Django学习---快速搭建搜索引擎(haystack + whoosh + jieba)
Django下的搜索引擎(haystack + whoosh + jieba)
- 软件安装
haystack是django的开源搜索框架,该框架支持Solr,Elasticsearch,Whoosh, 搜索引擎量。
Whoosh是一个搜索引擎使用,这是一个由纯Python实现的全文搜索引擎,没有二进制文件等,比较小巧,配置比较简单,性能略低。
Jieba是由Whoosh自带的是英文分词,对中文的分词支持不是太好,故用jieba替换whoosh的分词组件。
---------------------
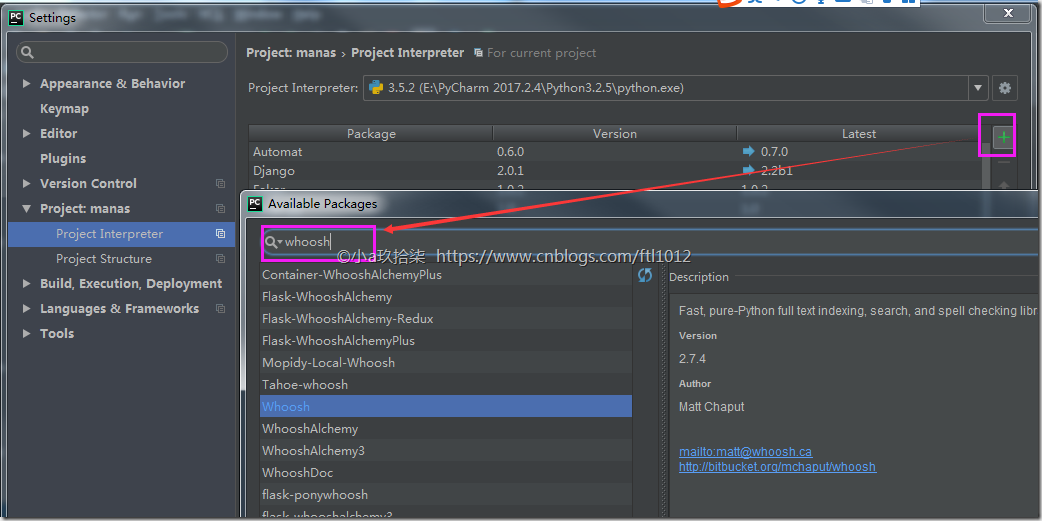
pip install django-haystack
pip install whoosh
pip install jieba
- 创建项目app
df_goods
- 修改settings.py:
manas/settings.py
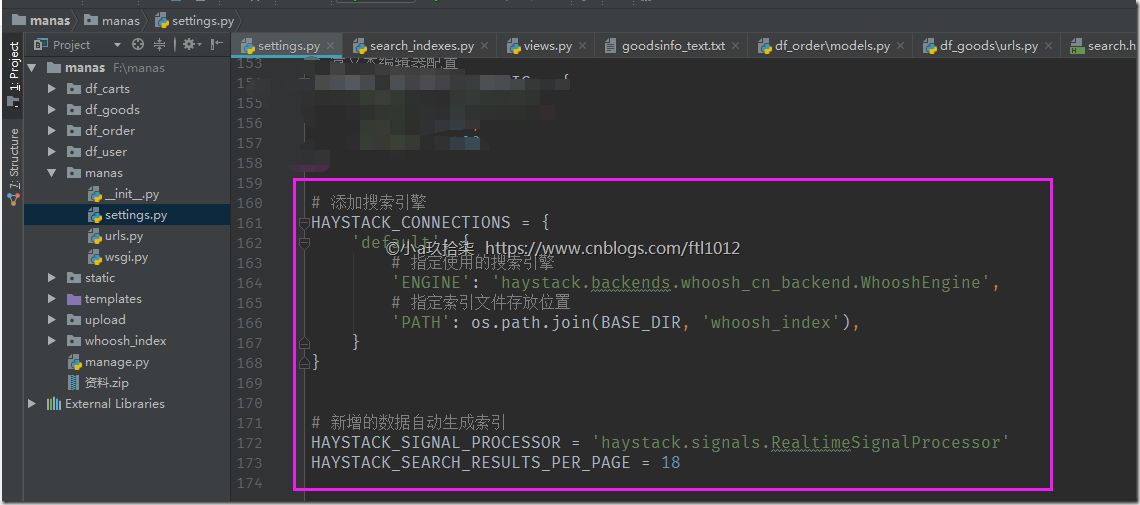
# 添加搜索引擎
HAYSTACK_CONNECTIONS = {
'default': {
# 指定使用的搜索引擎
'ENGINE': 'haystack.backends.whoosh_cn_backend.WhooshEngine',
# 指定索引文件存放位置
'PATH': os.path.join(BASE_DIR, 'whoosh_index'),
}
}
# 新增的数据自动生成索引
HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
HAYSTACK_SEARCH_RESULTS_PER_PAGE = 18
- 创建索引
在df_goods目录下简立search_indexes.py文件,文件名不能修改
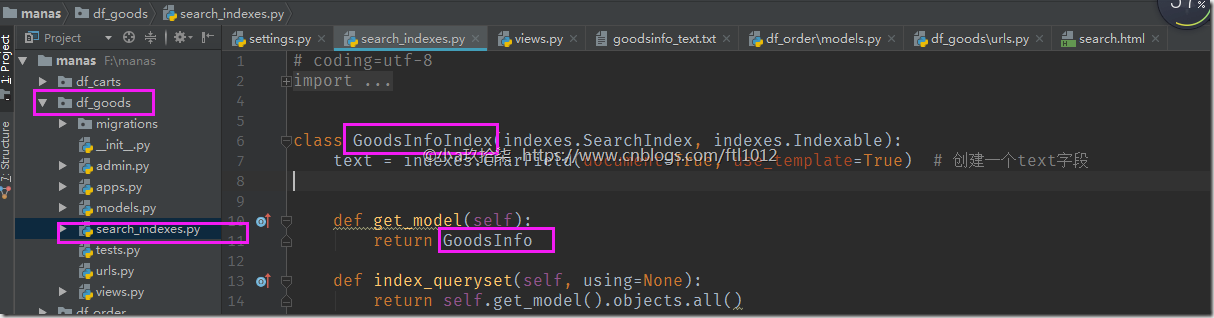
# coding=utf-8
from haystack import indexes
from .models import GoodsInfo class GoodsInfoIndex(indexes.SearchIndex, indexes.Indexable):
text = indexes.CharField(document=True, use_template=True) # 创建一个text字段 def get_model(self):
return GoodsInfo def index_queryset(self, using=None):
return self.get_model().objects.all()
说明: 每个索引里面必须有且只能有一个字段为 document=True,这代表haystack 和搜索引擎将使用此字段的内容作为索引进行检索(primary field)。其他的字段只是附属的属性,方便调用,并不作为检索数据。如果使用一个字段设置了document=True,则一般约定此字段名为text,这是在SearchIndex类里面一贯的命名,以防止后台混乱,当然名字你也可以随便改,不过不建议改。并且,haystack提供了use_template=True在text字段,这样就允许我们使用数据模板去建立搜索引擎索引的文件,说得通俗点就是索引里面需要存放一些什么东西,例如 GoodsInfo的 gtitle 字段
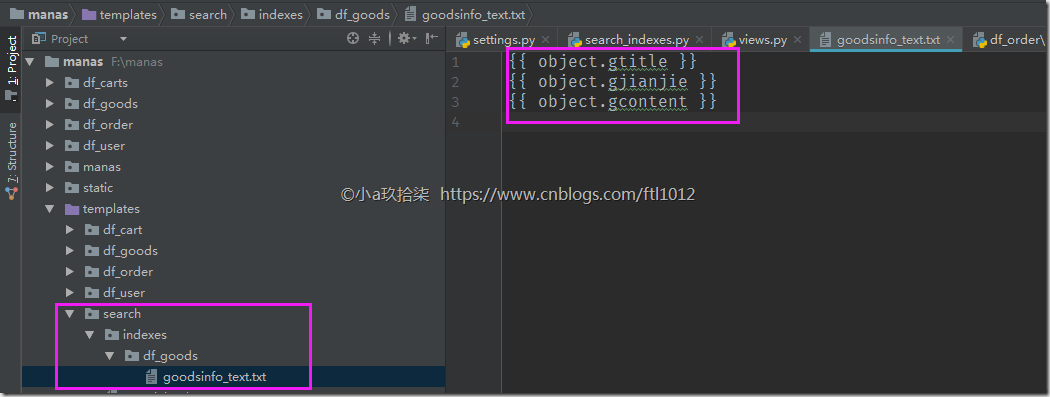
- 创建数据模板路径
templates/search/indexes/df_goods/goodsinfo_text.txt
说明: 数据模板的路径一般为: templates/search/indexes/yourapp/note_text.txt格式
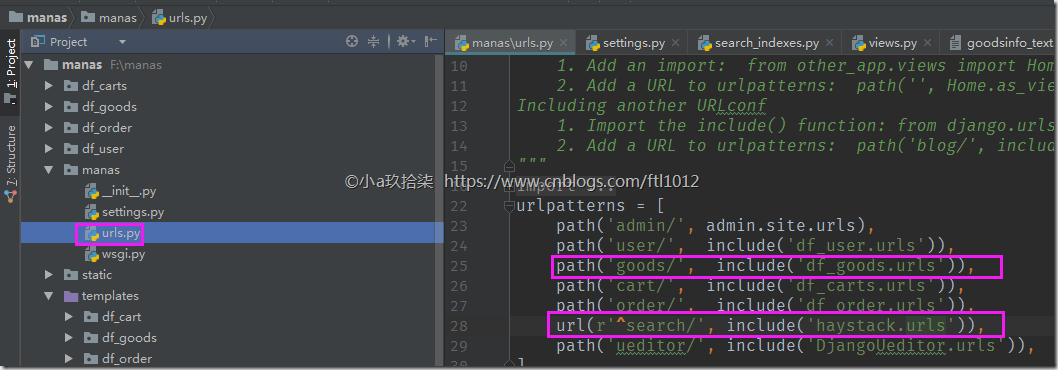
- 配置URL
manas/urls.py
df_goods/urls.py
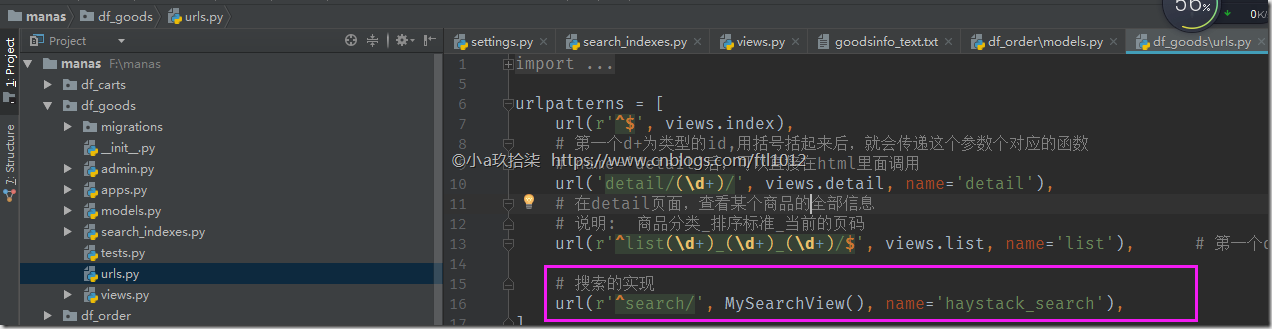
df_goods/views.py
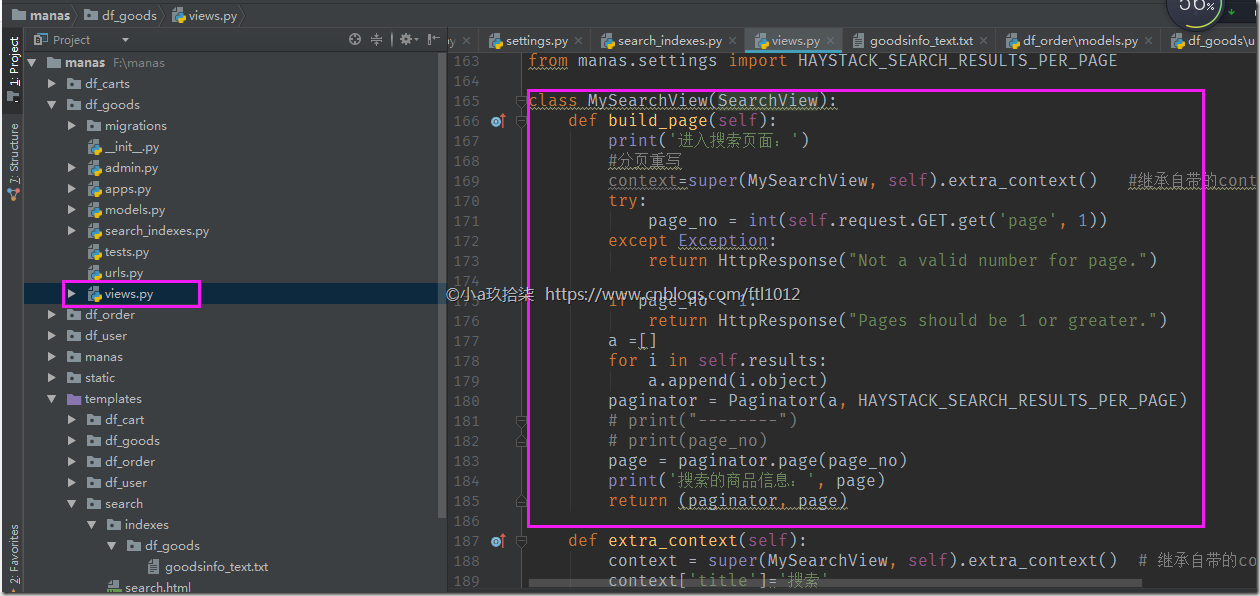
from haystack.views import SearchView
from manas.settings import HAYSTACK_SEARCH_RESULTS_PER_PAGE class MySearchView(SearchView):
def build_page(self):
print('进入搜索页面:')
#分页重写
context=super(MySearchView, self).extra_context() #继承自带的context
try:
page_no = int(self.request.GET.get('page', 1))
except Exception:
return HttpResponse("Not a valid number for page.") if page_no < 1:
return HttpResponse("Pages should be 1 or greater.")
a =[]
for i in self.results:
a.append(i.object)
paginator = Paginator(a, HAYSTACK_SEARCH_RESULTS_PER_PAGE)
# print("--------")
# print(page_no)
page = paginator.page(page_no)
print('搜索的商品信息:', page)
return (paginator, page) def extra_context(self):
context = super(MySearchView, self).extra_context() # 继承自带的context
context['title']='搜索'
return context
创建搜索结果显示的HTML模板路径
templates/search/search.html
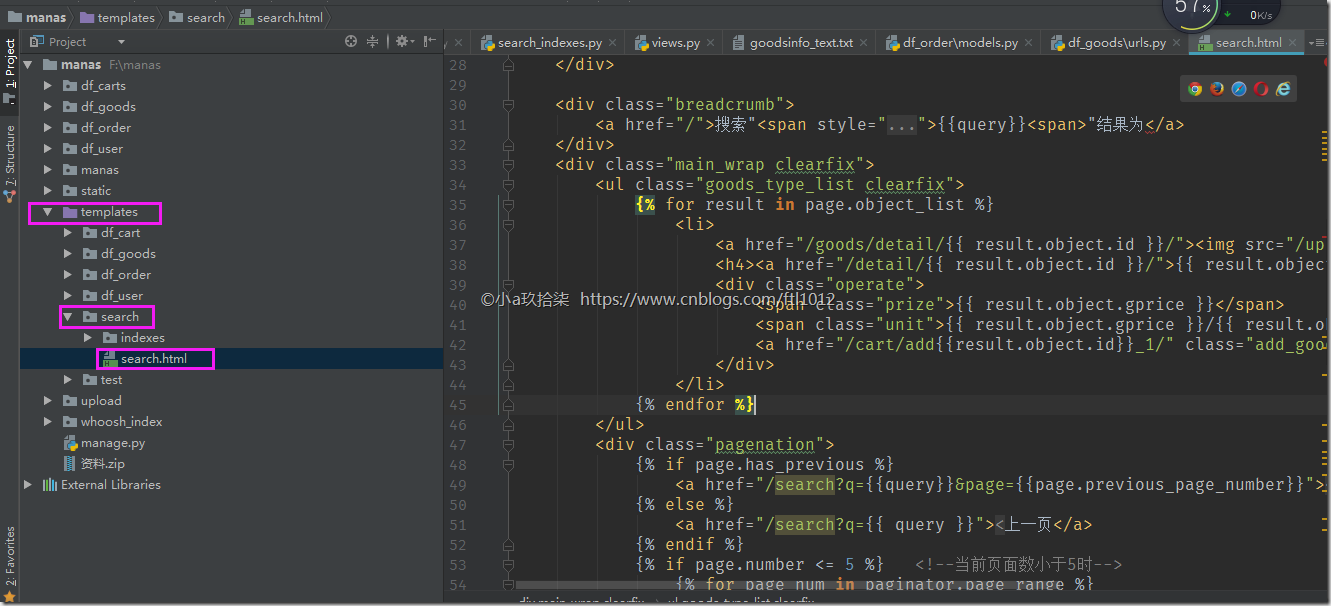
SearchView()视图函数默认使用的html模板路径为templates/search/search.html
<ul class="goods_type_list clearfix">
{% for result in page.object_list %}
<li>
<a href="/goods/detail/{{ result.object.id }}/"><img src="/upload/{{ result.object.gpic }}"></a>
<h4><a href="/detail/{{ result.object.id }}/">{{ result.object.gtitle }}</a></h4>
<div class="operate">
<span class="prize">{{ result.object.gprice }}</span>
<span class="unit">{{ result.object.gprice }}/{{ result.object.gunit }}</span>
<a href="/cart/add{{result.object.id}}_1/" class="add_goods" title="加入购物车"></a>
</div>
</li>
{% endfor %}
</ul>
<div class="pagenation">
{% if page.has_previous %}
<a href="/search?q={{query}}&page={{page.previous_page_number}}"><上一页</a>
{% else %}
<a href="/search?q={{ query }}"><上一页</a>
{% endif %}
{% if page.number <= 5 %} <!--当前页面数小于5时-->
{% for page_num in paginator.page_range %}
{%if forloop.counter <= 5 %}
<a href="/search?q={{query}}&page={{page_num}}"
{% if page.number == page_num %}
class="active"
{% endif %}
>{{ page_num }}</a>
{%endif%}
{% endfor %}
{% else %}
{% if page.number|add:1 > paginator.num_pages %}
<a href="/search?q={{query}}&page={{page.number|add:-4}}">{{ page.number|add:-4}}</a>
{% endif %}
{% if page.number|add:2 > paginator.num_pages %}
<a href="/search?q={{query}}&page={{page.number|add:-3}}">{{ page.number|add:-3}}</a>
{% endif %}
<a href="/search?q={{query}}&page={{page.number|add:-2}}" >{{ page.number|add:-2}}</a>
<a href="/search?q={{query}}&page={{page.number|add:-1}}">{{ page.number|add:-1}}</a>
<a href="/search?q={{query}}&page={{page.number}}" class="active">{{ page.number }}</a>
{% if page.number|add:1 <= paginator.num_pages %}
<a href="/search?q={{query}}&page={{page.number|add:1}}">{{ page.number|add:1}}</a>
{% endif %}
{% if page.number|add:2 <= paginator.num_pages %}
<a href="/search?q={{query}}&page={{page.number|add:2}}">{{ page.number|add:2}}</a>
{% endif %}
{% endif %} {% if page.has_next %}
<a href="/search?q={{query}}&page={{page.next_page_number}}">下一页></a>
{% else %}
<a href="/search?q={{query}}&page={{paginator.num_pages}}">下一页></a>
{% endif %}
</div>
</div>
{% endblock body %}
说明:首先可以看到模板里使用了的变量有query,page,paginator。query就是我们搜索的字符串; page就是我们的返回结果,page有object_list属性。
- 创建搜索引擎文件夹whoosh_index(settings.py已配置)

- 创建ChineseAnalyzer.py文件
- 保存在haystack的安装文件夹下,Linux路径如“/home/python/.virtualenvs/django_py2/lib/python2.7/site-packages/haystack/backends”
- 保存在haystack的安装文件,Window路径 C:\Users\Administrator\AppData\Roaming\Python\Python35\site-packages\haystack\backends.
import jieba
from whoosh.analysis import Tokenizer, Token class ChineseTokenizer(Tokenizer):
def __call__(self, value, positions=False, chars=False,
keeporiginal=False, removestops=True,
start_pos=0, start_char=0, mode='', **kwargs):
t = Token(positions, chars, removestops=removestops, mode=mode,
**kwargs)
seglist = jieba.cut(value, cut_all=True)
for w in seglist:
t.original = t.text = w
t.boost = 1.0
if positions:
t.pos = start_pos + value.find(w)
if chars:
t.startchar = start_char + value.find(w)
t.endchar = start_char + value.find(w) + len(w)
yield t def ChineseAnalyzer():
return ChineseTokenizer()
添加中文搜索文件
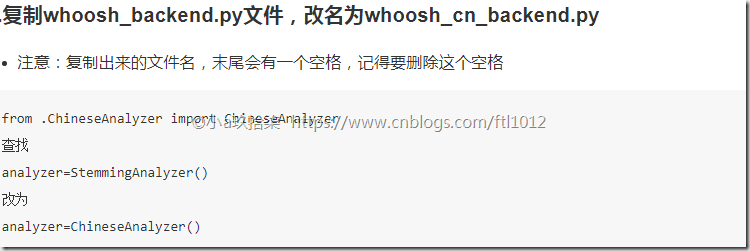
修改完成后2个文件的对比

- 生成索引
python manage.py rebuild_index(可选更新索引)python manage.py update_index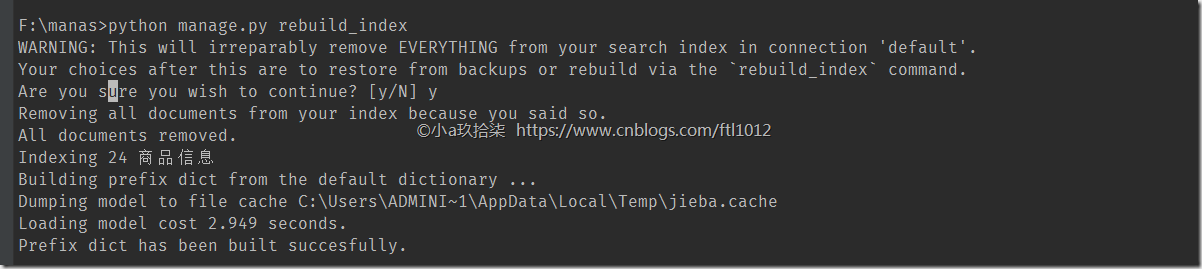
- 界面显示
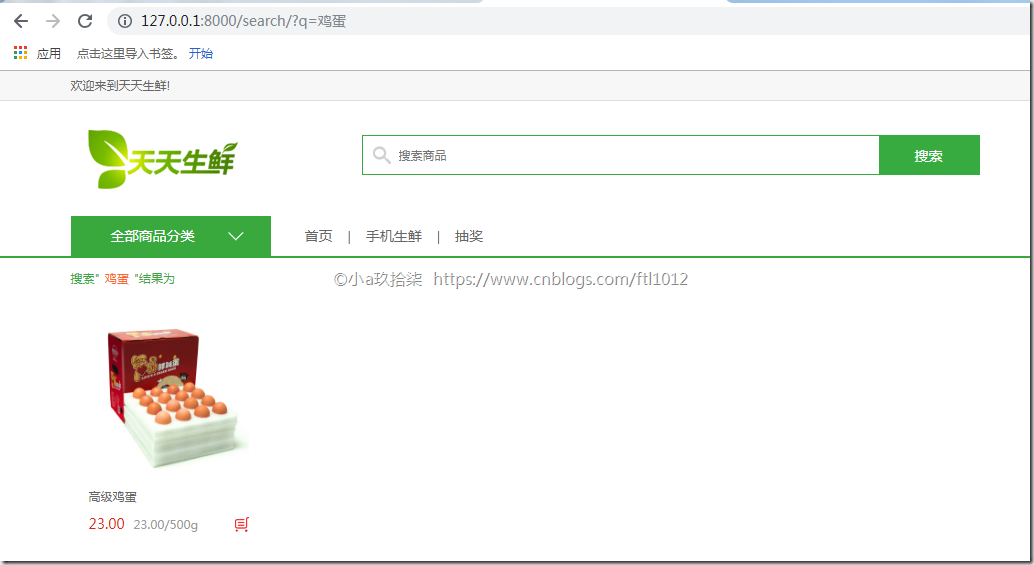
说明:如果我们的文字描述比较少,就会导致分词的效果不明显,所以建议文字描述的时候多一些,这样便于jieba分词
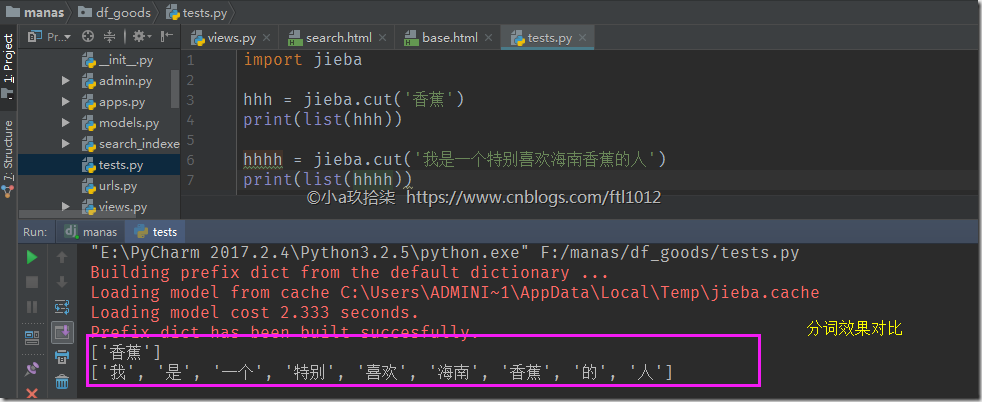
附带分词文件下载;
jieba的简单实用
import jieba
list0 = jieba.cut('小明硕士毕业于中国科学院计算所,后在哈佛大学深造', cut_all=True)
print('全模式', list(list0))
# ['小', '明', '硕士', '毕业', '于', '中国', '中国科学院', '科学', '科学院', '学院', '计算', '计算所', '', '', '后', '在', '哈佛', '哈佛大学', '大学', '深造']
list1 = jieba.cut('小明硕士毕业于中国科学院计算所,后在哈佛大学深造', cut_all=False)
print('精准模式', list(list1))
# ['小明', '硕士', '毕业', '于', '中国科学院', '计算所', ',', '后', '在', '哈佛大学', '深造']
list2 = jieba.cut_for_search('小明硕士毕业于中国科学院计算所,后在哈佛大学深造')
print('搜索引擎模式', list(list2))
# ['小明', '硕士', '毕业', '于', '中国', '科学', '学院', '科学院', '中国科学院', '计算', '计算所', ',', '后', '在', '哈佛', '大学', '哈佛大学', '深造']
Django学习---快速搭建搜索引擎(haystack + whoosh + jieba)的更多相关文章
- 一.Django 学习 —— 环境搭建
Ⅰ.前言 Django是一个开放源代码的Web应用框架,由Python写成.采用了MVC的框架模式,即模型M,视图V和控制器C. 我们先搭建一个Django项目运行的环境. 需要准备的有: 1- Py ...
- Django + mysql 快速搭建简单web投票系统
了解学习pyhton web的简单demo 1. 安装Django, 安装pyhton 自行百度 2. 执行命令创建project django-admin.py startproject mysi ...
- django学习笔记——搭建博客网站
1. 配置环境,创建django工程 虚拟环境下建立Django工程,即创建一个包含python脚本文件和django配置文件的目录或者文件夹,其中manage.py是django的工程管理助手.(可 ...
- django 学习 --- 环境搭建
1 安装django a: pip安装 pip install Django==版本号 b:源码安装 https://www.djangoproject.com/download/ tar -xvzf ...
- [vue学习]快速搭建一个项目
安装node.js 官网:https://nodejs.org/en/ 淘宝NPM镜像(npm是外网,用国内代理下载安装贼快) $ npm install -g cnpm --registry=htt ...
- Electron入门笔记(一)-自己快速搭建一个app demo
Electron学习-快速搭建app demo 作者: 狐狸家的鱼 Github: 八至 一.安装Node 1.从node官网下载 ,最好安装.msi后缀名的文件,新手可以查看安装教程进行安装. 2. ...
- django 快速搭建blog
如果本文看不懂的,去看的我视频吧!http://www.testpub.cn/ ------------------------------------------- Django 自称是“最适合开发 ...
- Django学习笔记 开发环境搭建
为什么使用django?1.支持快速开发:用python开发:数据库ORM系统,并不需要我们手动地构造SQL语句,而是用python的对象访问数据库,能够提升开发效率.2.大量内置应用:后台管理系统a ...
- 30分钟快速搭建Web CRUD的管理平台--django神奇魔法
加上你的准备的时间,估计30分钟完全够用了,因为最近在做爬虫管理平台,想着快速开发,没想到python web平台下有这么非常方便的框架,简洁而优雅.将自己的一些坑总结出来,方便给大家的使用. 准备环 ...
随机推荐
- Spring Boot + Spring Cloud 实现权限管理系统 后端篇(十三):系统备份还原
系统备份还原 在很多时候,我们需要系统数据进行备份还原.我们这里就使用MySql的备份还原命令实现系统备份还原的功能. 新建工程 新建一个maven项目,并添加相关依赖,可以用Spring boot脚 ...
- 和我一起打造个简单搜索之SpringDataElasticSearch关键词高亮
前面几篇文章详细讲解了 ElasticSearch 的搭建以及使用 SpringDataElasticSearch 来完成搜索查询,但是搜索一般都会有搜索关键字高亮的功能,今天我们把它给加上. 系列文 ...
- Python NumPy学习总结
一.NumPy简介 其官网是:http://www.numpy.org/ NumPy是Python语言的一个扩充程序库.支持高级大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库.Num ...
- ZOJ 1456 Minimum Transport Cost(Floyd算法求解最短路径并输出最小字典序路径)
题目链接: https://vjudge.net/problem/ZOJ-1456 These are N cities in Spring country. Between each pair of ...
- [总结] LCT学习笔记
\(emmm\)学\(lct\)有几天了,大概整理一下这东西的题单吧 (部分参考flashhu的博客) 基础操作 [洛谷P1501Tree II] 题意 给定一棵树,要求支持 链加,删边加边,链乘,询 ...
- DotNetty项目基本了解和介绍
一.DotNetty背景介绍 DotNetty是微软的Azure团队,使用C#实现的Netty的版本发布.不但使用了C#和.Net平台的技术特点,并且保留了Netty原来绝大部分的编程接口.让我们在使 ...
- 如何为你的树莓派安装一个WIN10系统?(非iot)
Windows10 ARM版,是的,这次并非IoT版,而是功能与PC一致的ARM版.需要注意的是,这个方法并非官方提供的,可用性上会有一些坑,热衷于尝试的玩家可以一试! 准备项目:树莓派3B以上型号, ...
- C# .aspx 页面更换命名空间
1.选中命名空间,右键单击,选择重构,之后选择重命名.如下图: 2.弹出重命名对话框 3.重写你需要的名字,点击确定. 4.这里重点注意了,不可直接点击应用,否则你会后悔的.你必须对应的看看那个是否是 ...
- C# 分支语句 练习题(中间变量,随机数)
练习一 请输入年份:”(1-9999),请输入月份:”(1-12),请输入日期(要判断大小月,判断闰年),判断输入的时间日期是否正确. 计算输入的时间是当前这一年的第几天. bool dateISOK ...
- IBatisNet动态update以及DateTime类型字段处理
在维护一个老项目中碰到的问题.SQL配置如下(只简单列出两个字段): <update id="ProjectInfo.Update" parameterClass=" ...