02Spark的左连接
两个文件,一个是用户的数据,一个是交易的数据。
用户:
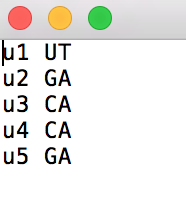
交易:
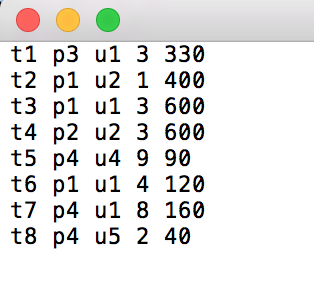
流程如下:
分为以下几个步骤: (1)分别读取user文件和transform文件,并转为两个RDD.
* (2)对上面两个RDD执行maptopair操作。生成userpairRdd和transformpairRdd
* (3)对transformpairRdd和userpairRdd执行union操作,就是把上面的数据放在一起,生成allRdd
* (4)然后把allRdd用groupBykey分组,把同一个UserID的数据都放在一起。生成groupRdd。
* (5)对grouprdd处理,生成productLoctionRdd:(p1,UT),(p2,UT)这种productlistRdd。
* (6)productlistRdd这里面有数据重复,需要去重。
代码结构:

代码:
package com.test.book; import java.util.ArrayList;
import java.util.HashSet;
import java.util.Iterator;
import java.util.List;
import java.util.Set; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.PairFlatMapFunction;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2; public class LeftJoinCmain { /*
* 分为以下几个步骤: (1)分别读取user文件和transform文件,并转为RDD.
* (2)对上面两个RDD执行maptopair操作。生成userpairRdd和transformpairRdd
* (3)对transformpairRdd和userpairRdd执行union操作,就是把上面的数据放在一起,生成allRdd
* (4)然后把allRdd用groupBykey分组,把同一个UserID的数据都放在一起。生成groupRdd。
* (5)对grouprdd处理,生成productLoctionRdd:(p1,UT),(p2,UT)这种productlistRdd。
* (6)productlistRdd这里面有数据重复,需要去重。
*
*/ public static void main(String[] args) { SparkConf conf = new SparkConf().setAppName("LeftJoinCmain").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
// 导入user的数据
JavaRDD<String> user = sc.textFile("/Users/mac/Desktop/user.txt");
// 导入transform的数据
JavaRDD<String> transform = sc.textFile("/Users/mac/Desktop/transactions.txt"); // 生成一个JavaPairRDD,KEY是uerID,Value是Tuple的形式,("L",地址)
JavaPairRDD<String, Tuple2<String, String>> userpairRdd = user
.mapToPair(new PairFunction<String, String, Tuple2<String, String>>() { /**
*
*/
private static final long serialVersionUID = 1L; @Override
public Tuple2<String, Tuple2<String, String>> call(String line) throws Exception {
String[] args = line.split(" ");
return new Tuple2<String, Tuple2<String, String>>(args[0],
new Tuple2<String, String>("L", args[1]));
} }); // 生成一个transform,
JavaPairRDD<String, Tuple2<String, String>> transformpairRdd = transform
.mapToPair(new PairFunction<String, String, Tuple2<String, String>>() { /**
*
*/
private static final long serialVersionUID = 1L; @Override
public Tuple2<String, Tuple2<String, String>> call(String line) throws Exception {
String[] args = line.split(" "); return new Tuple2<String, Tuple2<String, String>>(args[2],
new Tuple2<String, String>("P", args[1]));
}
}); /**
* allRdd的格式是: { (userID,Tuple("L","UT")), (userID,Tuple("P","p3")) . . . }
*/
JavaPairRDD<String, Tuple2<String, String>> allRdd = userpairRdd.union(transformpairRdd); /**
* 这一步就是把同一个uerID的数据放在一起,结果是: (userID1,List[(Tuple2("L","UT"),//一个用户地址信息
* Tuple2("P","p1"),//其他的都是商品信息 Tuple2("P","p2") ] )
*/
JavaPairRDD<String, Iterable<Tuple2<String, String>>> groupRdd = allRdd.groupByKey(); /**
* 这一步就是从groupRdd中去掉userID,生成productLoctionRdd:(p1,UT),(p2,UT)这种。
*
*/ JavaPairRDD<String, String> productlistRdd = groupRdd.flatMapToPair(
new PairFlatMapFunction<Tuple2<String, Iterable<Tuple2<String, String>>>, String, String>() { @Override
public Iterable<Tuple2<String, String>> call(Tuple2<String, Iterable<Tuple2<String, String>>> t)
throws Exception { String location = "UNKNOWN";
Iterable<Tuple2<String, String>> pairs = t._2;
List<String> products = new ArrayList<String>();
for (Tuple2<String, String> pair : pairs) { if (pair._1.equals("L"))
location = pair._2;
if (pair._1.equals("P")) {
products.add(pair._2);
} } List<Tuple2<String, String>> kvList = new ArrayList<Tuple2<String, String>>(); for (String product : products) {
kvList.add(new Tuple2<String, String>(product, location)); }
return kvList;
}
}); // 把一个商品的所有地址都查出来 JavaPairRDD<String, Iterable<String>> productbylocation = productlistRdd.groupByKey();
List<Tuple2<String, Iterable<String>>> debug3 = productbylocation.collect(); for (Tuple2<String, Iterable<String>> value : debug3) { Iterator<String> iterator = value._2.iterator(); while (iterator.hasNext()) {
System.out.println(value._1 + ":" + iterator.next());
} } /**
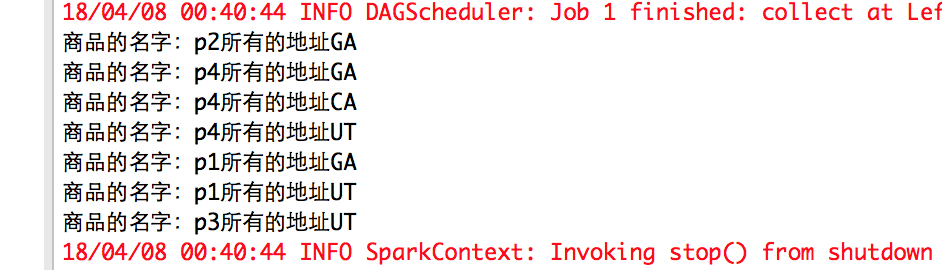
* 上述代码经过调试, 结果如下: p2:GA p4:GA p4:UT p4:CA p1:UT p1:UT p1:GA p3:UT
*
*
* 发现有相同的商品和地址。我们需要把这个重复的结果去除。
*/
// 处理如下:我们用mapvalues()函数 JavaPairRDD<String, Tuple2<Set<String>, Integer>> productByuniqueLocation = productbylocation
.mapValues(new Function<Iterable<String>, Tuple2<Set<String>, Integer>>() { @Override
public Tuple2<Set<String>, Integer> call(Iterable<String> v1) throws Exception {
Set<String> uniquelocations = new HashSet<String>(); Iterator<String> iterator = v1.iterator(); while (iterator.hasNext()) { String value = iterator.next();
uniquelocations.add(value); } // 返回一个商品的所有地址,以及地址的个数。
return new Tuple2<Set<String>, Integer>(uniquelocations, uniquelocations.size());
}
}); List<Tuple2<String, Tuple2<Set<String>, Integer>>> finalresult = productByuniqueLocation.collect();
for (Tuple2<String, Tuple2<Set<String>, Integer>> vTuple2 : finalresult) { String aa=vTuple2._1;
Iterator<String> iterator=vTuple2._2._1.iterator();
while(iterator.hasNext())
{
System.out.println("商品的名字:"+aa+"所有的地址"+iterator.next()); } } } }
运行结果:

去重后的结果:
02Spark的左连接的更多相关文章
- mysql 内连接、左连接、右连接
记录备忘下,初始数据如下: DROP TABLE IF EXISTS t_demo_product; CREATE TABLE IF NOT EXISTS t_demo_product( proid ...
- 《Entity Framework 6 Recipes》中文翻译系列 (16) -----第三章 查询之左连接和在TPH中通过派生类排序
翻译的初衷以及为什么选择<Entity Framework 6 Recipes>来学习,请看本系列开篇 3-10应用左连接 问题 你想使用左外连接来合并两个实体的属性. 解决方案 假设你有 ...
- 数据库中的左连接(left join)和右连接(right join)区别
Left Join / Right Join /inner join相关 关于左连接和右连接总结性的一句话: 左连接where只影向右表,右连接where只影响左表. Left Join select ...
- MySQL的左连接、右连接和全连接的实现
表student:+----+-----------+------+| id | name | age |+----+-----------+------+| 1 | Jim | 18 || 2 | ...
- Oracle 左连接、右连接、全外连接、(+)号作用
分类: Oracle Oracle 外连接 (1)左外连接 (左边的表不加限制) (2)右外连接(右边的表不加限制) (3)全外连接(左右两表都不加限制) 外连接(Outer ...
- Linq连接查询之左连接、右连接、内连接、全连接、交叉连接、Union合并、Concat连接、Intersect相交、Except与非查询
内连接查询 内连接与SqL中inner join一样,即找出两个序列的交集 Model1Container model = new Model1Container(); //内连接 var query ...
- LINQ的左连接、右连接、内连接
.左连接: var LeftJoin = from emp in ListOfEmployees join dept in ListOfDepartment on emp.DeptID equals ...
- 数据库左连接left join、右连接right join、内连接inner join on 及 where条件查询的区别
join on 与 where 条件的执行先后顺序: join on 条件先执行,where条件后执行:join on的条件在连接表时过滤,而where则是在生成中间表后对临时表过滤 left joi ...
- SQL Server中的连接查询【内连接,左连接,右连接,。。。】
在查询多个表时,我们经常会用“连接查询”.连接是关系数据库模型的主要特点,也是它区别于其它类型数据库管理系统的一个标志. 什么是连接查询呢? 概念:根据两个表或多个表的列之间的关系,从这些表中查询数据 ...
随机推荐
- 小型资源管理器之动态添加TreeView节点
FrmMain主界面 using System; using System.Collections.Generic; using System.ComponentModel; using System ...
- [CF49E]Common ancestor
[CF49E]Common ancestor 题目大意: 有两个由小写字母构成的字符串\(S\)和\(T(|S|,|T|\le50)\).另有\(n(n\le50)\)个形如\(a\to bc\)的信 ...
- ReactNative用指定的真机/模拟器运行项目
使用模拟器运行项目: 命令行中React native项目目录下键入react-native run-ios会启动iOS模拟器, 默认是使用iPhone6,如果想要试用其他版本的模拟器则需要在reac ...
- tableview分割线
默认分割线,左边不到屏幕: TableView.separatorStyle = UITableViewCellSeparatorStyleSingleLine; 三种结构体样式: /** UITab ...
- 词向量保存为txt
model.wv.save_word2vec_format('w2v_mod.txt',binary=False)
- openstack之~glance安装部署
接着部署完keystone后,接着部署glance 第一:部署安装glance glance关于数据库的操作: [root@controller /]# mysql -u root -p Enter ...
- poj3104 Drying(二分最大化最小值 好题)
https://vjudge.net/problem/POJ-3104 一开始思路不对,一直在想怎么贪心,或者套优先队列.. 其实是用二分法.感觉二分法求最值很常用啊,稍微有点思路的二分就是先推出公式 ...
- C# Xamarin移动开发基础进修篇
一.课程介绍 英文原文:C# is the best language for mobile app development. Anything you can do in Objective-C, ...
- Css3实现波浪效果2
一.不规则圆,旋转实现波浪效果 .info { width: 200px; height: 200px; ; background: #009A61; border-radius: 45%; colo ...
- GoogLeNet 解读
GoogLeNet系列解读 2016年02月25日 15:56:29 shuzfan 阅读数:75639更多 个人分类: 深度学习基础 版权声明:本文为博主原创文章,转载请注明出处 https: ...