置组中的对象内容存储在一组OSD中。例如,在大小为2的复制池中,每个放置组将在两个OSD上存储对象,如下所示。
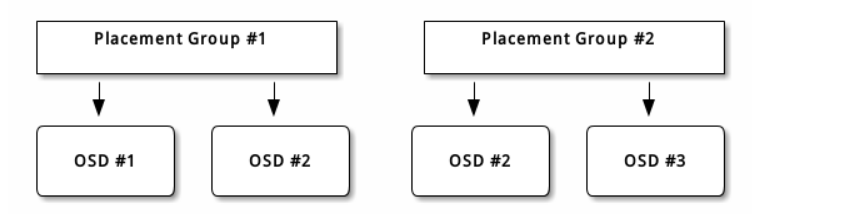
如果OSD#2失败,另一个将被分配到放置组#1,并且将填充OSD#1中的所有对象的副本。如果池大小从两个更改为三个,则会为展示位置组分配一个额外的OSD,并将接收展示位置组中的所有对象的副本。
展示位置组不拥有OSD,他们将其与同一个游泳池中的其他展示位置组或其他游泳池共享。如果OSD#2失败,则位置组#2也将不得不使用OSD#3来恢复对象的副本。
当展示位置组数量增加时,新的展示位置组将被分配OSD。CRUSH功能的结果也将发生变化,以前的放置组中的一些对象将被复制到新的放置组中,并从旧放置组中移除
创建存储池
创建存储池前先看看存储池、归置组和 CRUSH 配置参考。你最好在配置文件里重置默认归置组数量,因为默认值并不理想。关于归置组数量请参考设置归置组数量
创建存储池命令:
ceph osd pool create {pool-name} pg_num
ceph osd pool create data
删除存储池
ceph osd pool delete {pool-name} [{pool-name} --yes-i-really-really-mean-it]
[root@admin ~]# ceph osd pool delete data data --yes-i-really-really-mean-it #注意要写 2个存储池data
重命名存储池
[root@admin ~]# ceph osd pool rename data fengjian
查看存储池统计信息
[root@admin ~]# rados df
pool name KB objects clones degraded unfound rd rd KB wr wr KB
fengjian
rbd
total used
total avail
total space
查看 pool 具体参数
[root@admin ~]# ceph osd dump | grep pool
pool 0 'rbd' replicated size 2 min_size 1 crush_ruleset 0 object_hash rjenkins pg_num 64 pgp_num 64 last_change 38 flags hashpspool stripe_width 0
pool 4 'fengjian' replicated size 2 min_size 1 crush_ruleset 0 object_hash rjenkins pg_num 128 pgp_num 128 last_change 40 flags hashpspool stripe_width 0
rbd 命令可用于创建、罗列、内省和删除块设备image,也可克隆image、创建快照、回滚快照、查看快照等等
创建块设备image
要在 fengjian 这个存储池中创建一个名为 kubernetes-pvc 大小为 20GB 的image
[root@admin ~]# rbd create --size fengjian/kubernetes-pvc-
如果创建image时不指定存储池,它将使用默认的 rbd 存储池
罗列块设备image
[root@admin ~]# rbd ls fengjian
kubernetes-pvc- 如果不写 pool fengjian ,那么默认 显示rbd 这个pool
[root@admin ~]# rbd ls
检索image信息
[root@admin ~]# rbd info fengjian/kubernetes-pvc-
rbd image 'kubernetes-pvc-1':
size MB in objects
order ( kB objects)
block_name_prefix: rbd_data.107c74b0dc51
format:
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
flags: 默认不指定pool,默认是rbd pool
调整块设备image大小
Ceph 块设备image是精简配置,只有在你开始写入数据时它们才会占用物理空间。然而,它们都有最大容量,就是你设置的 --size 选项。如果你想增加(或减小) Ceph 块设备image的最大尺寸,执行下列命令:
rbd resize --size 2048 pool/foo (to increase)
rbd resize --size 2048 pool/foo --allow-shrink (to decrease) 增加块设备image大小
[root@admin ~]# rbd resize --size fengjian/kubernetes-pvc-
Resizing image: % complete...done.
[root@admin ~]# rbd info fengjian/kubernetes-pvc-
rbd image 'kubernetes-pvc-1':
size MB in objects
order ( kB objects)
block_name_prefix: rbd_data.107c74b0dc51
format:
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
flags:
减小块设备image大小
[root@admin ~]# rbd resize --size fengjian/kubernetes-pvc- --allow-shrink
Resizing image: % complete...done.
[root@admin ~]# rbd info fengjian/kubernetes-pvc-
rbd image 'kubernetes-pvc-1':
size MB in objects
order ( kB objects)
block_name_prefix: rbd_data.107c74b0dc51
format:
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
flags:
删除块设备image
rbd rm {pool-name}/{image-name}
[root@admin ~]# rbd rm foo
[root@admin ~]# rbd rm fengjian/kubernetes-pvc-
映射块设备
用 rbd 把image名映射为内核模块。必须指定image名、存储池名、和用户名。若 RBD 内核模块尚未加载, rbd 命令会自动加载。
rbd map rbd/myimage --id admin
如果你启用了 cephx 认证,还必须提供密钥,可以用密钥环或密钥文件指定密钥。
rbd map rbd/myimage --id admin --keyring /path/to/keyring
rbd map rbd/myimage --id admin --keyfile /path/to/file
查看已映射块设备
可以用 rbd 命令的 showmapped 选项查看映射为内核模块的块设备image
rbd showmapped
取消块设备映射
rbd unmap /dev/rbd/rbd/foo
启动所有守护进程
start ceph-all
停止所有守护进程
stop ceph-all
在 ceph admin 节点上创建 image时,出现报错
创建了一个rbd镜像 $ rbd create --size 50000 docker_test
然后,在Ceph client端将该rbd镜像映射为本地设备时出错。 $ rbd map docker_test --name client.admin rbd: sysfs write failed
RBD image feature set mismatch. You can disable features unsupported by the kernel with "rbd feature disable".
In some cases useful info is found in syslog - try "dmesg | tail" or so.
修改Ceph配置文件/etc/ceph/ceph.conf,在global section下,增加 rbd_default_features = 1
[root@admin ceph-cluster]# echo "rbd_default_features = 1" >> ceph.conf 拷贝到所有的 ceph 节点 [root@admin ceph-cluster]# ceph-deploy --overwrite-conf admin monitor1 monitor2 monitor3 osd1 osd2 osd3 需要重启 ceph 所有节点进程
rdb map出错rbd sysfs write failed
创建了一个rbd镜像
$ rbd create --size 4096 docker_test然后,在Ceph client端将该rbd镜像映射为本地设备时出错。
$ rbd map docker_test --name client.admin
rbd: sysfs write failed
RBD image feature set mismatch. You can disable features unsupported by the kernel with "rbd feature disable".
In some cases useful info is found in syslog - try "dmesg | tail" or so.原因:
rbd镜像的一些特性,OS kernel并不支持,所以映射失败。我们查看下该镜像支持了哪些特性。
$ rbd info docker_test
rbd image 'docker_test':
size 4096 MB in 1024 objects
order 22 (4096 kB objects)
block_name_prefix: rbd_data.43702ae8944a
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
flags: 可以看到特性feature一栏,由于我OS的kernel只支持layering,其他都不支持,所以需要把部分不支持的特性disable掉。
方法一:
直接diable这个rbd镜像的不支持的特性:
$ rbd feature disable docker_test exclusive-lock object-map fast-diff deep-flatten方法二:
创建rbd镜像时就指明需要的特性,如:
$ rbd create --size 4096 docker_test --image-feature layering方法三:
如果还想一劳永逸,那么就在执行创建rbd镜像命令的服务器中,修改Ceph配置文件/etc/ceph/ceph.conf,在global section下,增加
rbd_default_features = 1再创建rdb镜像。
$ rbd create --size 4096 docker_test通过上述三种方法后,查看rbd镜像的信息。
$ rbd info docker_test
rbd image 'docker_test':
size 4096 MB in 1024 objects
order 22 (4096 kB objects)
block_name_prefix: rbd_data.43a22ae8944a
format: 2
features: layering
flags:再次尝试映射rdb镜像到本地块设备,成功!
$ rbd map docker_test --name client.admin
/dev/rbd0k8s node 节点安装ceph 1 在管理节点,通过ceph-deploy 把ceph 安装到 ceph-client 节点
ceph-deploy install node1 node2 node3 node4
2.在管理节点上,用 ceph-deploy 把 Ceph 配置文件和 ceph.client.admin.keyring 拷贝到 ceph-client
ceph-deploy admin node1 node2 node3 node4 #需要注意权限
chmod +r/etc/ceph/ceph.client.admin.keyring
CEPH 文件系统
注释: 不能在admin服务器上建立元数据,可以是monitor 或 osd
Ceph 文件系统( Ceph FS )是个 POSIX 兼容的文件系统,它使用 Ceph 存储集群来存储数据。 Ceph 文件系统与 Ceph 块设备、同时提供 S3 和 Swift API 的 Ceph 对象存储、或者原生库( librados )一样,都使用着相同的 Ceph 存储集群系统。

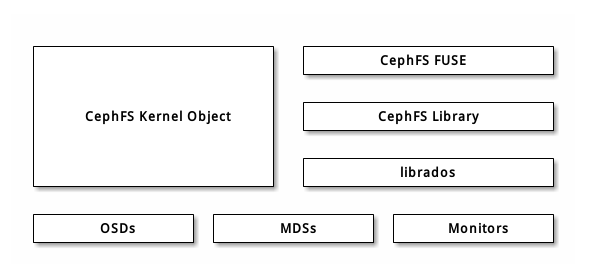
Ceph 文件系统要求 Ceph 存储集群内至少有一个 Ceph 元数据服务器
增加/拆除元数据服务器
用 ceph-deploy 增加和拆除元数据服务器很简单,只要一个命令就可以增加或拆除一或多个元数据服务器

增加一元数据服务器
部署完监视器和 OSD 后,还可以部署元数据服务器
{host-name}[:{daemon-name}] [{host-name}[:{daemon-name}] ...]
[root@admin ceph-cluster]# cd /opt/ceph-cluster [root@admin ceph-cluster]# ceph-deploy mds create monitor1 monitor2 monitor3
monitor服务器上,查询mds 进程

拆除一元数据服务器
尚未实现……?
创建 CEPH 文件系统
一个 Ceph 文件系统需要至少两个 RADOS 存储池,一个用于数据、一个用于元数据。
- 为元数据存储池设置较高的副本水平,因为此存储池丢失任何数据都会导致整个文件系统失效。
- 为元数据存储池分配低延时存储器(像 SSD ),因为它会直接影响到客户端的操作延时。
[root@monitor1 ceph-cluster]# ceph osd pool create cephfs_data
pool 'cephfs_data' created
[root@monitor1 ceph-cluster]# ceph osd pool create cephfs_metadata
pool 'cephfs_metadata' created
创建好存储池后,你就可以用 fs new 命令创建文件系统
[root@monitor1 ceph-cluster]# ceph fs new cephfs cephfs_metadata cephfs_data
new fs with metadata pool and data pool 7 ######删除文件系统 1.停止进程
[root@monitor1 ceph-cluster]# systemctl stop ceph-mds.target
2.将mds标记成失效
[root@monitor1 ceph-cluster]# ceph mds fail 0
3. 删除ceph文件系统
[root@monitor1 ceph-cluster]# ceph fs rm cephfs --yes-ireally-really-mean-it
[root@monitor1 ceph-cluster]# ceph fs ls
name: cephfs, metadata pool: cephfs_metadata, data pools: [cephfs_data ]
文件系统创建完毕后, MDS 服务器就能达到 active 状态了,比如在一个单 MDS 系统中:
[root@monitor1 ~]# $ ceph mds stat
e5: // up {=a=up:active}
用内核驱动挂载 CEPH 文件系统
#客户端不用安装ceph-common
1. 加载rbd 内核模块
modprobe rbd
[root@node4 ~]# lsmod | grep rbd
rbd 73158 0
libceph 244999 1 rbd
2. 获取admin key
[root@admin ceph-cluster]# cat ceph.client.admin.keyring
[client.admin]
key = AQDIfjtaCImdLRAAGJ1Q1lwpuMdadUutFrg0Zg==
caps mds = "allow *"
caps mon = "allow *"
caps osd = "allow *"
3. 创建挂载点
[root@node4 ~]# mkdir /root/cephfs/
# 其中192.168.20.223 为monitor节点,并且使用monitor 的端口
[root@node4 ~]# mount -t ceph 192.168.20.223::/ /root/cephfs -o name=admin,secret=AQDIfjtaCImdLRAAGJ1Q1lwpuMdadUutFrg0Zg==

4. 如果有多个monitor节点,可以挂在多个节点,保证cephfs的高可用性,
[root@admin ~]# mount -t ceph 192.168.20.223:,192.168.20.224:,192.168.20.225::/ /root/cephfs -o name=admin,secret=AQDIfjtaCImdLRAAGJ1Q1lwpuMdadUutFrg0Zg==

用户空间挂载 CEPH 文件系统
1. 客户端安装 ceph-fuse 工具包
yum -y install ceph-fuse
mkdir /etc/ceph
从ceph 集群拷贝 ceph.conf 和 ceph.client.admin.keyring 到客户端 /etc/ceph/目录下
并且 属于644 权限 chmod 644 /etc/ceph/ceph.client.admin.keyring
[root@etcd1 ceph]# chmod ceph.client.admin.keyring
2. 使用 ceph-fuse 挂载命令
挂在一个monitor
[root@etcd1 ~]# ceph-fuse -m 192.168.20.225: /root/cephfs
挂在多个monitor
[root@etcd1 ~]# ceph-fuse -m 192.168.20.223:,192.168.20.224:,192.168.20.225: /root/cephfs
如果在某些地方碰到麻烦,想从头再来,可以用下列命令清除配置:
ceph-deploy purgedata {ceph-node} [{ceph-node}]
ceph-deploy forgetkeys
用下列命令可以连 Ceph 安装包一起清除:
ceph-deploy purge {ceph-node} [{ceph-node}]
如果执行了 purge ,你必须重新安装 Ceph 。
克隆使用的 format 2 模式,才能克隆
创建分层快照和克隆流程 1. create block device image -----> create a snapshot -------> protect the snapshot(快照保护) -----> clone the snapshot
rbd create feng1 --size --image-format rbd --pool rbd snap create --snap fengjian1_snap fengjian1 rbd snap protect rbd/fengjian1@fengjian1_snap rbd clone rbd/fengjian1@fengjian1_snap --snap rbd/fengjian1_snap_clone 查看快照的克隆
rbd --pool {pool-name} children --image {image-name} --snap {snap-name} rbd children {pool-name}/{image-name}@{snapshot-name} 举例
rbd children rbd/fengjian1@fengjian1_snap
安装RADOS gateway 自从 firefly (v0.80) 版本开始,Ceph 对象网关运行在 Civetweb 上(已经集成进守护进程 ceph-radosgw ),而不再是 Apache 和 FastCGI 之上。使用 Civetweb简化了Ceph对象网关的安装和配置。 Ceph 对象网关不再支持SSL。你可以设置一个支持 SSL 的反向代理服务器来将 HTTPS 请求转为 HTTP 请求发给 CivetWeb。
ceph 分布式存储安装的更多相关文章
- 一步一步安装配置Ceph分布式存储集群
Ceph可以说是当今最流行的分布式存储系统了,本文记录一下安装和配置Ceph的详细步骤. 提前配置工作 从第一个集群节点开始的,然后逐渐加入其它的节点.对于Ceph,我们加入的第一个节点应该是Moni ...
- Ceph分布式存储(luminous)部署文档-ubuntu18-04
Ceph分布式存储(luminous)部署文档 环境 ubuntu18.04 ceph version 12.2.7 luminous (stable) 三节点 配置如下 node1:1U,1G me ...
- Centos7下使用Ceph-deploy快速部署Ceph分布式存储-操作记录
之前已详细介绍了Ceph分布式存储基础知识,下面简单记录下Centos7使用Ceph-deploy快速部署Ceph环境: 1)基本环境 192.168.10.220 ceph-admin(ceph-d ...
- Ceph分布式存储-运维操作笔记
一.Ceph简单介绍1)OSDs: Ceph的OSD守护进程(OSD)存储数据,处理数据复制,恢复,回填,重新调整,并通过检查其它Ceph OSD守护程序作为一个心跳 向Ceph的监视器报告一些检测信 ...
- Ceph分布式存储-原理介绍及简单部署
1)Ceph简单概述Ceph是一个分布式存储系统,诞生于2004年,最早致力于开发下一代高性能分布式文件系统的项目.Ceph源码下载:http://ceph.com/download/.随着云计算的发 ...
- Ceph分布式存储-总
Ceph分布式存储-总 目录: Ceph基本组成及原理 Ceph之块存储 Ceph之文件存储 Ceph之对象存储 Ceph之实际应用 Ceph之总结 一.Ceph基本组成及原理 1.块存储.文件存储. ...
- Ceph分布式存储部署过程
前言: 环境介绍:此次部署系统为Cenots 7 MON.OSD 10.110.180.112 Admin MON.OSD 10.110.180.113 Node1 MON.OSD 10.110.18 ...
- CentOS 7部署 Ceph分布式存储架构
一.概述 随着OpenStack日渐成为开源云计算的标准软件栈,Ceph也已经成为OpenStack的首选后端存储.Ceph是一种为优秀的性能.可靠性和可扩展性而设计的统一的.分布式文件系统. cep ...
- Centos7下使用Ceph-deploy快速部署Ceph分布式存储-操作记录(转)
之前已详细介绍了Ceph分布式存储基础知识,下面简单记录下Centos7使用Ceph-deploy快速部署Ceph环境:1)基本环境 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ...
随机推荐
- Java数据类型和不同数据类型在JVM内存分配
1.java数据类型分类 Java语言是强类型(Strongly typed)语言,强类型包含两方面的含义:①所有的变量必须先声明,后使用:②指定类型的变量只能接受类型与之匹配的值.这意味着每个变量和 ...
- COGS2608 [河南省队2016]无根树
传送门 这题大概就是传说中的动态树形DP了吧,学习了一波…… 首先,对于没有修改的情况,不难想到树形DP,定义$f_i$表示强制必须选$i$且只能再选$i$的子树中的点的最优解,易得转移方程$f_i= ...
- [AngularJS] “路由”的定义概念、使用详解——AngularJS学习资料教程
这是小编的一些学习资料,理论上只是为了自己以后学习需要的,但是还是需要认真对待的 以下内容仅供参考,请慎重使用学习 AngularJS“路由”的定义概念 AngularJS最近真的很火,很多同事啊同学 ...
- OpenGL学习--03--矩阵
Model--View--Projection 1.tutorial03.cpp // Include standard headers #include <stdio.h> #inclu ...
- iOS上Delegate的悬垂指针问题
文章有点长,写的过程很有收获,但读的过程不一定有收获,慎入 [摘要] 悬垂指针(dangling pointer)引起的crash问题,是我们在iOS开发过程当中经常会遇到的.其中由delegat ...
- JAVA 分布式 - 分布式介绍
什么是分布式系统? 要理解分布式系统,主要需要明白一下2个方面: 1.分布式系统一定是由多个节点组成的系统. 其中,节点指的是计算机服务器,而且这些节点一般不是孤立的,而是互通的. 2.这些连通的节点 ...
- Vue 框架-07-循环指令 v-for,和模板的使用
Vue 框架-07-循环指令 v-for,和模板的使用 本章主要是写一些小实例,记录代码,想要更详细的话,请查看 官方文档:https://cn.vuejs.org/v2/guide/#%E6%9D% ...
- Python3 循环语句
Python3 循环语句 转来的 很适合小白 感谢作者 Python中的循环语句有 for 和 while. Python循环语句的控制结构图如下所示: while 循环 Python中wh ...
- 【Java】操作mysql数据库
package bd; import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; im ...
- springMVC入门-07
删除功能实现,对应controller类中的代码如下所示: @RequestMapping(value="/{username}/delete",method=RequestMet ...