分布式Snowflake雪花算法
前言
项目中主键ID生成方式比较多,但是哪种方式更能提高的我们的工作效率、项目质量、代码实用性以及健壮性呢,下面作了一下比较,目前雪花算法的优点还是很明显的。
优缺点比较
- UUID(缺点:太长、没法排序、使数据库性能降低)
- Redis(缺点:必须依赖Redis)
- Oracle序列号(缺点:用Oracle才能使用)
- Snowflake雪花算法,优点:生成有顺序的id,提高数据库的性能
Snowflake雪花算法解析
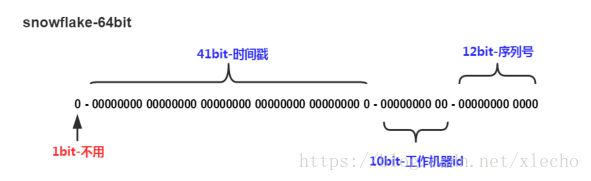
雪花算法解析 结构 snowflake的结构如下(每部分用-分开):
0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000
第一位为未使用,接下来的41位为毫秒级时间(41位的长度可以使用69年),
然后是5位datacenterId和5位workerId(10位的长度最多支持部署1024个节点) ,
最后12位是毫秒内的计数(12位的计数顺序号支持每个节点每毫秒产生4096个ID序号)
一共加起来刚好64位,为一个Long型。(转换成字符串长度为18)。
Snowflake算法核心把时间戳,工作机器id,序列号组合在一起。
整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由datacenter和机器ID作区分),
并且效率较高,经测试,snowflake每秒能够产生26万ID左右,完全满足需要。
分布式Snowflake雪花算法代码
public class SnowFlakeGenerator {
public static class Factory {
/**
* 每一部分占用位数的默认值
*/
private final static int DEFAULT_MACHINE_BIT_NUM = 5; //机器标识占用的位数
private final static int DEFAULT_IDC_BIT_NUM = 5;//数据中心占用的位数
private int machineBitNum;
private int idcBitNum;
public Factory() {
this.idcBitNum = DEFAULT_IDC_BIT_NUM;
this.machineBitNum = DEFAULT_MACHINE_BIT_NUM;
}
public Factory(int machineBitNum, int idcBitNum) {
this.idcBitNum = idcBitNum;
this.machineBitNum = machineBitNum;
}
public SnowFlakeGenerator create(long idcId, long machineId) {
return new SnowFlakeGenerator(this.idcBitNum, this.machineBitNum, idcId, machineId);
}
}
/**
* 起始的时间戳
* 作者写代码时的时间戳
*/
private final static long START_STAMP = 1508143349995L;
/**
* 可分配的位数
*/
private final static int REMAIN_BIT_NUM = 22;
/**
* idc编号
*/
private long idcId;
/**
* 机器编号
*/
private long machineId;
/**
* 当前序列号
*/
private long sequence = 0L;
/**
* 上次最新时间戳
*/
private long lastStamp = -1L;
/**
* idc偏移量:一次计算出,避免重复计算
*/
private int idcBitLeftOffset;
/**
* 机器id偏移量:一次计算出,避免重复计算
*/
private int machineBitLeftOffset;
/**
* 时间戳偏移量:一次计算出,避免重复计算
*/
private int timestampBitLeftOffset;
/**
* 最大序列值:一次计算出,避免重复计算
*/
private int maxSequenceValue;
private SnowFlakeGenerator(int idcBitNum, int machineBitNum, long idcId, long machineId) {
int sequenceBitNum = REMAIN_BIT_NUM - idcBitNum - machineBitNum;
if (idcBitNum <= 0 || machineBitNum <= 0 || sequenceBitNum <= 0) {
throw new IllegalArgumentException("error bit number");
}
this.maxSequenceValue = ~(-1 << sequenceBitNum);
machineBitLeftOffset = sequenceBitNum;
idcBitLeftOffset = idcBitNum + sequenceBitNum;
timestampBitLeftOffset = idcBitNum + machineBitNum + sequenceBitNum;
this.idcId = idcId;
this.machineId = machineId;
}
/**
* 产生下一个ID
*/
public synchronized long nextId() {
long currentStamp = getTimeMill();
if (currentStamp < lastStamp) {
throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastStamp - currentStamp));
}
//新的毫秒,序列从0开始,否则序列自增
if (currentStamp == lastStamp) {
sequence = (sequence + 1) & this.maxSequenceValue;
if (sequence == 0L) {
//Twitter源代码中的逻辑是循环,直到下一个毫秒
lastStamp = tilNextMillis();
// throw new IllegalStateException("sequence over flow");
}
} else {
sequence = 0L;
}
lastStamp = currentStamp;
return (currentStamp - START_STAMP) << timestampBitLeftOffset | idcId << idcBitLeftOffset | machineId << machineBitLeftOffset | sequence;
}
private long getTimeMill() {
return System.currentTimeMillis();
}
private long tilNextMillis() {
long timestamp = getTimeMill();
while (timestamp <= lastStamp) {
timestamp = getTimeMill();
}
return timestamp;
}
}
分布式Snowflake雪花算法的更多相关文章
- 分布式ID生成器 snowflake(雪花)算法
在springboot的启动类中引入 @Bean public IdWorker idWorkker(){ return new IdWorker(1, 1); } 在代码中调用 @Autowired ...
- 说起分布式自增ID只知道UUID?SnowFlake(雪花)算法了解一下(Python3.0实现)
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_155 但凡说起分布式系统,我们肯定会对一些海量级的业务进行分拆,比如:用户表,订单表.因为数据量巨大一张表完全无法支撑,就会对其进 ...
- .Net Core ORM选择之路,哪个才适合你 通用查询类封装之Mongodb篇 Snowflake(雪花算法)的JavaScript实现 【开发记录】如何在B/S项目中使用中国天气的实时天气功能 【开发记录】微信小游戏开发入门——俄罗斯方块
.Net Core ORM选择之路,哪个才适合你 因为老板的一句话公司项目需要迁移到.Net Core ,但是以前同事用的ORM不支持.Net Core 开发过程也遇到了各种坑,插入条数多了也特别 ...
- 第2-2-4章 常见组件与中台化-常用组件服务介绍-分布式ID-附Snowflake雪花算法的代码实现
目录 2.3 分布式ID 2.3.1 功能概述 2.3.2 应用场景 2.3.3 使用说明 2.3.4 项目截图 2.3.5 Snowflake雪花算法的代码实现 2.3 分布式ID 2.3.1 功能 ...
- 分布式主键解决方案之--Snowflake雪花算法
0--前言 对于分布式系统环境,主键ID的设计很关键,什么自增intID那些是绝对不用的,比较早的时候,大部分系统都用UUID/GUID来作为主键,优点是方便又能解决问题,缺点是插入时因为UUID/G ...
- snowflake 雪花算法 分布式实现全局id生成
snowflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID. 这种方案大致来说是一种以划分命名空间(UUID也算,由于比较常见,所以单独分析)来生成ID的一种算法,这种方案 ...
- Snowflake(雪花算法)的JavaScript实现
现在好多的ID都是服务器端生成的,当然JS也可以生成GUID或者UUID之类的,但是如果想要有序……这时就想到了雪花算法,但是都知道JS中Number的最大值为Number.MAX_SAFE_INTE ...
- Go语言实现Snowflake雪花算法
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com/archives/527 每次放长假的在家里的时候,总想找点简单的例子来看看实现原理,这 ...
- 【spring cloud】分布式ID,雪花算法
分布式ID生成服务 参考地址:https://blog.csdn.net/wangkang80/article/details/77914849 算法描述: 最高位是符号位,始终为0,不可用. 41位 ...
随机推荐
- day 13
递归函数 一.初始递归 递归函数:在一个函数里在调用这个函数本身. 递归的最大深度:998 正如你们刚刚看到的,递归函数如果不受到外力的阻止会一直执行下去.但是我们之前已经说过关于函数调用的问题, ...
- [C++/Python] 如何在C++中使用一个Python类? (Use Python-defined class in C++)
最近在做基于OpenCV的车牌识别, 其中需要用到深度学习的一些代码(Python), 所以一开始的时候开发语言选择了Python(祸患之源). 固然现在Python的速度不算太慢, 但你一定要用Py ...
- 网络之 Iptables总结
查询iptables -L 默认 filter表iptables -L -t filteriptables -L -t natiptables -L -t mangle Filter表service ...
- 通过 JDK 自带的 javap 命令查看 SynchronizedDemo 类的相关字节码信息
首先切换到类的对应目录执行 javac SynchronizedDemo.java 命令生成编译后的 .class 文件 然后执行 javap -c -s -v -l SynchronizedDemo ...
- nginx屏蔽某段IP、某个国家的IP
nginx中可通过写入配置文件的方法来达到一定的过滤IP作用,可使用deny来写. deny的使用方法可用于前端服务器无防护设备的时候过滤一些异常IP,过滤的client ip会被禁止再次访问,起到一 ...
- OLAP + MDX
基本概念 维度(Dimension):表示数据的属性,一个维度一般会有一个维表(也可能多个),事实表会有一个字段关联维表. 退化维度:有的维度可以没有维度表,因为这种维度比较简单,没有更多属性,没有必 ...
- mySQL 判断表是否存
select `TABLE_NAME` from `INFORMATION_SCHEMA`.`TABLES` where `TABLE_SCHEMA`='数据库名' and `TABLE_NAME`= ...
- NetCore 控制台读取配置文件
依赖: Microsoft.Extensions.Configuration Microsoft.Extensions.Configuration.Binder Microsoft.Extension ...
- python:带参数的装饰器,函数的有用信息
一.带参数的装饰器,函数的有用信息 def func1(): '''此函数的功能是完成的登陆的功能 return: 返回值是登陆成功与否(true,false) ''' print(333) func ...
- processjs Documentation
Documentation Paul Nieuwelaar edited this page on 20 Sep 2017 · 4 revisions Installation & Usa ...