kettle利用参数遍历执行指定目录下的所有对象
使用kettle设计ETL设计完成后,我们就需要按照我们业务的需要对我们设计好的ETL程序,ktr或者kjb进行调度,以实现定时定点的数据抽取,或者说句转换工作,我们如何实现调度呢?
场景:在/works/wxj/test目录下放着两个ktr模型,我们需要每天晚上24点定时抽取数据
如图所示:

方法一:最简单的方法就是设计一个kjb,拖两个ktr控件,把两个ktr模型串起来,然后定时的调度这个kjb文件即可实现每天定时的抽取数据。
方法二:如果随着业务的增多,ktr文件原来越多,那么上面的情况操作起来就很麻烦,我们在目录下新增加一个ktr模型我们就要去修改总的kjb,把新增加的ktr串进去,这样才能保证新增加的ktr被执行到,那么下面我们来尝试另一种方法,只要把新设计好的ktr文件放入指定目录,调度程序就会遍历执行该目录下面的所有程序。
2.1:整体描述:
大概需要的控件有:
(1)Get repository names根据指定目录得到所有ktr或者kjb的列表

(2)复制记录到结果

(3)从结果获取记录

(4)设置环境变量

(5)表输入与表述出job中的ktr与kjb
2.2:设计过程
step1:新建tran_getall.ktr(读取指定目录下的对象,将数据写入到内存)

控件1设计如下
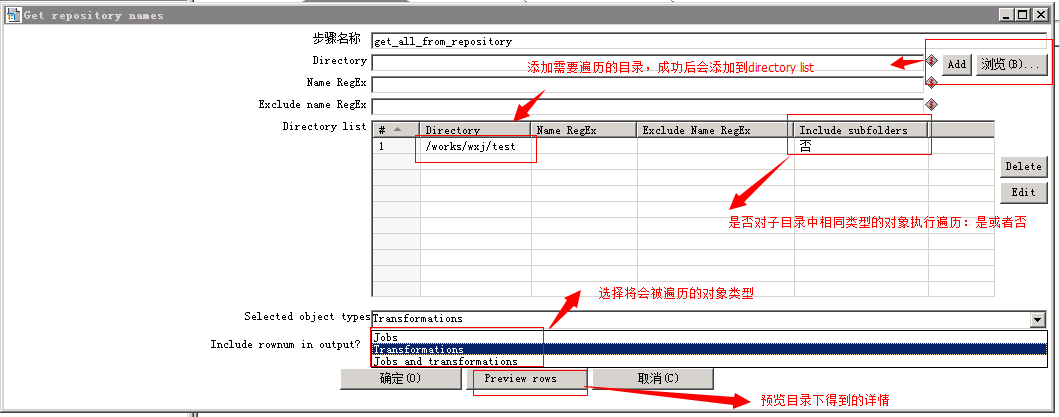
控件2设计如下

step2:新建tran_set_variable.ktr(从内存读取结果集,并设置环境变量)
 、
、
控件3设计如下

控件4设计如下

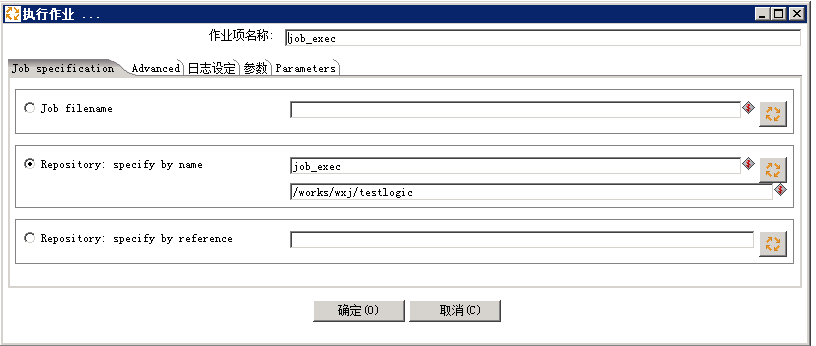
step3:新建job_exec.kjb(传参并执行所有指定目录对象)

1处的详细设计为

2处的详细设计为

step4:创建job_runall.kjb(调度所有对象,根据逻辑设计执行顺序)

从上面可以大概的看出,tran_getall是从资源库得到目录下面的所有内容,job_exec这个是传参赋值并且执行所有对象,这样的顺序是正确的。
1处的详细设计为

2处的详细设计为
2处需要注意的是

一定要勾上对每个输入行执行一次,这样才会循环覆盖一次变量值不然会报参数重复错误
job_exec的作用也就在这个地方,否则就可以讲job_exec省去,把所有的逻辑放在job_runall里面来实现了,OK 设计完毕运行job_runall.

执行成功,看结果

看遍历排序

OK,效果实现,这样无论目录/works/wxj/test下有多少个ktr或者kjb都会被遍历执行了,不必一个一个的去串起来
PS:需要注意的是如果遇到特殊的业务逻辑比如涉及到ktr执行先后顺序的,必须先跑ktr1才可以跑ktr2的需要单独拿出来处理。因为遍历目录的时候的顺序不是我们手工可以改变的,至少现在我还没有发现可以控制顺序来执行的方法。
kettle利用参数遍历执行指定目录下的所有对象的更多相关文章
- c++ 指定目录下的文件遍历
要实现指定目录下文件的遍历需要执行一下的部分: 第一步获取当前路径的名字:(MAX_PATH是在windows定义的所有的路径名字不超过其,调用该函数会使得得到当前的目录) #include < ...
- java-IO流(File对象-深度遍历指定目录下的文件夹和文件)
需求:遍历这个树状结构 File(String pathname) '\\'为了转义'\' // 通过抽象路径pathname 创建一个新的文件或者目录 File parent = new File( ...
- C#.NET中遍历指定目录下的文件(及所有子目录及子目录里更深层目录里的文件)
//遍历一个目录下所有的文件列表,代码实例 DirectoryInfo dir = new DirectoryInfo(folderName);var list = GetAll(dir); /// ...
- delphi遍历指定目录下指定类型文件的函数
遍历指定目录下指定类型文件的函数// ================================================================// 遍历某个文件夹下某种文件,/ ...
- 利用 FilesystemIterator 获取指定目录下的所有文件
/** * 获取指定目录下的所有文件 * @param null $path * @return array */ public function getFileByPath($path = null ...
- 微软BI 之SSIS 系列 - 在 SSIS 中将指定目录下的所有文件分类输出到不同文件夹
开篇介绍 比如有这样的一个需求,旧的一个业务系统通常将产出的文件输出到同一个指定的目录下的不同子目录,输出的文件类型有 XML,EXCEL, TXT 这些不同后缀的文件.现在需要在 SSIS 中将它们 ...
- [No000073]C#直接删除指定目录下的所有文件及文件夹(保留目录)
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.T ...
- java利用WatchService实时监控某个目录下的文件变化并按行解析(注:附源代码)
首先说下需求:通过ftp上传约定格式的文件到服务器指定目录下,应用程序能实时监控该目录下文件变化,如果上传的文件格式符合要求,将将按照每一行读取解析再写入到数据库,解析完之后再将文件改名. 一. 一开 ...
- Java基础---Java---IO流-----File 类、递归、删除一个带内容的目录、列出指定目录下文件夹、FilenameFilte
File 类 用来将文件或者文件夹封装成对象 方便对文件与文件夹进行操作. File对象可以作为参数传递给流的构造函数 流只用操作数据,而封装数据的文件只能用File类 File类常见方法: 1.创建 ...
随机推荐
- 一个人也可以建立 TCP 连接呢
今天(恰巧是今天)看到有人在 SegmentFault 上问「TCP server 为什么一个端口可以建立多个连接?」.提问者认为 client 端就不能使用相同的本地端口了.理论上来说,确定一条链路 ...
- 【搜索】【组合数学】zoj3841 Card
转载自:http://blog.csdn.net/u013611908/article/details/44545955 题目大意:一副牌除掉大小王,然后有一些已经形成了序列,让你算剩下的牌能组合出多 ...
- OD基本汇编指令
jmp ;无条件跳转 指哪飞哪 一些杂志中说的直飞光明顶,指的就是它了~ 光明顶一般指爆破地址根据条件跳转的指令:JE ;等于则跳转 JNE ;不等于则跳转 JZ ;为 0 则跳转 JNZ ;不为 ...
- HTTP首部字段
HTTP首部由首部字段名和首部字段值组成,以逗号隔开.如果首部出现重复,有些浏览器优先处理第一个出现的首部,有些优先处理后者. 主要分为四大类 通用首部字段 请求首部字段 响应首部字段 实体首部字段 ...
- Apache2.4使用require指令进行访问控制--允许或限制IP访问/通过User-Agent禁止不友好网络爬虫
从Apache2.2.X到Apache2.4.X,在配置上稍微有点不同,需要特别注意.现在记录下关于访问控制的配置. 经过苦苦搜索,终于配置成功.参考了这篇文章:http://www.cnblogs. ...
- python开发_xml.etree.ElementTree_XML文件操作_该模块在操作XML数据是存在安全隐患_慎用
xml.etree.ElementTree模块实现了一个简单而有效的用户解析和创建XML数据的API. 在python3.3版本中,该模块进行了一些修改: xml.etree.cElementTree ...
- Git_创建与合并分支
在版本回退里,你已经知道,每次提交,Git都把它们串成一条时间线,这条时间线就是一个分支.截止到目前,只有一条时间线,在Git里,这个分支叫主分支,即master分支.HEAD严格来说不是指向提交,而 ...
- Polly简介 — 1. 故障处理策略
Polly 是 .Net 下的一套瞬时故障处理及恢复的函式库,可让开发者以fluent及线程安全的方式来应用诸如Retry.Circuit Breaker.Timeout.Bulkhead Isola ...
- C++ Primer 学习笔记_34_STL实践与分析(8) --引言、pair类型、关联容器
STL实践与分析 --引言.pair类型.关联容器 引言: 关联容器与顺序容器的本质差别在于:关联容器通过键[key]来存储和读取元素,而顺序容器则通过元素在容器中的位置顺序的存取元素. ma ...
- Hibernate中的Session缓存问题
1. Session 缓存: 1) . 在 Session 接口的实现中包括一系列的 Java 集合 , 这些 Java 集合构成了 Session 缓存 . 它用于存放 Sessi ...