Spark动态资源分配-Dynamic Resource Allocation
Spark动态资源分配-Dynamic Resource Allocation
关键字:spark、资源分配、dynamic resource allocation
Spark中,所谓资源单位一般指的是executors,和Yarn中的Containers一样,在Spark On Yarn模式下,通常使用–num-executors来指定Application使用的executors数量,而–executor-memory和–executor-cores分别用来指定每个executor所使用的内存和虚拟CPU核数。相信很多朋友至今在提交Spark应用程序时候都使用该方式来指定资源。
假设有这样的场景,如果使用Hive,多个用户同时使用hive-cli做数据开发和分析,只有当用户提交执行了Hive SQL时候,才会向YARN申请资源,执行任务,如果不提交执行,无非就是停留在Hive-cli命令行,也就是个JVM而已,并不会浪费YARN的资源。现在想用Spark-SQL代替Hive来做数据开发和分析,也是多用户同时使用,如果按照之前的方式,以yarn-client模式运行spark-sql命令行(http://lxw1234.com/archives/2015/08/448.htm),在启动时候指定–num-executors 10,那么每个用户启动时候都使用了10个YARN的资源(Container),这10个资源就会一直被占用着,只有当用户退出spark-sql命令行时才会释放。
spark-sql On Yarn,能不能像Hive一样,执行SQL的时候才去申请资源,不执行的时候就释放掉资源呢,其实从Spark1.2之后,对于On Yarn模式,已经支持动态资源分配(Dynamic Resource Allocation),这样,就可以根据Application的负载(Task情况),动态的增加和减少executors,这种策略非常适合在YARN上使用spark-sql做数据开发和分析,以及将spark-sql作为长服务来使用的场景。
本文以Spark1.5.0和hadoop-2.3.0-cdh5.0.0,介绍在spark-sql On Yarn模式下,如何使用动态资源分配策略。
YARN的配置
首先需要对YARN的NodeManager进行配置,使其支持Spark的Shuffle Service。
- 修改每台NodeManager上的yarn-site.xml:
##修改
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle,spark_shuffle</value>
</property>
##增加
<property>
<name>yarn.nodemanager.aux-services.spark_shuffle.class</name>
<value>org.apache.spark.network.yarn.YarnShuffleService</value>
</property>
<property>
<name>spark.shuffle.service.port</name>
<value>7337</value>
</property>
- 将$SPARK_HOME/lib/spark-1.5.0-yarn-shuffle.jar拷贝到每台NodeManager的${HADOOP_HOME}/share/hadoop/yarn/lib/下。
- 重启所有NodeManager。
Spark的配置
配置$SPARK_HOME/conf/spark-defaults.conf,增加以下参数:
- spark.shuffle.service.enabled true //启用External shuffle Service服务
- spark.shuffle.service.port 7337 //Shuffle Service服务端口,必须和yarn-site中的一致
- spark.dynamicAllocation.enabled true //开启动态资源分配
- spark.dynamicAllocation.minExecutors 1 //每个Application最小分配的executor数
- spark.dynamicAllocation.maxExecutors 30 //每个Application最大并发分配的executor数
- spark.dynamicAllocation.schedulerBacklogTimeout 1s
- spark.dynamicAllocation.sustainedSchedulerBacklogTimeout 5s
- 动态资源分配策略:
开启动态分配策略后,application会在task因没有足够资源被挂起的时候去动态申请资源,这种情况意味着该application现有的executor无法满足所有task并行运行。spark一轮一轮的申请资源,当有task挂起或等待spark.dynamicAllocation.schedulerBacklogTimeout(默认1s)时间的时候,会开始动态资源分配;之后会每隔spark.dynamicAllocation.sustainedSchedulerBacklogTimeout(默认1s)时间申请一次,直到申请到足够的资源。每次申请的资源量是指数增长的,即1,2,4,8等。
之所以采用指数增长,出于两方面考虑:其一,开始申请的少是考虑到可能application会马上得到满足;其次要成倍增加,是为了防止application需要很多资源,而该方式可以在很少次数的申请之后得到满足。
- 资源回收策略
当application的executor空闲时间超过spark.dynamicAllocation.executorIdleTimeout(默认60s)后,就会被回收。
使用spark-sql On Yarn执行SQL,动态分配资源
- ./spark-sql --master yarn-client \
- --executor-memory 1G \
- -e "SELECT COUNT(1) FROM ut.t_ut_site_log where pt >= '2015-12-09' and pt <= '2015-12-10'"

该查询需要123个Task。
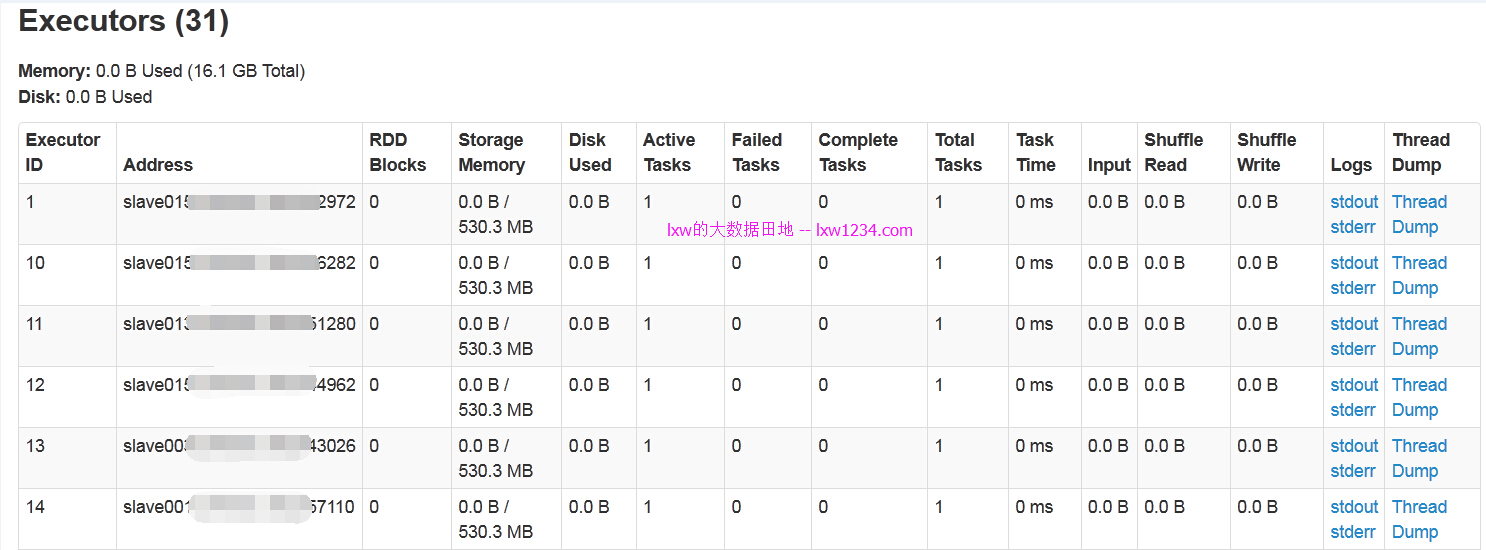
从AppMaster的WEB界面可以看到,总共有31个Executors,其中一个是Driver,既有30个Executors并发执行,而30,正是在spark.dynamicAllocation.maxExecutors参数中配置的最大并发数。如果一个查询只有10个Task,那么只会向Yarn申请10个executors的资源。
需要注意:
如果使用
./spark-sql –master yarn-client –executor-memory 1G
进入spark-sql命令行,在命令行中执行任何SQL查询,都不会执行,原因是spark-sql在提交到Yarn时候,已经被当成一个Application,而这种,除了Driver,是不会被分配到任何executors资源的,所有,你提交的查询因为没有executor而不能被执行。
而这个问题,我使用Spark的ThriftServer(HiveServer2)得以解决。
使用Thrift JDBC方式执行SQL,动态分配资源
首选以yarn-client模式,启动Spark的ThriftServer服务,也就是HiveServer2.
- 配置ThriftServer监听的端口号和地址
- vi $SPARK_HOME/conf/spark-env.sh
- export HIVE_SERVER2_THRIFT_PORT=10000
- export HIVE_SERVER2_THRIFT_BIND_HOST=0.0.0.0
- 以yarn-client模式启动ThriftServer
- cd $SPARK_HOME/sbin/
- ./start-thriftserver.sh \
- --master yarn-client \
- --conf spark.driver.memory=3G \
- --conf spark.shuffle.service.enabled=true \
- --conf spark.dynamicAllocation.enabled=true \
- --conf spark.dynamicAllocation.minExecutors=1 \
- --conf spark.dynamicAllocation.maxExecutors=30 \
- --conf spark.dynamicAllocation.sustainedSchedulerBacklogTimeout=5s
启动后,ThriftServer会在Yarn上作为一个长服务来运行:

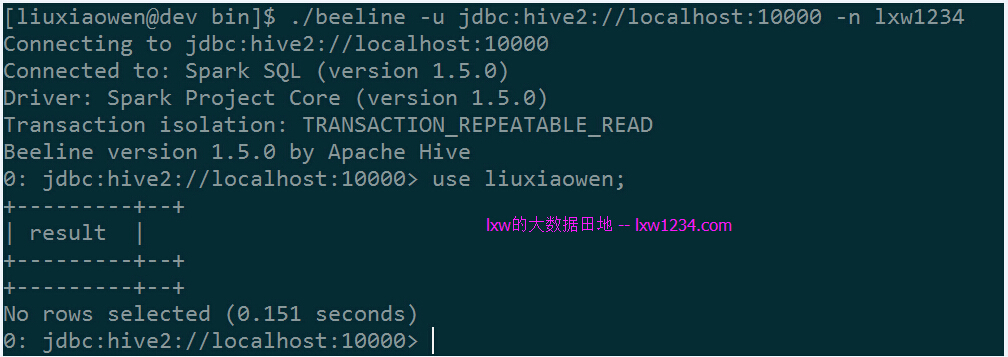
- 使用beeline通过JDBC连接spark-sql
- cd $SPARK_HOME/bin
- ./beeline -u jdbc:hive2://localhost:10000 -n lxw1234
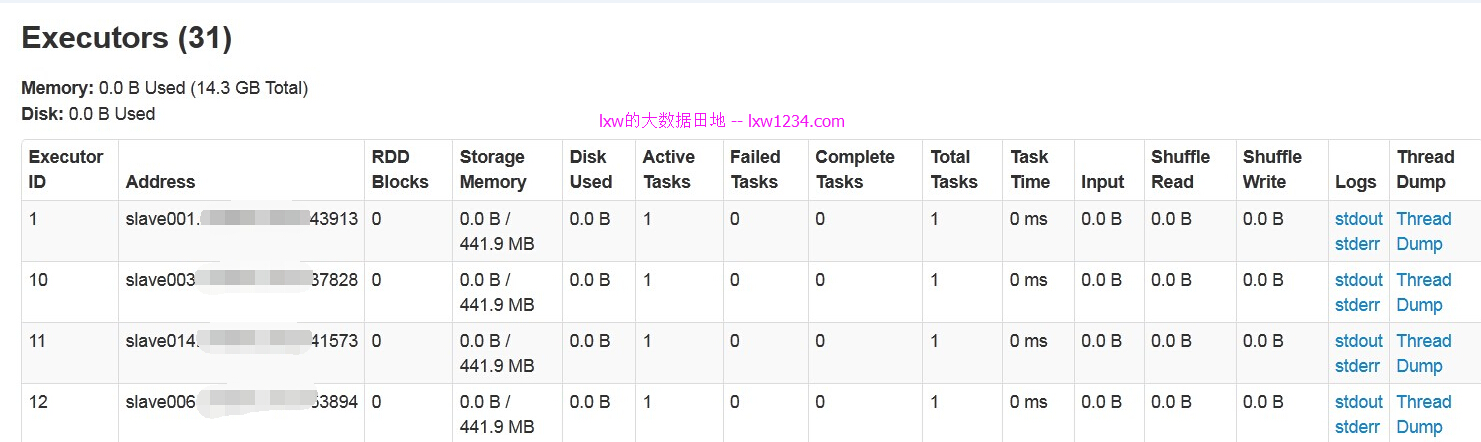
执行查询:
select count(1) from ut.t_ut_site_log where pt = ‘2015-12-10′;
该任务有64个Task:

而监控页面上的并发数仍然是30:
执行完后,executors数只剩下1个,应该是缓存数据,其余的全部被回收:
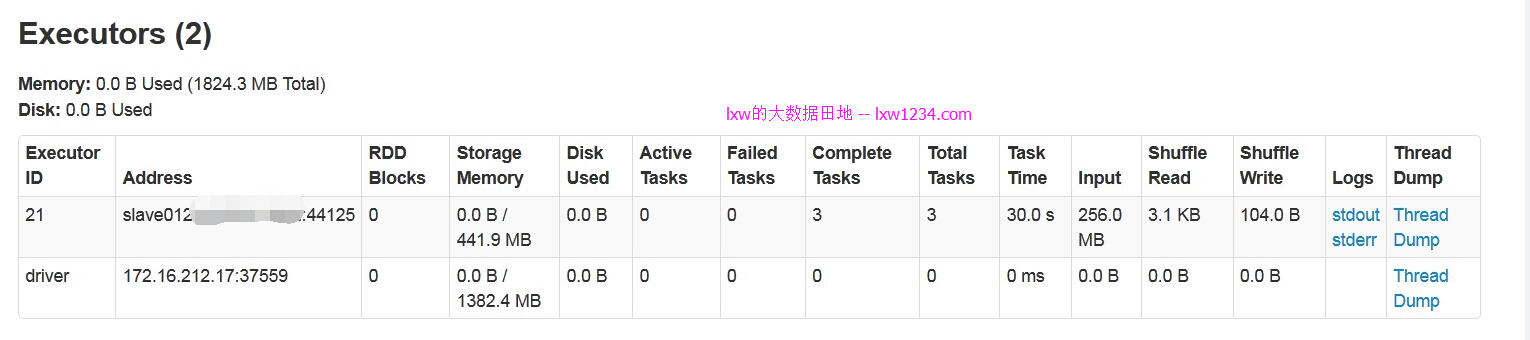
这样,多个用户可以通过beeline,JDBC连接到Thrift Server,执行SQL查询,而资源也是动态分配的。
需要注意的是,在启动ThriftServer时候指定的spark.dynamicAllocation.maxExecutors=30,是整个ThriftServer同时并发的最大资源数,如果多个用户同时连接,则会被多个用户共享竞争,总共30个。
这样,也算是解决了多用户同时使用spark-sql,并且动态分配资源的需求了。
Spark动态资源分配官方文档:http://spark.apache.org/docs/1.5.0/job-scheduling.html#dynamic-resource-allocation
Spark动态资源分配-Dynamic Resource Allocation的更多相关文章
- 记一次有关spark动态资源分配和消息总线的爬坑经历
问题: 线上的spark thriftserver运行一段时间以后,ui的executor页面上显示大量的active task,但是从job页面看,并没有任务在跑.此外,由于在yarn mode下, ...
- 利用动态资源分配优化Spark应用资源利用率
背景 在某地市开展项目的时候,发现数据采集,数据探索,预处理,数据统计,训练预测都需要很多资源,现场资源不够用. 目前该项目的资源3台旧的服务器,每台的资源 内存为128G,cores 为24 (co ...
- 「Spark从精通到重新入门(二)」Spark中不可不知的动态资源分配
前言 资源是影响 Spark 应用执行效率的一个重要因素.Spark 应用中真正执行 task 的组件是 Executor,可以通过spark.executor.instances 指定 Spark ...
- spark动态资源(executor)分配
spark动态资源调整其实也就是说的executor数目支持动态增减,动态增减是根据spark应用的实际负载情况来决定. 开启动态资源调整需要(on yarn情况下) 1.将spark.dynamic ...
- Dynamic Resource – 动态资源
Dynamic Resource – 动态资源 与Static Resource不同的是,Dynamic Resource可以在程序运行时重新评估/计算资源来生成对应的对象/值,它支持向前引用,只 ...
- 动态内存分配(Dynamic memory allocation)
下面的代码片段的输出是什么?为什么? 解析:这是一道动态内存分配(Dynamic memory allocation)题. 尽管不像非嵌入式计算那么常见,嵌入式系统还是有从堆(heap)中动态分 ...
- PatentTips - Systems, methods, and devices for dynamic resource monitoring and allocation in a cluster system
BACKGROUND 1. Field The embodiments of the disclosure generally relate to computer clusters, and m ...
- WPF 用代码调用dynamic resource动态更改背景 - CSDN博客
原文:WPF 用代码调用dynamic resource动态更改背景 - CSDN博客 一般dynamic resoource通常在XAML里调用,如下范例: <Button Click=&qu ...
- spark on yarn 动态资源分配报错的解决:org.apache.hadoop.yarn.exceptions.InvalidAuxServiceException: The auxService:spark_shuffle does not exist
组件:cdh5.14.0 spark是自己编译的spark2.1.0-cdh5.14.0 第一步:确认spark-defaults.conf中添加了如下配置: spark.shuffle.servic ...
随机推荐
- linux-ifconfig 查看没有IP
ifconfig 查看没有IP,如图: 解决方法: 1.切换路径到 2.进入编辑ifcfg-ens33文件(文件名可能不同)模式 3.ONBOOT改为yes 4.点击ESC,输入:wq进行保存 5.输 ...
- set_lb
修改lb权重,通知钉钉 前提需要安装阿里的核心库 #!/usr/local/python-3.6.4/bin/python3 #coding=utf-8 from aliyunsdkcore.clie ...
- Linux 系统管理 : last 命令详解
原文 last命令用于显示用户最近登录信息.单独执行last命令,它会读取/var/log/wtmp的文件,并把该给文件的内容记录的登入系统的用户名单全部显示出来 语法 last(选项)(参数) 选项 ...
- 【前端_js】array.forEach和$.each()及$().each()的用法与区别
1.$.each():方法是jQuery中的方法,用于遍历数组或对象.用法:$.each(array,function(index,value){...}),有两个参数,第一个为待遍历的数组或对象,第 ...
- pip问题:ImportError: cannot import name main
问题描述 今天使用pip安装python包的时候,提示可以升级到最新版的pip,然后就升级了pip,从8.1.1到19.0.3,结果,就出现了下面的问题,pip不能用了: Traceback (mos ...
- Cleaning Robot POJ - 2688
题目链接:https://vjudge.net/problem/POJ-2688 题意:在一个地面上,有一个扫地机器人,有一些障碍物,有一些脏的地砖,问,机器热能不能清扫所有的地砖, (机器人不能越过 ...
- Java并发编程:ThreadPoolExecutor + Callable + Future(FutureTask) 探知线程的执行状况
如题 (总结要点) 使用ThreadPoolExecutor来创建线程,使用Callable + Future 来执行并探知线程执行情况: V get (long timeout, TimeUnit ...
- js--获取和设置css属性
在这一章我们讲述一下如何通过js来操作css中的属性 1,首先,我们想获取元素的一些属性.例如innerHTML,value等值时,我们可以 var object=document.getELemen ...
- mysql-xtrabackup备份恢复
1.xtrabackup的安装 8.0版本-支持mysql8 wget https://www.percona.com/downloads/Percona-XtraBackup-LATEST/Perc ...
- 项目Beta冲刺(团队)——05.28(6/7)
项目Beta冲刺(团队)--05.28(6/7) 格式描述 课程名称:软件工程1916|W(福州大学) 作业要求:项目Beta冲刺(团队) 团队名称:为了交项目干杯 作业目标:记录Beta敏捷冲刺第6 ...