P2P原理(转)
P2P(Peer to Peer)对等网络
P2P技术属于覆盖层网络(Overlay Network)的范畴,是相对于客户机/服务器(C/S)模式来说的一种网络信息交换方式。在C/S模式中,数据的分发采用专门的服务器,多个客户端都从此服务器获取数据。
优点是:数据的一致性容易控制,系统也容易管理。
缺点是:因为服务器的个数只有一个(即便有多个也非常有限),系统容易出现单一失效点;单一服务器面对众多的客户端,由于CPU能力、内存大小、网络带宽的限制,可同时服务的客户端非常有限,可扩展性差。
P2P技术正是为了解决这些问题而提出来的一种对等网络结构。在P2P网络中,每个节点既可以从其他节点得到服务,也可以向其他节点提供服务。这样,庞大的终端资源被利用起来,一举解决了C/S模式中的两个弊端。
P2P应用软件主要包括文件分发软件、语音服务软件、流媒体软件。目前P2P应用种类多、形式多样,没有统一的网络协议标准,其体系结构和组织形式也在不断发展。
对等网络的基本结构
集中式对等网络基于中央目录服务器,为网络中各节目提供目录查询服务,传输内容无需再经过中央服务器。这种网络,结构比较简单,中央服务器的负担大大降低。但由于仍存在中央节点,容易形成传输瓶颈,扩展性也比较差,不适合大型网络。但由于目录集中管理,对于小型网络的管理和控制上倒是一种可选择方案。
无结构分布式网络与集中式的最显著区别在于,它没有中央服务器,所有结点通过与相邻节点间的通信,接入整个网络。在无结构的网络中,节点采用一种查询包的机制来搜索需要的资源。具体的方式为,某节点将包含查询内容的查询包发送到与之相邻的节点,该查询包以扩散的方式在网络中蔓延,由于这样的方式如果不加节制,会造成消息泛滥,因此一般会设置一个适当的生存时间(TTL),在查询的过程中递减,当TTL值为0时,将不再继续发送。
这种无结构的方式,组织方式比较松散,节点的加入与离开比较自由,当查询热门内容时,很容易就能找到,但如果需求的内容比较冷门,较小的TTL不容易找到,而较大的TTL值又容易引起较大的查询流量,尤其当网络范围扩展到一定规模时,即使限制的TTL值较小,仍然会引起流量的剧增。但当网络中存在一些拥有丰富资源的所谓的类服务器节点时,可显著提高查询的效率。
结构化分布式网络,是近几年基于分布式哈希表(Distributed Hash Table)技术的研究成果。它的基本思想是将网络中所有的资源整理成一张巨大的表,表内包含资源的关键字和所存放结点的地址,然后将这张表分割后分别存储到网络中的每一结点中去。当用户在网络中搜索相应的资源时,它将能发现存储与关键词对应的哈希表内容所存放的结点,在该结点中存储了包含所需资源的结点地址,然后发起搜索的结点根据这些地址信息,与对应结点连接并传输资源。这是一种技术上比较先进的对等网络,它具有高度结构化,高可扩展性,结点的加入与离开比较自由。这种方式适合比较大型的网络。
对等网络经典结构
分布式哈希表(DHT)[1]是一种功能强大的工具,它的提出引起了学术界一股研究DHT的热潮。虽然DHT具有各种各样的实现方式,但是具有共同的特征,即都是一个环行拓扑结构,在这个结构里每个节点具有一个唯一的节点标识(ID),节点ID是一个128位的哈希值。每个节点都在路由表里保存了其他前驱、后继节点的ID。如图1(a)所示。通过这些路由信息,可以方便地找到其他节点。这种结构多用于文件共享和作为底层结构用于流媒体传输[2]。
网状结构如图1(c)所示,又叫无结构。顾名思义,这种结构中,所有的节点无规则地连在一起,没有稳定的关系,没有父子关系。网状结构[5]为P2P提供了最大的容忍性、动态适应性,在流媒体直播和点播应用中取得了极大的成功。当网络变得很大时,常常会引入超级节点的概念,超级节点可以和任何一种以上结构结合起来组成新的结构,如KaZaA[6]。

P2P技术应用
(1)分布式科学计算
P2P技术可以使得众多终端的CPU资源联合起来,服务于一个共同的计算。这种计算一般是计算量巨大、数据极多、耗时很长的科学计算。在每次计算过程中,任务(包括逻辑与数据等)被划分成多个片,被分配到参与科学计算的P2P节点机器上。在不影响原有计算机使用的前提下,人们利用分散的CPU资源完成计算任务,并将结果返回给一个或多个服务器,将众多结果进行整合,以得到最终结果。
(2)文件共享
BitTorrent是一种无结构的网络协议。除了BitTorrent之外,还有不少著名的无结构化的P2P文件共享协议,典型的有Gnutella[8]和KaZaA[6]。
(3)流媒体直播
(4)流媒体点播
(5)IP层语音通信
Skype采取类似KaZaA的拓扑结构,在网络中选取一些超级节点。在通信双方直连效果不好时,一些合适的超级节点则担当起其中转节点的角色,为通信双方创建中转连接,并转发相应的语音通信包。
典型P2P应用的机制分析
分析典型的P2P应用机制可以深入了解P2P的原理。本节将对文件分发、流媒体应用、语音服务3个领域中具有代表性的软件机制进行详细的分析。对于这些软件的分析有助于理解P2P技术的原理和把握P2P技术未来发展的趋势。
BitTorrent
BitTorrent软件用户首先从Web服务器上获得下载文件的种子文件,种子文件中包含下载文件名及数据部分的哈希值,还包含一个或者多个的索引(Tracker)服务器地址。它的工作过程如下:客户端向索引服务器发一个超文本传输协议(HTTP)的GET请求,并把它自己的私有信息和下载文件的哈希值放在GET的参数中;索引服务器根据请求的哈希值查找内部的数据字典,随机地返回正在下载该文件的一组节点,客户端连接这些节点,下载需要的文件片段。因此可以将索引服务器的文件下载过程简单地分成两个部分:与索引服务器通信的HTTP,与其他客户端通信并传输数据的协议,我们称为BitTorrent对等协议。BitTorrent软件的工作原理如图4所示。BitTorrent协议也处在不断变化中,可以通过数据报协议(UDP)和DHT的方法获得可用的传输节点信息,而不是仅仅通过原有的HTTP,这种方法使得BitTorrent应用更加灵活,提高BitTorrent用户的下载体验。
eMule
eMule软件基于eDonkey协议改进后的协议,同时兼容eDonkey协议。每个eMule客户端都预先设置好了一个服务器列表和一个本地共享文件列表,客户端通过TCP连接到eMule服务器进行登录,得到想要的文件的信息以及可用的客户端的信息。一个客户端可以从多个其他的EMule客户端下载同一个文件,并从不同的客户端取得不同的数据片段。eMule同时扩展了eDonkey的能力,允许客户端之间互相交换关于服务器、其他客户端和文件的信息。eMule服务器不保存任何文件,它只是文件位置信息的中心索引。eMule客户端一启动就会自动使用传输控制协议(TCP)连接到eMule服务器上。服务器给客户端提供一个客户端标识(ID),它仅在客户端服务器连接的生命周期内有效。连接建立后,客户端把其共享的文件列表发送给服务器。服务器将这个列表保存在内部数据库内。eMule客户端也会发送请求下载列表。连接建立以后,eMule服务器给客户端返回一个列表,包括哪些客户端可以提供请求文件的下载。然后,客户端再和它们主动建立连接下载文件。图5所示为eMule的工作原理。
eMule基本原理与BitTorrent类似,客户端通过索引服务器获得文件下载信息。eMule同时允许客户端之间传递服务器信息,BitTorrent只能通过索引服务器或者DHT获得。eMule共享的是整个文件目录,而BitTorrent只共享下载任务,这使得BitTorrent更适合分发热门文件,eMule倾向于一般热门文件的下载。
迅雷
迅雷是一款新型的基于多资源多线程技术的下载软件,迅雷拥有比目前用户常用的下载软件快7~10倍的下载速度。迅雷的技术主要分成两个部分,一部分是对现有Internet下载资源的搜索和整合,将现有Internet上的下载资源进行校验,将相同校验值的统一资源定位(URL)信息进行聚合。当用户点击某个下载连接时,迅雷服务器按照一定的策略返回该URL信息所在聚合的子集,并将该用户的信息返回给迅雷服务器。另一部分是迅雷客户端通过多资源多线程下载所需要的文件,提高下载速率。迅雷高速稳定下载的根本原因在于同时整合多个稳定服务器的资源实现多资源多线程的数据传输。多资源多线程技术使得迅雷在不降低用户体验的前提下,对服务器资源进行均衡,有效降低了服务器负载。
每个用户在网上下载的文件都会在迅雷的服务器中进行数据记录,如有其他用户再下载同样的文件,迅雷的服务器会在它的数据库中搜索曾经下载过这些文件的用户,服务器再连接这些用户,通过用户已下载文件中的记录进行判断,如用户下载文件中仍存在此文件(文件如改名或改变保存位置则无效),用户将在不知不觉中扮演下载中间服务角色,上传文件。
PPLive
PPLive软件的工作机制和BitTorrent十分类似,PPLive将视频文件分成大小相等的片段,第三方提供播放的视频源,用户启矾PPLive以后,从PPLive服务器获得频道的列表,用户点击感兴趣的频道,然后从其他节点获得数据文件,使用流媒体实时传输协议(RTP)和实时传输控制协议(RTCP)进行数据的传输和控制。将数据下载到本地主机后,开放本地端口作为视频服务器,PPLive的客户端播放器连接此端口,任何同一个局域网内的用户都可以通过连接这个地址收看到点播的节目。图6所示为PPLive的工作原理示意图。
Skype
Skype是网络语音沟通工具。它可以提供免费高清晰的语音对话,也可以用来拨打国内国际长途,还具备即时通讯所需的其他功能,比如文件传输、文字聊天等。Skype是在KaZaA的基础上开发的,就像KaZaA一样,Skype本身也是基于覆盖层的P2P网络,在它里面有两种类型的节点:普通节点和超级节点。普通节点是能传输语音和消息的一个功能实体;超级节点则类似于普通节点的网络网关,所有的普通节点必须与超级节点连接,并向Skype的登陆服务器注册它自己来加入Skype网络。Skype的登陆服务器上存有用户名和密码,并且授权特定的用户加入Skype网络,图7所示为Skype的体系结构[18]。
Skype的另一个突出特点就是能够穿越地址转换设备和防火墙。Skype能够在最小传输带宽32 kb/s的网络上提供高质量的语音。Skype是使用P2P语音服务的代表。由于其具有超清晰语音质量、极强的穿透防火墙能力、免费多方通话以及高保密性等优点,成为互联网上使用最多的P2P应用之一。
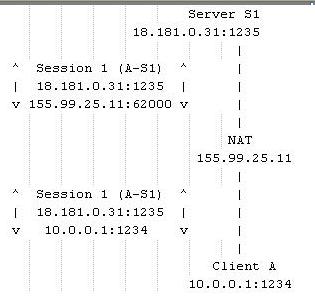
有一个私有网络10.*.*.*,Client A是其中的一台计算机,这个网络的网关(一个NAT设备)的外网IP是155.99.25.11(应该还有一个内网的IP地址,比如10.0.0.10)。如果Client A中的某个进程(这个进程创建了一个UDP Socket,这个Socket绑定1234端口)想访问外网主机18.181.0.31的1235端口,那么当数据包通过NAT时会发生什么事情呢?

接上面的例子,如果Client A的原来那个Socket(绑定了1234端口的那个UDP Socket)又接着向另外一个Server S2发送了一个UDP包,那么这个UDP包在通过NAT时会怎么样呢?

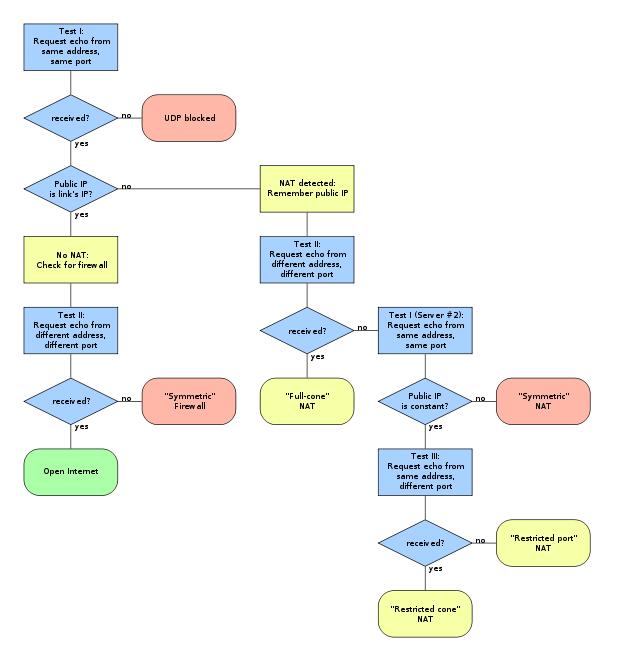
参考文章:
P2P技术原理:http://www.360doc.com/content/14/0305/17/8285430_357987074.shtml
P2P技术现状及发展未来:http://www.zte.com.cn/cndata/magazine/zte_communications/2007/6/magazine/200712
P2P原理及其常用的实现方式:http://www.cppblog.com/peakflys/archive/2013/01/25/197562.html
P2P原理(转)的更多相关文章
- P2P原理及UDP穿透简单说明(转)
源: P2P原理及UDP穿透简单说明
- P2P原理及UDP穿透简单说明
转:http://http://andylin02.iteye.com/blog/444666 P2P原理及UDP穿透简单说明 本文章出自cnntec.com的AZ猫著,如需要转发,请注明来自cnnt ...
- P2P原理
简单介绍 前面文章在分布式计算泛型中介绍过P2P泛型.他是一种是一种无中心server的对等网络泛型. P2P即Peer-to-Peer的缩写.翻译为点对点或者端对端.就是我们常说的对等计算. P2P ...
- 【转】P2P之UDP穿透NAT的原理与实现(附源代码)
作者:shootingstars (有容乃大,无欲则刚) 日期:2004-5-25 出处:P2P中国(PPcn.net) P2P 之 UDP穿透NAT的原理与实现(附源代码)原创:shootings ...
- UDP穿越NAT原理(p2p)
转载自:http://blog.csdn.net/ldd909/article/details/5979967 论坛上经常有对P2P原理的讨论,但是讨论归讨论,很少有实质的东西产生(源代码).在这里我 ...
- 使用ZeroNet搭建P2P全球网站
软件 ZeroNet是一个利用比特币加密和BT技术提供不受审查的网络与通信的BT平台,ZeroNet网络功能已经得到完整的种子的支持和加密连接,保证用户通信和文件共享的安全.使用ZeroNet,你可以 ...
- 基于Html5缓存的页面P2P技术可行性探讨
P2P技术,在分享大文件(你懂的)是现在必不可缺的技术,现在的人,已经很难想象在没有这玩意的互联网早期,人们是怎样的艰难求生.想当年,不要说电影,下一个稍大点的文件,都是很吃力的事情. 后来牛人科恩, ...
- UDP打洞、P2P组网方式研究
catalogue . NAT概念 . P2P概念 . UDP打洞 . P2P DEMO . ZeroNet P2P 1. NAT概念 在STUN协议中,根据内部终端的地址(LocalIP:Local ...
- P2P通信标准协议(一)之STUN
前一段时间在P2P通信原理与实现中介绍了P2P打洞的基本原理和方法,我们可以根据其原理为自己的网络程序设计一套通信规则, 当然如果这套程序只有自己在使用是没什么问题的.可是在现实生活中,我们的程序往往 ...
随机推荐
- tensorflow 调试tfdbg
1.执行pip install pyreadline 安装pyreadline 2.修改对应代码如下 with tf.Session() as sess: sess.run(tf.global_var ...
- Qt编写自定义控件3-速度仪表盘
前言 速度仪表盘,写作之初的本意是用来展示当前测试的网速用的,三色圆环+数码管显示当前速度,Qt自带了数码管控件QLCDNumber,直接集成即可,同时还带有动画功能,其实也可以用在汽车+工业领域等, ...
- 机器人学 —— 机器人感知(Location)
终于完成了Robotic SLAM 所有的内容了.说实话,课程的内容比较一般,但是作业还是挺有挑战性的.最后一章的内容是 Location. Location 是 Mapping 的逆过程.在给定ma ...
- gitlab-ci + k8s 之docker (三)
docker 在本系列(一)中(https://www.cnblogs.com/huandada/p/9965771.html)的runner_tomcat.sh脚本有涉及到镜像的推送,本文主要记录整 ...
- Web前端攻击方式及防御措施
一.XSS [Cross Site Script]跨站脚本攻击 恶意攻击者往Web页面里插入恶意Script代码,当用户浏览该页之时,嵌入其中Web里面的Script代码会被执行,从而达到恶意攻击用户 ...
- ubuntu下nodejs和npm的安装及升级
ubuntu 下 nodejs 和 npm 的安装及升级 参考:https://segmentfault.com/a/1190000007542620 一:ubuntu下安装 node 和 npm命令 ...
- itoa()函数
itoa()函数 itoa():char *itoa( int value, char *string,int radix); 原型说明: value:欲转换的数据.string:目标字符串的地址.r ...
- python全栈开发 * 29知识点汇总 * 180712
29 正则表达式 re模块一.正则表达式官方定义:正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符.及这些特定字符的组合,组成一个“规则字符串”, 这个“规则字符串”用来表达对字 ...
- Web前端开发推荐书籍
Web前端开发推荐书籍 前言 学校里没有前端的课程,那如何学习JavaScript,又如何使自己成为一个合格的前端工程师呢? 读 书吧~相对于在网上学习,在项目中学习和跟着有经验的同事学习,书中有着相 ...
- day18 十八、random、shutil、shevle、logging
一.random 模块:随机数 1. import random # .[,]整数 random randint(,) print(random.randint(, )) # 随机产生[,]中的一个数 ...