join算法分析
对于单条语句,explain看下key,加个索引
多个条件,加复合索引
where a = ? order by b 加(a,b)的复合索引
上面都是比较基本的,这篇我们分析一些复杂的情况——join的算法
如下两张表做join
10w 100w
tb R tb S
r1 s1
r2 s2
r3 s3
... ...
rN sN
Ⅰ、nested_loop join
1.1、simple nested_loop join 这个在数据库中永远不会使用
For each row r in R do
For each row s in S do
If r and s satisfy the join condition
Then output the tuple <r,s>
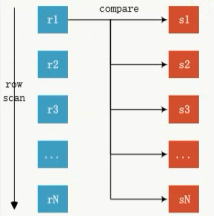
扫描成本 O(Rn*Sn),也就是笛卡儿积
1.2、index nested_loop join 最推荐
For each row r in R do
lookup in S index
if found s == row
Then output the tuple<r,s>
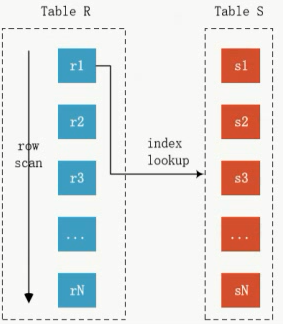
扫描成本 O(Rn)
优化器倾向于使用小表做驱动表,内表上创建索引即可
select * from a,b where a.x=b.y
a中的每条记录,去b上面的index(y)中去找这个x的记录,a表和b表,哪个是R,哪个是S
R:驱动表(外表) S:内表
对于inner join,a b 和 b a join出来结果一样,用的索引来查询,100w和1000w扫描成本都一样,都是外表的行数,所以只要驱动表越小,优化器就倾向于用它做驱动表
对于left join,左表要全表扫描所有记录,所以一定是驱动表
比如,一列10w行,另一列100w行,优化器会喜欢把10w的这一列做外表,然后在100w的列上建索引,外表只要扫描10w次,假设100w记录索引B+ tree高度是3,那一共就是10w * 3次io操作,反过来,就是100w * 3次,所以,mysql只要两张表关联,非常建议两张表上一定要有索引,索引应该创建在S表上,也就是大表,如果索引加反了,这时候100w的表就成了驱动表
但是线上肯定不会直接两张表关联,where后面还有很多过滤条件,优化器会把这些条件考虑进去,过滤掉这些条件,看哪张表示小表就是驱动表,但是索引有倾斜,优化器在选择上可能会出错
1.3 block nested_loop join 两张表上没有索引的时候才会使用的算法
用来优化simle nested_loop join,减少内部表的扫描次数
For each tuple r in R do
store used columns as p from R in join buffer
For each tuple s in S do
if p and s satisfy the join condition
Then output the tuple <p,s>
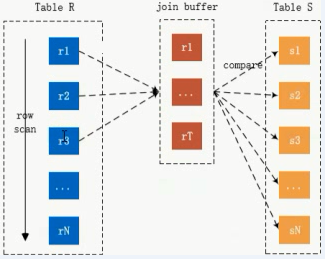
加一个内存,join_buffer_size变量,空间换时间,这个变量决定了Join Buffer的大小
Join Buffer可被用于联接是ALL,index,range的类型
Join Buffer只存储需要进行查询操作的相关列数据(要关联的列),而不是整行的记录(千万要记住),所以总的来说还是蛮高效的,
扫描成本呢?和simple一样
Table R join buffer Table S
将多条R中的记录一下子放到join buffer中,join buffer 一次性和Table S中每条记录进行比较,这样来减少内表的扫描次数,假设join buffer足够大,大到能把驱动表中所有记录cache起来,那这样就只要扫一次内表
举例:
A B
1 1
2 2
3 3
4
外 内
SNLP BNLP
外表扫描次数 1 1
内表扫描次数 3 1
比较次数 12 12
综上:比较次数是节省不下来的
如果是百万级别,mysql勉强可以跑出来结果,调优的话,不谈索引,我们就要调大join_buffer_size这个参数,默认256k,如果这个列是8个字节,256k显然存不下太多记录,这个参数可以调很大,但是不要过分了,不然机器内存不够,数据库挂了就不好了,一般来说1g最大了
join_buffer_size是私有的,每个线程可以用的内存大小
网上有个特别错误的观点,mysql加速join查询,加大join_buffer_size。这个是两张表关联没有索引用这个方法才有用,你有了索引,再怎么加大这个参数也没用
本身也不太建议用这个算法,除非某些特殊的查询用不到索引,或者当时没建索引,这是个临时处理方法,比较次数是笛卡儿积啊 我的天那,如何把这个比较次数降下来呢?
tips:
1、不知道哪个表是驱动表,那就简单点,两个关联的表的相关列都加索引,让优化器自己选择
2、oracle中百万级别的表进行关联,用index nested_loop join,千万级以上用hash join这个说法怎么看?心法口诀是什么
3、join如果有索引,为什么千万级别的join不行?这句话是错的,是可以的,只是速度很慢罢了,主要就是因为要回表
select max(l_extendedprice) from orders,lineitem
where o_orderdate betweent '1995-01-01' and '1995-01-31' and
l_orderkey=o_orderkey;
join的列不是主键,这种类型的查询就是基于索引的,join不太适用的场景
看一个问题
(root@localhost) [dbt3]> explain select * from orders where o_orderdate > '1997-01-01';
+----+-------------+--------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| 1 | SIMPLE | orders | NULL | ALL | i_o_orderdate | NULL | NULL | NULL | 1483643 | 50.00 | Using where |
+----+-------------+--------+------------+------+---------------+------+---------+------+---------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
(root@localhost) [dbt3]> explain select * from orders where o_orderdate > '1999-01-01';
+----+-------------+--------+------------+-------+---------------+---------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+---------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | orders | NULL | range | i_o_orderdate | i_o_orderdate | 4 | NULL | 1 | 100.00 | Using index condition |
+----+-------------+--------+------------+-------+---------------+---------------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
为什么第一条sql没走索引第二条走了呢?
这不是优化器不稳定,这个索引是一个二级索引,现在select * 所以要回表,回表对于我们这个sql来说,假设通过索引定位到回表的记录一共是50w条(表一共是150w条记录,每条记录大小是100字节),那就要回表50w次,大约是50w次io(看B+ tree 高度,这里假设高度就是1)
如果不走索引,直接扫150w行主键一共需要150w/(16k/100)次io(每行大小100字节,一个页就是16k/100条记录,150w除以这个值,就是一共的记录数),到这里看基本上就是1w次io,这就是优化器没走索引的原因,而且,回表用的io是随机的,扫主键用的是顺序io,后者比前者最起码快十倍
另外,这个选择肯定是基于cost的,但不要追究cost,官方没有说明cost是怎么计算的,通过源码可以看出一点,但是5.7版本又不一样了
那针对这种情况我们应该如何优化呢?——MRR(5.7之后才有,和oracle一样)
(root@localhost) [dbt3]> explain select /* +MRR(orders) */ * from orders where o_orderdate > '1998-01-01';
+----+-------------+--------+------------+-------+---------------+---------------+---------+------+--------+----------+----------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+---------------+---------+------+--------+----------+----------------------------------+
| 1 | SIMPLE | orders | NULL | range | i_o_orderdate | i_o_orderdate | 4 | NULL | 317654 | 100.00 | Using index condition; Using MRR |
+----+-------------+--------+------------+-------+---------------+---------------+---------+------+--------+----------+----------------------------------+
1 row in set, 1 warning (0.22 sec)
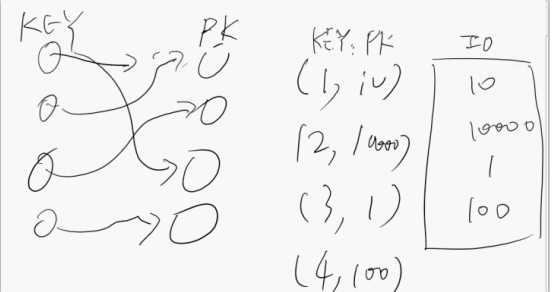
MRR:Multi-Range-Read:多范围的read,空间换时间,解决回表的性能问题
随机io回表,不能保证key和pk都是顺序的,对于二级索引来说它的key是排序了,但是不能保证里面保存的pk也排序了
所以现在弄了个内存,把这个二级索引里面的pk都放进去,等放不下了,去sort一把,然后再去回表,这时候io就比较顺序了,这样通过随机转顺序做了个优化
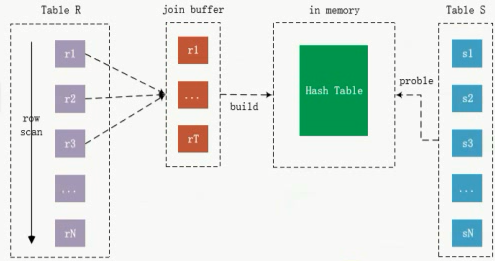
Ⅱ、classic hash join
把外表中的数据放到一个内存中,放进去之后不是直接去和内表比较,对内存中的列创建了一个hash表,然后再扫描内表,内表中的每条记录去探测hash表,通常查一个记录只要探测一次
A B
1 1
2 2
3 3
4
外表扫1次,内表扫1次,比较次数是4(S表去hash表中探测),走索引的话也是1 1 4,看起来哈希和索引看起来成本一样,hash不用创建索引,不用回表
hash join 就不存在回表的问题,还可以用来做并发,如果join要回表,用基于索引的方式做join算法效率比较差,对于oracle的话,hash join就会好非常多
hash join有个缺点是只支持等值的查询,A.x=B.y >= 这种就歇菜了,不过通常join也是等值查询
听说8.0会支持
Ⅲ、batched key access join(5.6开始支持)
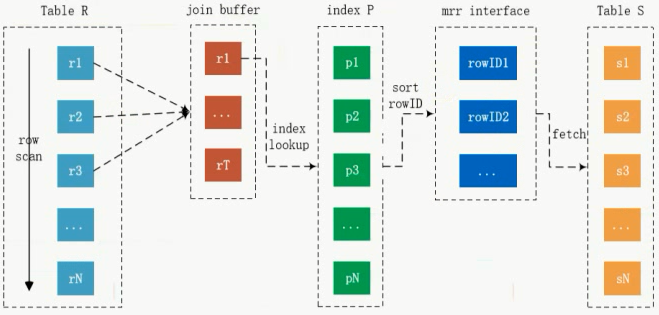
用来解决如果关联的列是二级索引,对要回表的列先cache起来,排序,再回表,性能会比较好一点
bka join调的是mrr接口,但是现在这个算法有bug,默认是永远不启动的,要启用得写hint,这是mysql现在比较大的问题
上面讲了一堆mysql的不是,join算法的痤,上面这些多少w行join,线上业务会用到这些吗?我们线上都是简单查询,这些都是很复杂的查询了,233333
错误做法:有人说业务层做join,这样不会比在数据库层做快
join算法分析的更多相关文章
- MySQL入门,了解下、
本人菜鸡一个,一份简单MySQL笔记送给大家,希望大家喜欢.(●'◡'●) Ⅰ. 数据备份与导入导出 1.1.备份基本概念介绍 1.2.mysqldump详解 1.3.mydumper浅析 1.4.M ...
- MySQL优化小结
数据库的配置是基础.SQL优化最重要(贯穿始终,每日必做),由图可知,越往上优化的面越小,最基本的SQL优化是最重要的,往上各个参数也没太多调的,也不可能说调一个innodb参数性能就会好多少,而动不 ...
- MySQL Nested-Loop Join算法学习
不知不觉的玩了两年多的MySQL,发现很多人都说MySQL对比Oracle来说,优化器做的比较差,其实某种程度上来说确实是这样,但是毕竟MySQL才到5.7版本,Oracle都已经发展到12c了,今天 ...
- BigData – Join中竟然也有谓词下推!?
本文由 网易云发布. 在之前的文章中简要介绍了Join在大数据领域中的使用背景以及常用的几种算法-broadcast hash join .shuffle hash join以及 sort merg ...
- SQL Server-聚焦IN VS EXISTS VS JOIN性能分析(十九)
前言 本节我们开始讲讲这一系列性能比较的终极篇IN VS EXISTS VS JOIN的性能分析,前面系列有人一直在说场景不够,这里我们结合查询索引列.非索引列.查询小表.查询大表来综合分析,简短的内 ...
- SQL Server-聚焦NOT IN VS NOT EXISTS VS LEFT JOIN...IS NULL性能分析(十八)
前言 本节我们来综合比较NOT IN VS NOT EXISTS VS LEFT JOIN...IS NULL的性能,简短的内容,深入的理解,Always to review the basics. ...
- Nested Loops join时显示no join predicate原因分析以及解决办法
本文出处:http://www.cnblogs.com/wy123/p/6238844.html 最近遇到一个存储过程在某些特殊的情况下,效率极其低效, 至于底下到什么程度我现在都没有一个确切的数据, ...
- c# Enumerable中Aggregate和Join的使用
参考页面: http://www.yuanjiaocheng.net/ASPNET-CORE/asp.net-core-environment.html http://www.yuanjiaochen ...
- 超详细mysql left join,right join,inner join用法分析
下面是例子分析表A记录如下: aID aNum 1 a20050111 2 a20050112 3 a20050113 4 ...
随机推荐
- (原)visual studio 2015中添加dll路径
转载请注明出处: https://www.cnblogs.com/darkknightzh/p/9922033.html 使用vs2015调用opencv 3.4时,除了需要在“VC++目录”中”包含 ...
- Hierarchical softmax(分层softmax)简单描述.
最近在做分布式模型实现时,使用到了这个函数. 可以说非常体验非常的好. 速度非常快,效果和softmax差不多. 我们知道softmax在求解的时候,它的时间复杂度和我们的词表总量V一样O(V),是性 ...
- ORACLE 存储函数
前奏: 必要的概念: ORACLE 提供能够把 PL/SQL 程序存储在数据库中.并能够在不论什么地方来运行它.这样就叫存储过 程或函数. 过程和函数统称为 PL/SQL 子程序.他们是被命名的 PL ...
- C#指定长度截取字符串 并进行拼接。
需求:有一个字符串需要按照指定长度拆分出来,然后在增加一个字符串拼接上. /// <summary> /// 字符串截取并拼接 /// </summary> /// <p ...
- Redis 的事务到底是不是原子性的
ACID 中关于原子性的定义: 原子性:一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节.事务在执行过程中发生错误,会被恢复(Rollback)到事 ...
- maven私服不能重复部署解决
1.报错 Return code is: 400, ReasonPhrase: Repository does not allow updating assets: maven-releases. 2 ...
- Apache与php快速部署web服务
[本文出自天外归云的博客园] 在一台服务器上临时起个web服务,读取服务器上的cfs文件内容并显示在页面上,做一个简单的web请求处理. 首先找到apache,在conf文件夹下vi httpd.co ...
- [加密]openssl之数字证书签名,CA认证原理及详细操作
转自:http://blog.sina.com.cn/s/blog_cfee55a70102wn3h.html 1 公钥密码体系(Public-key Cryptography) 公钥密码体系,又称非 ...
- css3 animation 在某些浏览器中特别快 bugfix
今天在一款三星 4.2.2 的 webview 里,出现 animation 特别快的问题,把: .xxx{ -webkit-animation: xxx 24s linear infinite; } ...
- Eclipse Maven profiles 多环境配置,测试环境与开发环境分开打包
1.将开发环境.测试环境.生产环境的配置文件分开存放,如下图: 2.在Maven中配置不同的环境打包配置文件的路径,配置如下: <profiles> <profile> < ...