【回文串-Manacher】
Manacher算法能够在O(N)的时间复杂度内得到一个字符串以任意位置为中心的回文子串。其算法的基本原理就是利用已知回文串的左半部分来推导右半部分。
转:http://blog.sina.com.cn/s/blog_70811e1a01014esn.html
首先,在字符串s中,用rad[i]表示第i个字符的回文半径,即rad[i]尽可能大,且满足:
s[i-rad[i],i-1]=s[i+1,i+rad[i]]
很明显,求出了所有的rad,就求出了所有的长度为奇数的回文子串.
至于偶数的怎么求,最后再讲.
假设现在求出了rad[1..i-1],现在要求后面的rad值,并且通过前面的操作,得知了当前字符i的rad值至少为j.现在通过试图扩大j来扫描,求出了rad[i].再假设现在有个指针k,从1循环到rad[i],试图通过某些手段来求出[i+1,i+rad[i]]的rad值.
根据定义,黑色的部分是一个回文子串,两段红色的区间全等.
因为之前已经求出了rad[i-k],所以直接用它.有3种情况:
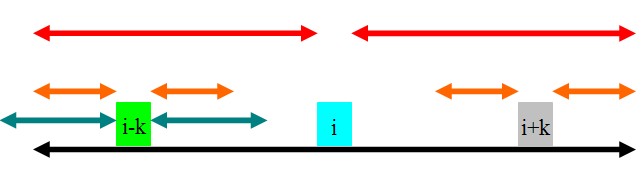
①rad[i]-k<rad[i-k]
如图,rad[i-k]的范围为青色.因为黑色的部分是回文的,且青色的部分超过了黑色的部分,所以rad[i+k]肯定至少为rad[i]-k,即橙色的部分.那橙色以外的部分就不是了吗?这是肯定的.因为如果橙色以外的部分也是回文的,那么根据青色和红色部分的关系,可以证明黑色部分再往外延伸一点也是一个回文子串,这肯定不可能,因此rad[i+k]=rad[i]-k.为了方便下文,这里的rad[i+k]=rad[i]-k=min(rad[i]-k,rad[i-k]).
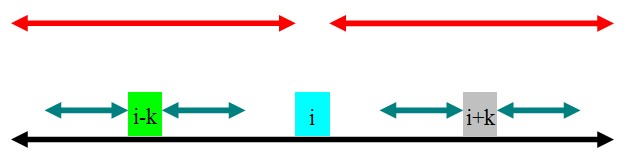
②rad[i]-k>rad[i-k]
如图,rad[i-k]的范围为青色.因为黑色的部分是回文的,且青色的部分在黑色的部分里面,根据定义,很容易得出:rad[i+k]=rad[i-k].为了方便下文,这里的rad[i+k]=rad[i-k]=min(rad[i]-k,rad[i-k]).
根据上面两种情况,可以得出结论:当rad[i]-k!=rad[i-k]的时候,rad[i+k]=min(rad[i]-k,rad[i-k]).
注意:当rad[i]-k==rad[i-k]的时候,就不同了,这是第三种情况:
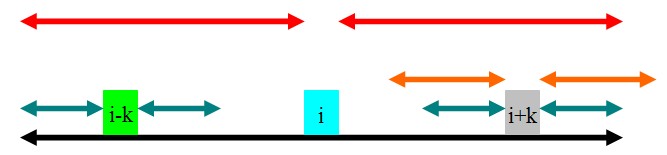
如图,通过和第一种情况对比之后会发现,因为青色的部分没有超出黑色的部分,所以即使橙色的部分全等,也无法像第一种情况一样引出矛盾,因此橙色的部分是有可能全等的,但是,根据已知的信息,我们不知道橙色的部分是多长,因此就把i指针移到i+k的位置,j=rad[i-k](因为它的rad值至少为rad[i-k]),等下次循环的时候再做了.
整个算法就这样.
至于时间复杂度为什么是O(n),我已经证明了,但很难说清楚.所以自己体会吧.
上文还留有一个问题,就是这样只能算出奇数长度的回文子串,偶数的就不行.怎么办呢?有一种直接但比较笨的方法,就是做两遍(因为两个程序是差不多的,只是rad值的意义和一些下标变了而已).但是写两个差不多的程序是很痛苦的,而且容易错.所以一种比较好的方法就是在原来的串中每两个字符之间加入一个特殊字符,再做.如:aabbaca,把它变成(#a#a#b#b#a#c#a#),左右的括号是为了使得算法不至于越界。这样的话,无论原来的回文子串长度是偶数还是奇数,现在都变成奇数了.
HDU-3068 最长回文
分析:直接套上算法即可,注意插入一些字符来使得算法能够适应长度为奇数和偶数的情况。
#include <cstdlib>
#include <cstring>
#include <cstdio>
#include <iostream>
#include <algorithm>
using namespace std; const int N = ;
char str[N], cpy[N<<];
int seq[N<<]; void manacher(char s[], int length, int rad[]) {
for (int i=,j=,k; i < length; i+=k) {
while (s[i-j-] == s[i+j+]) ++j;
rad[i] = j;
for (k = ; k <= rad[i] && rad[i-k] != rad[i]-k; ++k) { // 利用类似镜像的方法缩短了时间
rad[i+k] = min(rad[i-k], rad[i]-k);
}
j = max(j-k, );
}
} int main() {
while (scanf("%s", str) != EOF) {
int len = strlen(str);
cpy[] = '(', cpy[] = '#';
for (int i=, j=; i < len; ++i, j+=) {
cpy[j] = str[i];
cpy[j+] = '#';
}
len = len*+;
cpy[len-] = ')';
manacher(cpy, len, seq);
int Max = ;
for (int i = ; i < len; ++i) {
Max = max(Max, seq[i]);
}
printf("%d\n", Max);
}
return ;
}
HDU-4513 吉哥系列故事——完美队形II
题意:给定一个数列,长度最长达到100000,要求找出一个最长的左边单调递增,右边单调递减的回文子串。
分析:刚开始的错误想法想法是所有的合法的解必定是一个回文串,因此把以任意一点为中心的所有回文串长度求出来,然后按照长度由长到短排一个序,暴力先判定最长的单调回文串,然后依据当前的最优值进行剪枝,不过还是TLE。网上看了下别人的想法,都说是一个Manacher的应用,而且貌似别人的模板和我的不太一样,现在来说说我的理解。
其实一开始的时候我就有想过直接定义一个单调回文来做,但是仔细想想,如果某个单调回文已经求了出来,那么其左翼对应右翼肯定不会是一个单调回文,因为左翼一定是一个单调的序列,不会出现以一个为中心向两边下降的情况,当然除非出现相同的值。之所以出现这种想法是因为我以为只有左翼里面包含回文子串才会使得时间复杂度降低,而时间上该题的模型中,求出了一个单调回文区间,那么利用左翼的对应面不可能产生单调回文同样能够加速匹配。总而言之,该算法就是通过求回文来使得右翼的值复制左翼的值达到降低时间复杂度的目的,因此该题只要更改扩展原则即可,由单一的相等改为单调递增或递减。
#include <cstdlib>
#include <cstring>
#include <cstdio>
#include <algorithm>
#include <iostream>
using namespace std; const int N = ;
const int inf = 0x3f3f3f3f;
int n;
int seq[N<<];
int rad[N<<]; inline bool check(int seq[], int a, int b) {
if (seq[a] != seq[b]) return false;
if (!seq[a] && !seq[b] || a == b) return true;
int ar = a+, bl = b-;
if (seq[a] <= seq[ar]) return true;
return false;
} void manacher(int seq[], int rad[], int length) {
for (int i=,j=,k; i<length; i+=k,j-=k) {
while (check(seq, i-j-, i+j+)) ++j;
rad[i] = j;
for (k=; k<=j && rad[i-k]!=rad[i]-k; ++k) {
rad[i+k] = min(rad[i-k], rad[i]-k);
}
}
} inline void getint(int &t) {
char ch;
while ((ch = getchar()), ch < '' || ch > '') ;
t = ch - '';
while ((ch = getchar()), ch >= '' && ch <= '') {
t = t * + ch - '';
}
} int main() {
int T;
scanf("%d", &T);
while (T--) {
memset(seq, , sizeof (seq));
scanf("%d", &n);
seq[] = inf-;
for (int i=,j=; j < n; i+=,++j) {
getint(seq[i]);
}
n = n*+;
seq[n-] = inf-;
manacher(seq, rad, n);
int ret = ;
for (int i = ; i < n; ++i) {
ret = max(ret, rad[i]);
}
printf("%d\n", ret); }
return ;
}
zstu-3769 数回文子串
题意:给定一个字符串序列,统计其中一共有多少个回文串,串的长度大于1。
分析:Manacher算法分析出以每一个位置为中心的长度,相加即可。
#include <cstdlib>
#include <cstring>
#include <cstdio>
#include <iostream>
#include <algorithm>
using namespace std; const int N = ;
char seq[N];
char cpy[N<<];
int rad[N<<]; void manacher(char str[], int rad[], int len) {
for (int i=,j=,k; i < len; i+=k,j-=k) {
while (str[i-j-] == str[i+j+]) ++j;
rad[i] = j;
for (k=; k<=j && rad[i-k]!=rad[i]-k; ++k) {
rad[i+k] = min(rad[i-k], rad[i]-k);
}
}
} int main() {
while (scanf("%s", seq) != EOF) {
int len = strlen(seq);
cpy[] = '(', cpy[] = '#';
for (int i=,j=; j < len; i+=,++j) {
cpy[i] = seq[j];
cpy[i+] = '#';
}
len = len*+;
cpy[len-] = ')';
manacher(cpy, rad, len);
int ret = ;
for (int i = ; i < len; ++i) {
ret += rad[i] / ;
}
printf("%d\n", ret);
}
return ;
}
HDU-3948 The Number of Palindromes
题意:给定一个长度为N的字符串,统计其中一共有多少个不同的回文子串。
分析:本来自己想的方法是manacher处理的同时暴力保留回文串,然后set去重,有算法本身可以知道若一个串是回文串,那么根据左右对称,在第二次循环镜像更新时便可知道右边的回文串在前面就被统计过了,所以不同的回文串只要在第一次扩充之后进行判定即可,因此也可知道不同回文串的个数是O(N)级别的。可惜我的方法还是超时了,遇到极端的aa...aa就会重复构造一个子串。
看到博客好像貌似可以使用后缀数组写,不会后缀数组只有另辟他径了。由于回文串的个数是O(N)级别的,因此可以直接枚举每一个中心点,从长度最长的回文串进行枚举,使用字符串hash(多项式插值取模)来判定是否已经被统计过,如果这个长串已经统计过就可以直接跳过了(因为长串中的短串在之前也一定统计过了)。
关于多项式插值取模:在给定一个字符串左右区间的情况下O(1)计算出其hash值。设一个串为1234123,那么定义一个数组sum[i],其中:
sum[1] = 1, sum[2] = 1*T+2, sum[3] = 1*T^2+2*T+3, sum[4] = 1*T^3+2*T^2+3*T+4 ......
通过这样的定义,[L,R]的值就为sum[R]-sum[L-1]*T^(R-L+1)。
#include <cstdlib>
#include <cstring>
#include <cstdio>
#include <iostream>
#include <algorithm>
#include <string>
#include <cctype>
#include <set>
using namespace std; typedef unsigned long long uint;
const int N = ;
char seq[N];
char cpy[N<<];
int rad[N<<];
const int muts = ;
uint mutpower[N];
uint sum[N]; struct hash_map {
const static int mod = N*+;
int idx, head[mod];
struct hash_tables {
uint key;
int next;
}ele[N*];
void init() {
idx = ;
memset(head, 0xff, sizeof (head));
}
void clear() { // clear的效率要高于init的效率,后期的用以替换init
for (int i = ; i < idx; ++i)
head[ele[i].key%mod] = -;
idx = ;
}
bool find(uint x) {
int hashcode = x%mod;
for (int i = head[hashcode]; i!=-; i=ele[i].next) {
if (ele[i].key == x) return true;
}
return false;
}
void insert(uint x) {
int tmp = x % mod;
ele[idx].key = x;
ele[idx].next = head[tmp];
head[tmp] = idx++;
}
}; // 将hash表的实现封装成一个类 hash_map hash; void manacher(char str[], int rad[], int len) {
for(int i=,j=,k; i < len; i+=k, j=max(j-k,)) {
while (str[i-j-] == str[i+j+]) ++j;
rad[i] = j;
for (k=; k<=j && rad[i-k] != rad[i]-k; ++k) {
rad[i+k] = min(rad[i-k], rad[i]-k);
}
}
} // str串以i为中心,回文半径为j的回文串剔除插入字符后的hashcode
uint gethashcode(char str[], int i, int j) {
int L, R; // 在原来字符串中该回文串左右界
uint ret;
if (isalpha(str[i])) { // 如果中心字符为字母
L = i/- - j/;
R = i/- + j/;
} else {
L = i/ - j/;
R = i/- + j/;
}
ret = sum[R];
if (L) ret -= sum[L-]*mutpower[R-L+];
return ret;
} void gao(char str[], int len) {
// 枚举每一点作为回文串的中心
int ret = ;
for (int i = ; i < len-; ++i) {
int ee = (bool)(!isalpha(str[i]));
for (int j = rad[i]; j >= ee; j-=) {
uint hashcode = gethashcode(str, i, j);
if (!hash.find(hashcode)) {
++ret;
hash.insert(hashcode);
} else { // 如果一个长串已经在hash表里面,那么短的回文串也一定在里面
break;
}
}
}
printf("%d\n", ret);
} int main() { mutpower[] = ;
for (int i = ; i < N<<; ++i) {
mutpower[i] = mutpower[i-] * muts;
}
hash.init(); int T, ca = ;
scanf("%d", &T);
while (T--) {
scanf("%s", seq);
hash.clear();
int len = strlen(seq);
sum[] = seq[]-'a'+; // 避免0元素的出现,其将导致00和0无区别
for (int i = ; i < len; ++i) { // 做出一个前缀的多项式值模式
sum[i] = sum[i-]*muts+seq[i]-'a'+;
}
cpy[] = '(', cpy[] = '#';
for (int i=,j=; j < len; i+=,++j) {
cpy[i] = seq[j];
cpy[i+] = '#';
}
len = len*+;
cpy[len-] = ')';
printf("Case #%d: ", ++ca);
manacher(cpy, rad, len);
gao(cpy, len);
}
return ;
}
ZOJ-3661 Palindromic Substring
题意:给定一个字符串,现在取出串中回文串的一半,奇数回文的取左边部分加上中心元素,偶数回文取左边的一半,现在给一个回文串一个权值,要求统计所有回文串权值中倒数第K小的值为多少。
分析:主要想法是通过Manacher算法处理出以每个字符为中心所产生的回文半径的长度,然后将每个回文串的按照长度从长到短倒着插入到字段树中,插入的过程中访问hash表是否已经插入过回文串,hash表直接保存着上次回文串插入的位置,这样就可以O(1)的时间找到要插入的位置,然后将多出来的长度插入即可。由于上题中已经得知回文串的个数最多是O(N)的,因此这里插入字段树的次数也会控制在O(N)以内。最后通过遍历一次字典树得到最终的结果,从某节点出发,其子树上的数量将要累加到父亲节点上,因为这个子节点都包括这个父亲节点所表示的回文串。另外奇数串和偶数串需要分开处理。
#include <cstdlib>
#include <cstring>
#include <cstdio>
#include <vector>
#include <iostream>
#include <algorithm>
using namespace std; typedef unsigned long long LL;
const int MOD = ;
const int N = ;
const int P = ;
char seq[N];
char cpy[N<<];
int rad[N<<];
int val[];
LL POW[N];
LL sum[N];
vector<pair<LL, int> >vt;
int n, m; void manacher(char str[], int rad[], int len) {
for (int i=,j=,k; i < len; i+=k,j-=k) {
while (str[i-j-] == str[i+j+]) ++j;
rad[i] = j;
for (k=; k<=j && rad[i-k]!=rad[i]-k; ++k) {
rad[i+k] = min(rad[i-k], rad[i]-k);
}
}
} LL getkey(int l, int r) {
if (!l) return sum[r];
else return sum[r]-sum[l-]*POW[r-l+];
} struct Hash_map {
static const int mod = N*+;
int idx, head[mod];
struct hash_tables {
LL key; // 字符串hash之后的值
int pos; // pos表示在字段树中的位置
int nxt;
}ele[N]; // 最多N个不同回文串
void init() {
idx = ;
memset(head, 0xff, sizeof (head));
}
void clear() {
for (int i = ; i < idx; ++i) {
head[ele[i].key%mod] = -;
}
idx = ;
}
int find(LL _key) {
int id = _key % mod;
for (int i = head[id]; ~i; i=ele[i].nxt) {
if (ele[i].key == _key) { // 如果该元素在hash表中,说明已经插入到了字典树当中
return ele[i].pos;
}
}
return -; // 如果没有搜索到的话,返回-1
}
void insert(LL _key, int _pos) {
int id = _key % mod;
ele[idx].key = _key, ele[idx].pos = _pos;
ele[idx].nxt = head[id], head[id] = idx++;
}
};
Hash_map hash; struct Trie {
int root, idx;
struct Node {
int ch[];
int end;
}ele[N]; // 这个空间会不会小了呢
int malloc() {
ele[idx].end = ;
memset(ele[idx].ch, 0xff, sizeof (ele[idx].ch));
return idx++;
}
void init() {
idx = ;
root = malloc();
}
void insert(int p, int l, int r, int axis) {
for (int i = r; i >= l; --i) {
ele[p].ch[seq[i]-'a'] = malloc();
p = ele[p].ch[seq[i]-'a'];
hash.insert(getkey(i, axis), p);
}
++ele[p].end;
}
int cal(int p, LL fac, LL value) {
int tot = ele[p].end;
for (int i = ; i < ; ++i) {
if (ele[p].ch[i] != -) {
tot += cal(ele[p].ch[i], fac*%MOD, (value+val[i]*fac)%MOD);
}
}
if (p != root) // 根节点上没有任何信息不应该被统计
vt.push_back(make_pair(value, tot));
return tot;
}
};
Trie Todd, Teven; void gao() {
for (int i = ; i < n; ++i) { // 处理奇数个元素构成的回文串
int pos = Todd.root, cpyi = i*+;
int left = i-rad[cpyi]/, right = i;
for (int j = left; j <= right; ++j) {
int tmp = hash.find(getkey(j, i));
if (tmp != -) {
pos = tmp;
right = j-;
break;
}
}
Todd.insert(pos, left, right, i);
}
hash.clear();
for (int i = ; i < n-; ++i) { // 处理偶数个元素构成的回文串
int pos = Teven.root, cpyi = i*+;
int left = i-rad[cpyi]/+, right = i;
for (int j = left; j <= right; ++j) {
int tmp = hash.find(getkey(j, i));
if (tmp != -) {
pos = tmp;
right = j-;
break;
}
}
Teven.insert(pos, left, right, i);
}
for (int i = ; i < m; ++i) {
vt.clear();
LL K;
scanf("%llu", &K); // K可能很大
for (int j = ; j < ; ++j) {
scanf("%d", &val[j]);
}
Todd.cal(Todd.root, , ), Teven.cal(Teven.root, , );
sort(vt.begin(), vt.end());
for (int h=; h < (int)vt.size(); ++h) {
if (K > vt[h].second) {
K -= vt[h].second;
} else {
K = ;
printf("%llu\n", vt[h].first);
break;
}
}
if (K) { // 如果总共不足K个回文串
printf("0\n");
}
}
puts("");
} int main() {
POW[] = ;
for (int i = ; i < N; ++i) {
POW[i] = POW[i-]*P;
}
hash.init();
int T;
scanf("%d", &T);
while (T--) {
hash.clear();
Todd.init(), Teven.init();
scanf("%d %d", &n, &m);
scanf("%s", seq);
sum[] = seq[]-'a'+;
for (int i = ; i < n; ++i) {
sum[i] = sum[i-]*P+seq[i]-'a'+;
} // 做成一个多项式的形式
cpy[] = '(', cpy[] = '#';
for (int i=,j=; j < n; i+=,++j) {
cpy[i] = seq[j];
cpy[i+] = '#';
}
int len = n*+;
cpy[len-] = ')';
manacher(cpy, rad, len); // 求出每个点为中心的回文半径
gao();
}
return ;
}
【回文串-Manacher】的更多相关文章
- BZOJ 2342 回文串-Manacher
题目链接:http://www.lydsy.com/JudgeOnline/problem.php?id=2342 思路:先跑一遍Manacher求出p[i]为每个位置为中心的回文半径,因为双倍回文串 ...
- BZOJ 2565 回文串-Manacher
题目链接:http://www.lydsy.com/JudgeOnline/problem.php?id=2565 题意:中文题 思路:定义L[i],R[i].表示以i为左端点/右端点时,最长回文串长 ...
- POJ 3974 回文串-Manacher
题目链接:http://poj.org/problem?id=3974 题意:求出给定字符串的最长回文串长度. 思路:裸的Manacher模板题. #include<iostream> # ...
- BZOJ 2565: 最长双回文串 [Manacher]
2565: 最长双回文串 Time Limit: 10 Sec Memory Limit: 128 MBSubmit: 1842 Solved: 935[Submit][Status][Discu ...
- BZOJ.2565.[国家集训队]最长双回文串(Manacher/回文树)
BZOJ 洛谷 求给定串的最长双回文串. \(n\leq10^5\). Manacher: 记\(R_i\)表示以\(i\)位置为结尾的最长回文串长度,\(L_i\)表示以\(i\)开头的最长回文串长 ...
- HYSBZ2565最长双回文串 Manacher
顺序和逆序读起来完全一样的串叫做回文串.比如 acbca 是回文串,而 abc 不是( abc 的顺序为 “abc” ,逆序为 “cba” ,不相同). 输入长度为 n 的串 S ,求 S 的最长双回 ...
- 洛谷P4555 [国家集训队]最长双回文串(manacher 线段树)
题意 题目链接 Sol 我的做法比较naive..首先manacher预处理出以每个位置为中心的回文串的长度.然后枚举一个中间位置,现在要考虑的就是能覆盖到i - 1的回文串中 中心最靠左的,和能覆盖 ...
- BZOJ3676 APIO2014 回文串 Manacher、SA
传送门 首先一个结论:串\(S\)中本质不同的回文串个数最多有\(|S|\)个 证明考虑以点\(i\)结尾的所有回文串,假设为\(S[l_1,i],S[l_2,i],...,S[l_k,i]\),其中 ...
- luoguP4555 [国家集训队]最长双回文串 manacher算法
不算很难的一道题吧.... 很容易想到枚举断点,之后需要处理出以$i$为开头的最长回文串的长度和以$i$为结尾的最长回文串的长度 分别记为$L[i]$和$R[i]$ 由于求$R[i]$相当于把$L[i ...
随机推荐
- 基础知识《六》---Java集合类: Set、List、Map、Queue使用场景梳理
本文转载自LittleHann 相关学习资料 http://files.cnblogs.com/LittleHann/java%E9%9B%86%E5%90%88%E6%8E%92%E5%BA%8F% ...
- -fomit-frame-pointer 编译选项在gcc 4.8.2版本中的汇编代码研究
#include void fun(void) { printf("fun"); } int main(int argc, char *argv[]){ fun(); return ...
- mybatis随机生成可控制主键的方式
mybatis生成的主键,一般都是用数据库的序列,可是还有不同的写法,比如: 一.NUMBER类型的主键 <insert id="insertPeriodical" para ...
- snmp监控磁盘
http://www.it165.net/os/html/201209/3438.html https://sourceforge.net/p/net-snmp/mailman/message/168 ...
- 菜鸟学Linux命令:find命令 查找文件
find命令是Linux下最常用的命令之一,灵活的使用find命令,你会发现查找文件变得十分简单. 命令格式 find [指定查找目录] [查找规则(选项)] [查找完后执行的动作] 参数规则 - ...
- 2016国产开源软件TOP100(Q1)
随着互联网的发展.开放标准的普及和虚拟化技术的应用等诸多IT新领域的创新及拓展,开源技术凭借其开放性.低成本.稳定性.灵活性.安全性和技术创新性等特点迅速走向成熟,逐步发展成为一种主流模式,日益改变着 ...
- js 使用json.js处理json对象
使用参考代码: <script src="json/json2.js"></script> <script type="text/javas ...
- 最新版Duilib在VS2012下编译错误的解决方法
svn了好几次最新版本的项目源代码, 在VS2012下编译老是出错, 改了后没记录, 结果又忘记, 所以在此记录下. 这个问题很普遍, 非常多的人遇到. 至于 ...
- 面向服务的体系结构(SOA)——(5)关于MEP(Message Exchange Patterns)
SOA中的MEP和JavaEE中的JMS类似,当然了就应该是类似的,因为都是关于消息方面的.一个是对系统架构当中消息的解决思路,一个是针对Java平台中的消息的具体解决办法(严格说不是具体的,只是提供 ...
- html5 (个人笔记)
妙味 html5 1.0 <!DOCTYPE html> <html> <head lang="en"> <meta charset=& ...