Python 爬虫实例(7)—— 爬取 新浪军事新闻
我们打开新浪新闻,看到页面如下,首先去爬取一级 url,图片中蓝色圆圈部分
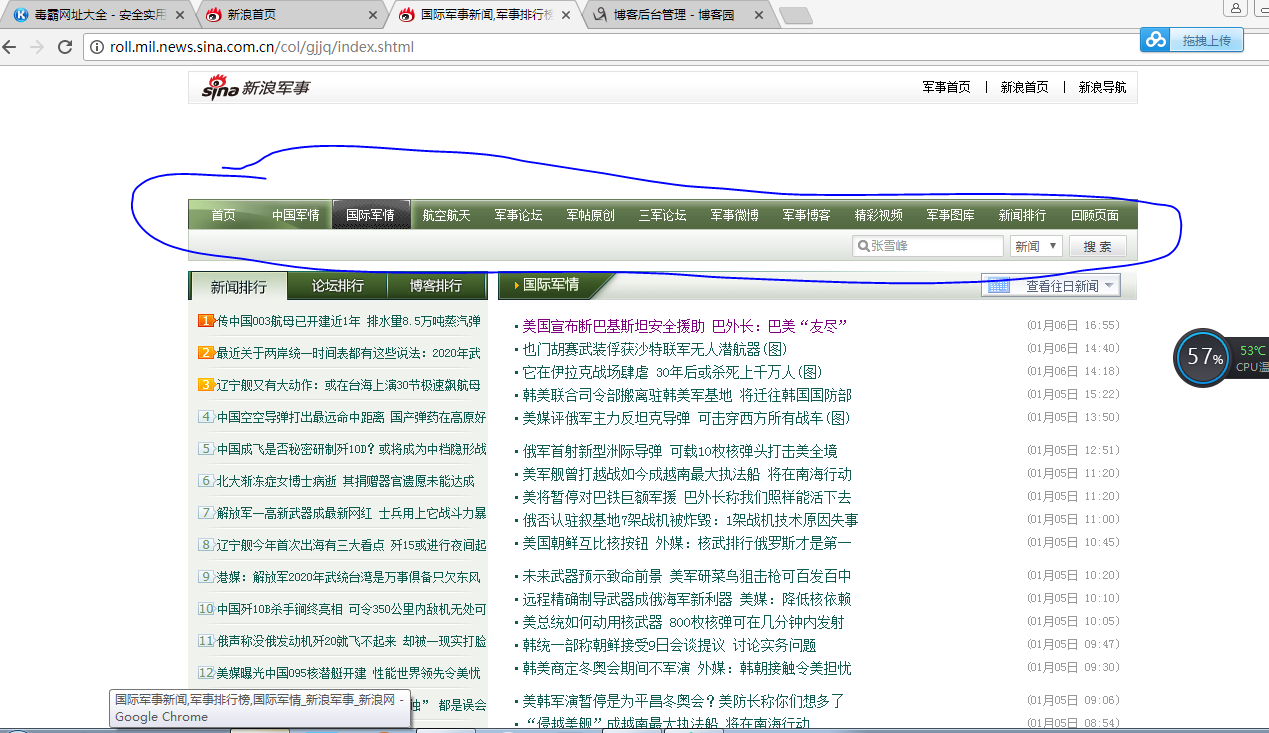
第二zh张图片,显示需要分页,

源代码:
# coding:utf-8 import json
import redis
import time
import requests
session = requests.session()
import logging.handlers
import pickle
import sys
import re
import datetime
from bs4 import BeautifulSoup import sys
reload(sys)
sys.setdefaultencoding('utf8') import datetime
# 生成一年的日期
def dateRange(start, end, step=1, format="%Y-%m-%d"):
strptime, strftime = datetime.datetime.strptime, datetime.datetime.strftime
days = (strptime(end, format) - strptime(start, format)).days
return [strftime(strptime(start, format) + datetime.timedelta(i), format) for i in xrange(0, days, step)] def spider(): date_list = dateRange("2017-01-01", "2018-01-06")[::-1]
print date_list
for date in date_list:
for page in range(1,5):
#组合url
url = "http://roll.mil.news.sina.com.cn/col/zgjq/" + str(date)+"_"+ str(page) +".shtml"
# 伪装请求头
headers = { "Host":"roll.mil.news.sina.com.cn", "Cache-Control":"max-age=0",
"Upgrade-Insecure-Requests":"",
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36",
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8", "Accept-Encoding":"gzip, deflate",
"Accept-Language":"zh-CN,zh;q=0.8",
"If-Modified-Since":"Sat, 06 Jan 2018 09:57:24 GMT", } result = session.get(url=url,headers=headers).content
#编码格式是 gb2312,使用BeautifulSoup解决编码格式
soup = BeautifulSoup(result,'html.parser')
#找到新闻列表
result_div = soup.find_all('div',attrs={"class":"fixList"})[0]
#去下换行
result_replace = str(result_div).replace('\n','').replace('\r','').replace('\t','')
#正则匹配信息
result_list = re.findall('<li>(.*?)</li>',result_replace) for i in result_list:
#匹配出来新闻 url, name,time news_url = re.findall('<a href="(.*?)" target=',i)[0]
news_name = re.findall('target="_blank">(.*?)</a>',i)[0]
news_time = re.findall('<span class="time">\((.*?)\)</span>',i)[0] print news_url
print news_name
print news_time spider()
Python 爬虫实例(7)—— 爬取 新浪军事新闻的更多相关文章
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- python2.7 爬虫初体验爬取新浪国内新闻_20161130
python2.7 爬虫初学习 模块:BeautifulSoup requests 1.获取新浪国内新闻标题 2.获取新闻url 3.还没想好,想法是把第2步的url 获取到下载网页源代码 再去分析源 ...
- Python爬虫教程-17-ajax爬取实例(豆瓣电影)
Python爬虫教程-17-ajax爬取实例(豆瓣电影) ajax: 简单的说,就是一段js代码,通过这段代码,可以让页面发送异步的请求,或者向服务器发送一个东西,即和服务器进行交互 对于ajax: ...
- [python爬虫] Selenium定向爬取虎扑篮球海量精美图片
前言: 作为一名从小就看篮球的球迷,会经常逛虎扑篮球及湿乎乎等论坛,在论坛里面会存在很多精美图片,包括NBA球队.CBA明星.花边新闻.球鞋美女等等,如果一张张右键另存为的话真是手都点疼了.作为程序员 ...
- Python3:爬取新浪、网易、今日头条、UC四大网站新闻标题及内容
Python3:爬取新浪.网易.今日头条.UC四大网站新闻标题及内容 以爬取相应网站的社会新闻内容为例: 一.新浪: 新浪网的新闻比较好爬取,我是用BeautifulSoup直接解析的,它并没有使用J ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- selenium+BeautifulSoup+phantomjs爬取新浪新闻
一 下载phantomjs,把phantomjs.exe的文件路径加到环境变量中,也可以phantomjs.exe拷贝到一个已存在的环境变量路径中,比如我用的anaconda,我把phantomjs. ...
随机推荐
- 富文本编辑器Django-ckeditor
富文本编辑器Django-ckeditor 前言 刚开始学习django的时候,在后台编辑数据的时候,总是在想,功能是否太简陋了点,只能做简单的文本编辑,所以在这里记录一个富文本编辑器Django-c ...
- SpringBoot返回json和xml
有些情况接口需要返回的是xml数据,在springboot中并不需要每次都转换一下数据格式,只需做一些微调整即可. 新建一个springboot项目,加入依赖jackson-dataformat-xm ...
- opencv3 学习笔记(二)
1.OpenCv 颜色追踪 import cv2import numpy as npcap=cv2.VideoCapture(0)cap.set(cv2.CAP_PROP_FRAME_WIDTH, 1 ...
- AE模板
== 蓝色浩瀚星辰中一道光速展示企业LOGO AE模板 科技公司品牌开场动画. == 线条科技感图片商品介绍 Tech Grid Show免费下载 科技科幻风格. 产品介绍不错. == 炫光三维金属质 ...
- 1490 ACM 数学
题目:http://acm.hdu.edu.cn/showproblem.php?pid=1490 题意: 给出n*n 的矩阵,选出不同行不同列的n个元素,并求和: 如果所有选法所产生的和相等,则输出 ...
- 转 U-BOOT之stage1
前言 本文主要是基于大家比较熟悉的 s3c2410 ,对移植 u-boot 时 stage1 过程进行一个分析,网上关于之方面的资料很多,但是几乎都只是对代码作注解,容易让人产生知其一不知其二的感觉, ...
- python网络编程(十一)
epoll版-TCP服务器 1. epoll的优点: 没有最大并发连接的限制,能打开的FD(指的是文件描述符,通俗的理解就是套接字对应的数字编号)的上限远大于1024 效率提升,不是轮询的方式,不会随 ...
- redis:list列表类型的操作
1. list列表类型的操作 1.1. lpush/rpush key value [value ...] 链表的头部(左侧)或尾部(右侧)插入值 语法:lpush key value [value ...
- NodeJS Stream流
NodeJS Stream流 流数据在网络通信中至关重要,nodeJS用Stream提供了一个抽象接口,node中有很多对象实现了这个接口,提供统一的操作体验 基本流类型 NodeJS中,Stream ...
- Chrome_调试js出现Uncaught SyntaxError: Unexpected identifier
转载自:http://blog.csdn.net/yiluoak_47/article/details/7663952 chrome下运行编写的JavaScript代码时,在工具javascript控 ...