Dom4j基础
Dom4j是一个非常非常优秀的Java XML API,用来读写XML文件,具有性能优异、功能强大和易于使用的特点,同时它也是一个开放源代码的软件,可以在SourceForge上找到它。对主流的Java XML API进行的性能、功能和易用性的评测,Dom4j无论在那个方面都是非常出色的。如今你可以看到越来越多的Java软件都在使用dom4j来读写XML,例如hibernate,包括sun公司自己的JAXM也用了Dom4j。
主要介绍Dom4j的基础操作,结合实例说明。
目录结构:
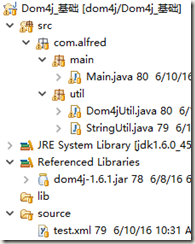
关键代码:

package com.alfred.main; import java.io.File;
import java.io.FileOutputStream;
import java.io.FileWriter;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.util.Iterator;
import java.util.List; import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter; import com.alfred.util.Dom4jUtil; public class Main { public static void main(String[] args) throws Exception {
// 获取document对象,三种方法
Document doc = Dom4jUtil.getDocument(); // 打印文档结构
// Dom4jUtil.printDocument(doc); // 打印文档的结构 使用dom4j输出重定向
Dom4jUtil.printDocumentByDom4j(doc); // 对节点的操作
// elementOper(doc); // 对节点属性的操作
// elementAttributeOper(doc); // 将document写入文件
// writeDocumentToXml(doc); // document的其他操作
// documentOtherOper(); } /**
* 对节点的操作
*
* @param doc
*/
private static void elementOper(Document doc) {
// 获取文档的根节点
Element root = doc.getRootElement(); // ===========================查询 begin
// 获取某个节点的子节点
Element position = root.element("position");
// 获取节点的文字内容 position.getTextTrim();去掉前后空格
String positionText = position.getText();
System.out.println("positionText:" + positionText); Element employees = root.element("employees");
// 获取某节点下所有名为“employee”的子节点,并进行遍历
List employeeList = employees.elements("employee");
for (Iterator it = employeeList.iterator(); it.hasNext();) {
Element elm = (Element) it.next();
}
// 获取某节点下所有子节点
List elementList = employees.elements(); // 对某节点下的所有子节点进行遍历
for (Iterator it = employees.elementIterator(); it.hasNext();) {
Element element = (Element) it.next();
}
// ===========================查询 end // ===========================新增 begin
// 在某节点下添加子节点
Element compbirthday = root.addElement("compbirthday");
// 设置节点内容
compbirthday.setText("1970-10-10");
// 添加CDATA内容
compbirthday.addCDATA("cdata区域");
// ===========================新增 end // ===========================删除 begin
Element name = root.element("name");
// 删除节点
boolean issuccess = root.remove(name);
// ===========================删除 end
} /**
* 对节点属性的操作
*
* @param doc
*/
private static void elementAttributeOper(Document doc) {
// 获取文档的根节点
Element root = doc.getRootElement();
// ===========================查询 begin
// 获取节点
Element name = root.element("name");
// 获取某节点下的某属性
Attribute scale = name.attribute("scale");
// 获取属性的内容
String scaleText = scale.getText();
// 遍历某节点的所有属性
for (Iterator it = root.attributeIterator(); it.hasNext();) {
Attribute attribute = (Attribute) it.next();
}
// 获取某节点下所有属性
List attributeList = name.attributes();
// 获取某节点下某个属性的值,如果不存在该属性则返回null
String abbrValue = name.attributeValue("abbr");
// 获取某节点下某个属性的值,如果不存在该属性则返回设置的默认值
String abbrnewValue = name.attributeValue("abbrnew", "IBMNEW");
// ===========================查询 end // ===========================新增 begin
// 设置某节点的属性和内容 如果不存在则新增属性
name.addAttribute("scale", "1100");
name.addAttribute("scalewish", "1300");
// 设置属性的内容
name.setText("1200");
// ===========================新增 end // ===========================删除 begin
// 删除节点属性
boolean issuccess = name.remove(scale);
// ===========================删除 end
} /**
* 将document写入文件
*
* @param doc
* @throws IOException
*/
private static void writeDocumentToXml(Document doc) throws IOException {
// 不设置编码,直接写入的形式
// XMLWriter writer = new XMLWriter(new
// FileWriter("source/newtest.xml"));
// writer.write(doc);
// writer.flush();
// writer.close(); // 设置编码格式写入的形式(当文档中存在中文的时候)
// 创建文件输出的时候,紧凑的格式
// OutputFormat format = OutputFormat.createCompactFormat();
// 创建文件输出的时候,自动缩进的格式
OutputFormat format = OutputFormat.createPrettyPrint();
// 设置编码
format.setEncoding("UTF-8");
// 创建XMLWriter对象,指定写出文件及编码格式
// XMLWriter writerEncoding = new XMLWriter(new
// FileWriter("source/newtest_encoding.xml"), format);
XMLWriter writerEncoding = new XMLWriter(new OutputStreamWriter(
new FileOutputStream(new File("source/newtest_encoding.xml")),
"UTF-8"), format);
// 写入
writerEncoding.write(doc);
// 立即写入
writerEncoding.flush();
// 关闭操作
writerEncoding.close();
} /**
* document的其他操作
*
* @param doc
* @throws DocumentException
*/
private static void documentOtherOper() throws DocumentException {
// ===========================字符串与XML的转换 begin
// 将字符串转化为XML
String xml = "<develop><java>java 语言</java></develop>";
Document document = DocumentHelper.parseText(xml);
// 将文档或节点的XML转化为字符串
SAXReader reader = new SAXReader();
Element root = document.getRootElement();
String docXmlText = document.asXML();
String rootXmlText = root.asXML();
Element memberElm = root.element("java");
String memberXmlText = memberElm.asXML();
// ===========================字符串与XML的转换 end
} }
Main.java
package com.alfred.util; import java.io.File;
import java.io.IOException;
import java.util.List; import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter; /**
* dom4j工具类
*
* @author alfredinchange
*
*/
public class Dom4jUtil { private static String tabchar = " "; /**
* 获取dom4j的文档对象 总共有三种方式:读取文件,解析xml字符串,生成新的文档对象
*
* @return
* @throws DocumentException
*/
public static Document getDocument() throws DocumentException {
// 读取XML文件,获得document对象
SAXReader reader = new SAXReader();
Document doc = reader.read(new File("source/test.xml")); // 解析XML形式的文本,得到document对象
// String xml = "<company><name>IBM</name></company>";
// Document doc = DocumentHelper.parseText(xml); // 主动创建document对象
// Document doc = DocumentHelper.createDocument();
// Element root = doc.addElement("company");
// Element name = root.addElement("name");
// name.setText("IBM"); return doc;
} /**
* 打印文档的结构 使用dom4j输出重定向
*
* @param doc
* @throws IOException
*/
public static void printDocumentByDom4j(Document doc) throws IOException {
// 创建文件输出的时候,自动缩进的格式
OutputFormat format = OutputFormat.createPrettyPrint();
// 设置编码
format.setEncoding("UTF-8");
XMLWriter writer = new XMLWriter(System.out, format);
writer.write(doc);
writer.flush();
writer.close();
} /**
* 打印文档的结构
*
* @param doc
* 文档对象
*/
public static void printDocument(Document doc) {
Integer tabcnt = 1; // 获取文档对象根节点
Element root = doc.getRootElement();
System.out.print("<" + root.getName() + getElementAttribute(root) + ">"
+ root.getTextTrim());
/**
* root.elements():取得某节点下所有的子节点
* root.elements("employees"):取得某节点下所有名为"employees"的子节点
*/
List rootElements = root.elements();
if (rootElements.size() != 0) {
System.out.println();
}
for (Object obj : rootElements) {
Element element = (Element) obj;
/**
* element.getName():获取节点名称 element.getText():获取节点内容
* element.getTextTrim():获取节点内容,去掉前后空格
*/
System.out.print(StringUtil.copyString(tabchar, tabcnt) + "<"
+ element.getName() + getElementAttribute(element) + ">"
+ element.getTextTrim());
boolean flag = printElement(element, tabcnt);
System.out.print((flag ? StringUtil.copyString(tabchar, tabcnt)
: "")
+ "</" + element.getName() + ">");
System.out.println();
}
System.out.print("</" + root.getName() + ">");
} /**
* 打印节点的结构
*
* @param element
* 节点对象
* @param tabcnt
* 节点前的tab数目
*/
private static boolean printElement(Element element, Integer tabcnt) {
tabcnt++;
List elements = element.elements();
if (elements.size() != 0) {
System.out.println();
}
for (Object obj : elements) {
Element el = (Element) obj;
System.out.print(StringUtil.copyString(tabchar, tabcnt) + "<"
+ el.getName() + getElementAttribute(el) + ">"
+ el.getTextTrim());
boolean flag = printElement(el, tabcnt);
System.out.print((flag ? StringUtil.copyString(tabchar, tabcnt)
: "")
+ "</" + el.getName() + ">");
System.out.println();
}
return elements.size() != 0;
} /**
* 获取节点属性
*
* @param root
* @return
*/
private static String getElementAttribute(Element element) {
StringBuffer sb = new StringBuffer();
// 取得某节点的所有属性
List attributes = element.attributes();
for (Object obj : attributes) {
Attribute attribute = (Attribute) obj;
/**
* attribute.getName():获取属性名称 attribute.getText():获取属性内容
*/
sb.append(" " + attribute.getName() + "=\"" + attribute.getText()
+ "\"");
}
return sb.toString();
} }
Dom4jUtil.java
package com.alfred.util; /**
* 字符串操作工具类
*
* @author alfredinchange
*
*/
public class StringUtil { /**
* 字符串拷贝
* @param str 源字符串
* @param cnt 拷贝次数
* @return
*/
public static String copyString(String str,Integer cnt){
StringBuffer sb = new StringBuffer();
while(cnt != null && cnt > 0){
sb.append(str);
cnt--;
}
return sb.toString();
} }
StringUtil.java
<?xml version="1.0" encoding="UTF-8"?>
<company>
<name scale="1000" abbr="ibm">IBM</name>
<position>USA</position>
<employees count="2">
<employee>
<username>alfred01</username>
<fullname>这是测试呀</fullname>
<age>22</age>
<birthday>1990-10-11</birthday>
</employee>
<employee>
<username>alfred02</username>
<fullname>中文会不会出错呀</fullname>k
<age>25</age>
<birthday>1993-01-02</birthday>
</employee>
</employees>
</company>
test.xml
Dom4j基础的更多相关文章
- dom4j基础教程【转】
转自 http://blog.csdn.net/whatlonelytear/article/details/42234937 ,但经过大量美化及补充. Dom4j是一个易用的.开源的库,用于XML, ...
- Dom4j使用Xpath语法读取xml节点
我们可以使用Xpath的语法来轻易的读取xml的某个节点[类似于jQuery的选择器]: 使用Xpath语法需要添加新的jaxen-1.1-beta-7.rar 这个jar包 dom4j完整jar包我 ...
- 2016年终分析(传统开发与网络时代的Java开发)
2016重大事件:(在此将2016年的开发称为传统开发) 1.乌镇互联网大会大会(大数据&云计算) 2.某东struts2安全漏洞 3.作为一个程序呀对于淘宝双11和双12的分析应该是最好的案 ...
- 【Java】解析Java对XML的操作
目录结构: contents structure [+] 什么是XML 解析XML 使用DOM解析 使用SAX解析 使用PULL解析 使用dom4j解析xml dom4j的部分API 打印一个XML文 ...
- XML基础以及用DOM4j读取数据
都知道,HTML被设计用来显示数据,XML被设计用来保存.数据传输.而我们平时经经常使用的无非是保存数据.读取数据.所以这里主要介绍XML相关基础内容.以及用DOM4j来存取XML的数据. 以下简单介 ...
- java基础73 dom4j修改xml里面的内容(网页知识)
1.DOM4J对XML文件进行增删改操作 实现代码 package com.shore.code; import java.io.File; import java.io.FileOutputStre ...
- java基础 xml 使用dom4j解析 xml文件 servlet根据pattern 找到class
package com.swift.kaoshi; import java.io.File; import java.util.List; import java.util.Scanner; impo ...
- [JavaWeb基础] 031.dom4j写入xml的方法
上一篇我们讲述了dom4j读取xml的4种方法,甚是精彩,那么怎么样写入xml呢?我们直接看下源码实现. public static void main(String[] args) throws E ...
- [JavaWeb基础] 030.dom4j读取xml的4种方法
通常我们在项目开发的过程中经常要操作到xml文件,在JAVA这边,我们会很自然的联想到Dom4J这个apache的开源插件,那么我们使用Dom4J如何来读取xml文件呢?下面我们来看看以下4种方法 1 ...
随机推荐
- phpmyadmin 上传超过50m限制
sql文件太大(达到400m),导致无法正常导入.需要修改php,nginx的配置文件 php.ini配置 post_max_size = 500M upload_max_filesize = 500 ...
- 图像的下采样Subsampling 与 上采样 Upsampling
I.目的 缩小图像(或称为下采样(subsampled)或降采样(downsampled))的主要目的: 1.使得图像符合显示区域的大小: 2.生成对应图像的缩略图. 放大图像(或称为上采样(ups ...
- Java对象序列化和反序列化的工具方法
import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import ja ...
- docker 应用-1(安装以及基础命令)
Docker 安装 还是看官方文档吧TAT https://docs.docker.com/engine/getstarted/step_one/ 理解docker镜像和容器 镜像就是docker容器 ...
- Spring Security默认的用户登录表单 页面源代码
Spring Security默认的用户登录表单 页面源代码 <html><head><title>Login Page</title></hea ...
- js版的in_array的实现方法
这是一个JS版的判断数组内的元素的方法. var arr = ['a','b','c']; console.log(in_array('b',arr)); // true function in_ar ...
- Nestjs 身份验证
文档 yarn add @nestjs/passport passport passport-http-bearer @nestjs/jwt passport-jwt auth.service.ts ...
- linux 系统全盘备份
备份程序对比 - Synchronization and backup programs 之前用的 tar进行备份了,更新 grub引导需要重建目录和手动挂载,不是很方便.现直接使用 timeshif ...
- 28. css样式中px转rem
Vue3:脚手架配置 https://blog.csdn.net/weixin_41424247/article/details/80867351 与原来的vue-cli 2.x版本不同的是:如果使用 ...
- js判断PC端还是移动端
function goPAGE() { if ((navigator.userAgent.match(/(phone|pad|pod|iPhone|iPod|ios|iPad|Android|Mobi ...