ROCK 聚类算法
ROCK (RObust Clustering using linKs) 聚类算法是一种鲁棒的用于分类属性的聚类算法。该算法属于凝聚型的层次聚类算法。之所以鲁棒是因为在确认两对象(样本点/簇)之间的关系时考虑了他们共同的邻居(相似样本点)的数量,在算法中被叫做链接(Link)的概念。而一些聚类算法只关注对象之间的相似度。
ROCK 算法中用到的四个关键概念
- 邻居(Neighbors):如果两个样本点的相似度达到了阈值(θ),这两个样本点就是邻居。阈值(θ)有用户指定,相似度也是通过用户指定的相似度函数计算。常用的分类属性的相似度计算方法有:Jaccard 系数,余弦相似度。
- 链接(Links):两个对象的共同邻居数量
- 目标函数(Criterion Function):最大化下面目标函数以获得最优的聚类结果(最终簇之间的链接总数最小,而簇内的链接总数最大)。Ci:第i个簇,k:簇的个数,ni:Ci的大小(样本点的数量)。一般可使用f (θ) = (1-θ)/(1+θ). f(θ)一般具有以下性质:Ci中的每个样本点在Ci中有nif(θ)个邻居。(具体请见参考文献2)
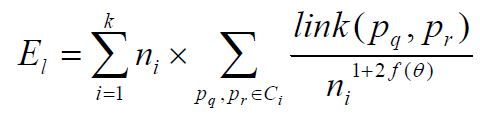
4. 相似性的度量(Goodness Measure):使用该公式计算所有对象的两两相似度,将相似性最高的两个对象合并。通过该相似性度量不断的凝聚对象至k个簇,最终计算上面目标函数值必然是最大的。
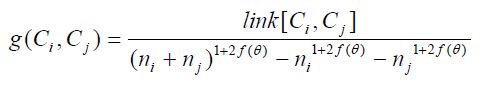 ,link[Ci,Cj]=
,link[Ci,Cj]=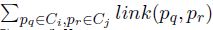
大概算法思路(伪代码请见参考文献2):
输入:需要聚类的个数-k,和相似度阈值-θ
算法:
开始每个点都是单独的聚类,根据计算点与点间的相似度,生成相似度矩阵。
根据相似度矩阵和相似度阈值-θ,计算邻居矩阵-A。如果两点相似度>=θ,取值1(邻居),否则取值0.
计算链接矩阵-L=A x A
计算相似性的度量(Goodness Measure),将相似性最高的两个对象合并。回到第2步进行迭代直到形成k个聚类或聚类的数量不在发生变换。
输出:
簇和异常值(不一定存在)
ROCK in R - cba 包:
load('country.RData')
d<-dist(countries[,-1])
x<-as.matrix(d)
library(cba)
rc <- rockCluster(x, n=4, theta=0.2, debug=TRUE)
rc$cl
参考文献:
【1】http://www.enggjournals.com/ijcse/doc/IJCSE12-04-05-248.pdf
【2】http://www.cis.upenn.edu/~sudipto/mypapers/categorical.pdf
ROCK 聚类算法的更多相关文章
- 关于k-means聚类算法的matlab实现
在数据挖掘中聚类和分类的原理被广泛的应用. 聚类即无监督的学习. 分类即有监督的学习. 通俗一点的讲就是:聚类之前是未知样本的分类.而是根据样本本身的相似性进行划分为相似的类簇.而分类 是已知样本分类 ...
- DBSCAN密度聚类算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种很典型的密度聚类算法,和K-M ...
- 基于改进人工蜂群算法的K均值聚类算法(附MATLAB版源代码)
其实一直以来也没有准备在园子里发这样的文章,相对来说,算法改进放在园子里还是会稍稍显得格格不入.但是最近邮箱收到的几封邮件让我觉得有必要通过我的博客把过去做过的东西分享出去更给更多需要的人.从论文刊登 ...
- 挑子学习笔记:两步聚类算法(TwoStep Cluster Algorithm)——改进的BIRCH算法
转载请标明出处:http://www.cnblogs.com/tiaozistudy/p/twostep_cluster_algorithm.html 两步聚类算法是在SPSS Modeler中使用的 ...
- K-Means 聚类算法
K-Means 概念定义: K-Means 是一种基于距离的排他的聚类划分方法. 上面的 K-Means 描述中包含了几个概念: 聚类(Clustering):K-Means 是一种聚类分析(Clus ...
- BIRCH聚类算法原理
在K-Means聚类算法原理中,我们讲到了K-Means和Mini Batch K-Means的聚类原理.这里我们再来看看另外一种常见的聚类算法BIRCH.BIRCH算法比较适合于数据量大,类别数K也 ...
- K-Means聚类算法原理
K-Means算法是无监督的聚类算法,它实现起来比较简单,聚类效果也不错,因此应用很广泛.K-Means算法有大量的变体,本文就从最传统的K-Means算法讲起,在其基础上讲述K-Means的优化变体 ...
- FCM聚类算法介绍
FCM算法是一种基于划分的聚类算法,它的思想就是使得被划分到同一簇的对象之间相似度最大,而不同簇之间的相似度最小.模糊C均值算法是普通C均值算法的改进,普通C均值算法对于数据的划分是硬性的,而FCM则 ...
- 机器学习——利用K-均值聚类算法对未标注数据分组
聚类是一种无监督的学习,它将相似的对象归到同一簇中.它有点像全自动分类.聚类方法几乎可以应用到所有对象,簇内的对象越相似,聚类的效果越好. K-均值(K-means)聚类算法,之所以称之为K-均值是因 ...
随机推荐
- 关于 NPOI 报 Invalid column index (256). Allowable column range for BIFF8 is (0..255) or ('A'..'IV') 错误的解决办法
当看到这个错误的时候,网上搜索可以会有些说列数有限制之类的说法,这个说法是相对于 Office 2003 的,在 Office 2007 之前,最多只可以创建 列:在 Office 2007 之后, ...
- EAS linux挂载数据盘
查看数据盘名称 fdisk -l 假设没有挂载的数据盘为/dev/xvdb 格式化数据盘 mkfs.ext3 /dev/xvdb 添加自动挂载 mkdir /data echo '/dev/xvdb ...
- 底部tab的返回退出和对话框
第一种: private long exitTime = 0; @Override public boolean dispatchKeyEvent(KeyEvent event) { if (even ...
- jquery.fileupload插件的简易使用日志
来源:http://yixiandave.iteye.com/blog/1897330 本文内容主要包含fileupload插件传递参数和取回服务器返回数据的方法 jquery.fileupload官 ...
- js基本常识了解
http://www.cnblogs.com/Yue0327/p/5441773.html
- SharedPreferences的基本数据写入和读取
1.布局 <?xml version="1.0" encoding="utf-8"?> <LinearLayout xmlns:android ...
- 【iOS问题】The file “XXX.app” couldn’t be opened because you don’t have permission to view it.
当引入第三方的框架的时候 容易产生以下问题: The file "XXX.app" couldn't be opened because you don't have permis ...
- window的git extensions保存密码
git extensions每次pull与push均要输入密码,为解决该问题,执行以下操作: win+r,在运行中输入:%USERPROFILE% 找到其中的.gitconfig文件,找到[crede ...
- Excel表格常用的函数,留着备用
1. vlookup(lookup_value, table_array, col_index_num, boolean) -- 查找匹配函数 lookup_value: 你要去匹配的值 table_ ...
- C# HttpWebRequest与HttpWebResponse详解
C# HttpWebRequest与HttpWebResponse详解 http://www.codeproject.com/Articles/6554/How-to-use-HttpWebRequ ...