hbase 安装(集群模式)
环境:jdk 1.8 + hadoop2.7.6+zookeeper3.4.9+centos7
一.安装zookeeper(集群模式)
0.安装机器
ip hostname
192.168.100.9 ns1
192.168.100.10 dn1
2.zookeeper tar包一栋至 ns1的 /usr/local,解压
tar -zxvf zookeeper-3.4..tar.gz
3.修改zk配置文件
cd /usr/local/zookeeper-3.4./conf cp zoo_sample.cfg zoo.cfg
修改配置文件zoo.cfg(所有节点的配置文件相同)
#tickTime这个时间是作为zookeeper服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是说每个tickTime时间就会发送一个心跳
tickTime=
#initLimit这个配置项是用来配置zookeeper接受客户端(这里所说的客户端不是用户连接zookeeper服务器的客户端,而是zookeeper服务器集群中连接到leader的follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数
initLimit=
#syncLimit这个配置项标识leader与follower之间发送消息,请求和应答时间长度,最长不能超过多少个tickTime的时间长度,总的时间长度就是5*=10秒
syncLimit=
#dataDir顾名思义就是zookeeper保存日志的目录
dataLogDir=/usr/local/zookeeper-3.4./logs
#dataDir顾名思义就是zookeeper保存数据的目录
dataDir=/usr/local/zookeeper-3.4./data
#clientPort这个端口就是客户端连接Zookeeper服务器的端口,Zookeeper会监听这个端口接受客户端的访问请求;
clientPort=
#这个参数指定了需要保留的文件数目
autopurge.snapRetainCount=
#3.4.0及之后版本,ZK提供了自动清理事务日志和快照文件的功能,这个参数指定了清理频率,单位是小时,需要配置一个1或更大的整数,默认是0,表示不开启自动清理功能。(No Java system property) New in 3.4.
autopurge.purgeInterval=
#server.A=B:C:D中的A是一个数字,表示这个是第几号服务器,B是这个服务器的IP地址,C第一个端口用来集群成员的信息交换,表示这个服务器与集群中的leader服务器交换信息的端口,D是在leader挂掉时专门用来进行选举leader所用的端口。
server.= 192.168.100.9::
server.= 192.168.100.10::
新建配置中的log data目录
4.配置myid
除了修改zoo.cfg配置文件外,zookeeper集群模式下还要配置一个myid文件,这个文件需要放在dataDir目录下。
这个文件里面有一个数据就是A的值(该A就是zoo.cfg文件中server.A=B:C:D中的A),在zoo.cfg文件中配置的dataDir路径中创建myid文件。
#在192.168.1.148服务器上面创建myid文件,并设置值为1,同时与zoo.cfg文件里面的server.1保持一致,如下
echo "" > /usr/local/zookeeper-3.4./data/myid
在 dn1 上执行如下命令
echo "" > /usr/local/zookeeper-3.4./data/myid
5.添加环境变量
在两个节点的 /etc/profile中添加如下语句
export ZOOKEEPER_HOME=/usr/local/zookeeper-3.4.
export PATH=${ZOOKEEPER_HOME}/bin:${PATH}
刷新环境变量
source /etc/profile
6.每个节点都启动zk 进行测试
sh /usr/local/zookeeper-3.4./bin/zkServer.sh start
查看状态:
sh /usr/local/zookeeper-3.4./bin/zkServer.sh status
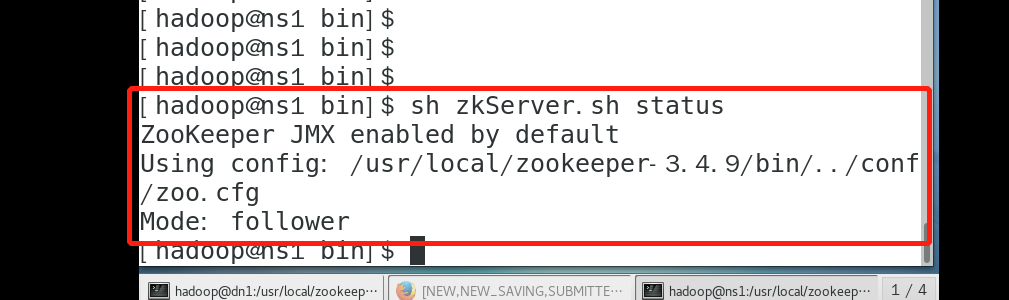
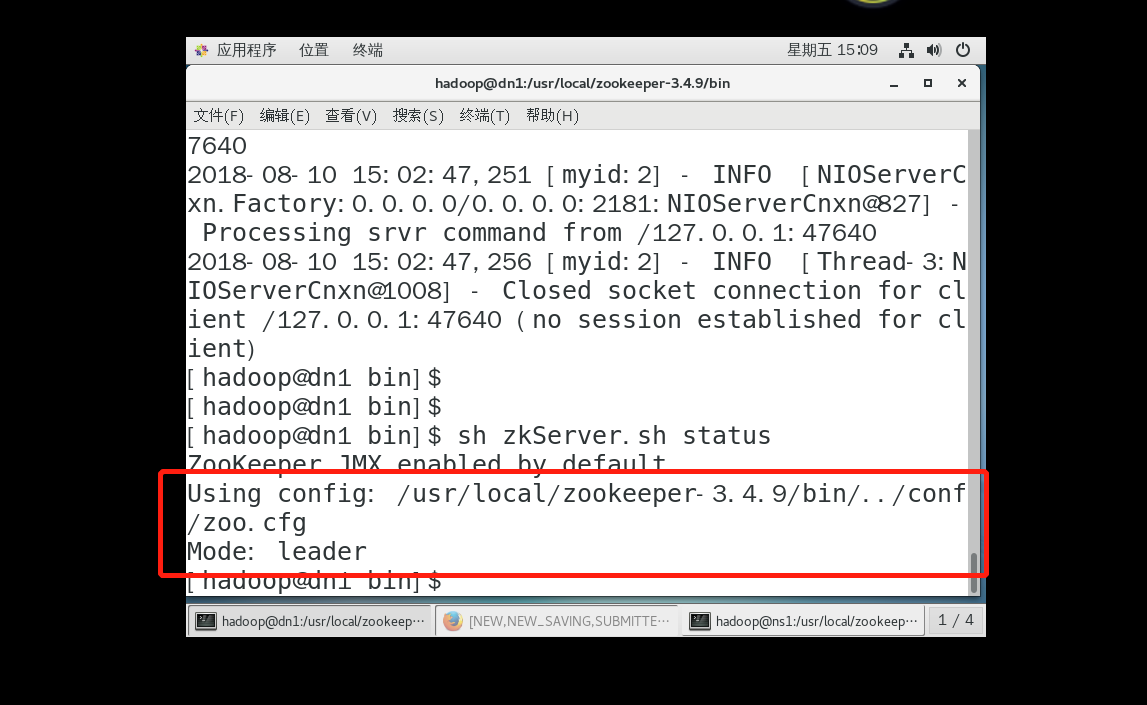
二 hbase 安装
1.下载hbase
2.解压到/user/local
tar -zxvf hbase-2.1.-bin.tar.gz
3.配置
cd /usr/local/hbase-2.1.0/conf
hbase-site.xml 修改如下
<configuration>
<!--此处的bx为以前搭建hdfs集群时,使用的那个集群代号-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://ns1:9000/hbase</value>
</property>
<!--指定集群的几台zookeeper主机名-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>ns1,dn1</value>
</property>
<!--设置使用zookeeper集群,true为使用-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property> <property>
<name>hbase.tmp.dir</name>
<value>/usr/local/hbase-2.1./tmp</value>
</property>
<!--ui端口,可通过ns1:60010访问web-->
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
</property>
</configuration>
hbase-env.sh 修改如下
#设置补充hbase 自带的zk
export HBASE_MANAGES_ZK=false
export JAVA_HOME=/usr/local/jdk
regionservers 添加节点
ns1
dn1
赋值hadoop core-site.xml ,hdfs-site.xml 到 /usr/local/hbase-2.1.0/conf
4.启动
ns1 上执行
sh /usr/local/hbase-2.1./bin/start-hbase.sh
5,查看状态
ns1 查看
[hadoop@ns1 bin]$ jps
HRegionServer
SecondaryNameNode
JobHistoryServer
HistoryServer
DataNode
Worker
Jps
38408 HMaster #hbase master
QuorumPeerMain
NameNode
Master
NodeManager
dn1 查看
[hadoop@dn1 local]$ jps
26754 HRegionServer #regionserver 已启动
Worker
Jps
QuorumPeerMain
DataNode
NodeManager
hbase 安装(集群模式)的更多相关文章
- Eclipse的下载、安装和WordCount的初步使用(本地模式和集群模式)
包括: Eclipse的下载 Eclipse的安装 Eclipse的使用 本地模式或集群模式 Scala IDE for Eclipse的下载.安装和WordCount的初步使用(本地模式和集群 ...
- IntelliJ IDEA的下载、安装和WordCount的初步使用(本地模式和集群模式)
包括: IntelliJ IDEA的下载 IntelliJ IDEA的安装 IntelliJ IDEA中的scala插件安装 用SBT方式来创建工程 或 选择Scala方式来创建工程 本地模式或集群 ...
- IntelliJ IDEA(Community版本)的下载、安装和WordCount的初步使用(本地模式和集群模式)
不多说,直接上干货! 对于初学者来说,建议你先玩玩这个免费的社区版,但是,一段时间,还是去玩专业版吧,这个很简单哈,学聪明点,去搞到途径激活!可以看我的博客. 包括: IntelliJ IDEA(Co ...
- Greenplum源码编译安装(单机及集群模式)完全攻略
公司有个项目需要安装greenplum数据库,让我这个gp小白很是受伤,在网上各种搜,结果找到的都是TMD坑货帖子,但是经过4日苦战,总算是把greenplum的安装弄了个明白,单机及集群模式都部署成 ...
- Scala IDE for Eclipse的下载、安装和WordCount的初步使用(本地模式和集群模式)
包括: Scala IDE for Eclipse的下载 Scala IDE for Eclipse的安装 本地模式或集群模式 我们知道,对于开发而言,IDE是有很多个选择的版本.如我们大部分人经常 ...
- Hadoop学习笔记(4)hadoop集群模式安装
具体的过程参见伪分布模式的安装,集群模式的安装和伪分布模式的安装基本一样,只有细微的差别,写在下面: 修改masers和slavers文件: 在hadoop/conf文件夹中的配置文件中有两个文件ma ...
- 1.8分布式集群模式基础(VM安装多台服务器)
前言 一晃就是10几天,学习的过程是断断续续的,对个人来说,这并不是一个良好的状态.在这10几天了,迷恋起了PS... 从今天起,坚持一周4篇,额.希望吧 在之前的随笔中,我安装了Xshell 和 C ...
- Hbase的集群安装
hadoop集群的搭建 搭建真正的zookeeper集群 Hbase需要安装在成功部署的Hadoop平台,并且要求Hadoop已经正常启动. 同时,HBase需要集群部署,我们分别把HBase 部署到 ...
- IntelliJ IDEA(Ultimate版本)的下载、安装和WordCount的初步使用(本地模式和集群模式)
不多说,直接上干货! IntelliJ IDEA号称当前Java开发效率最高的IDE工具.IntelliJ IDEA有两个版本:社区版(Community)和旗舰版(Ultimate).社区版时免费的 ...
随机推荐
- HTTP权威指南 目录
diyi部分 HTTP:Web的基础 第1章 HTTP概述 31.1 HTTP——因特网的多媒体信使 41.2 Web客户端和服务器 41.3 资源 51.3.1 媒体类型 61.3.2 URI 71 ...
- 一种动态的样式语言--Less 之 命名空间
LESS 命名空间 如果想更好的组织CSS或者单纯是为了更好的封闭,将一些变量或者混合模块打包起来,你像下面这样在#bundle中定义一些属性集之后可以重复使用: #bundle{ .button() ...
- UEditor富文本WEB编辑器设置代码高亮
UEditor编译器支持代码高亮显示,设置方法如下: 1.页面head引入UEditor类包文件shCore.js.shCoreDefault.css代码 (注:引入文件路径根据需求变更即可) < ...
- css实现块级元素水平垂直居中的方法?
父级给相对定位,子级给绝对定位,margin设置为auto,上下左右值设为0. 父级给相对定位,子级给绝对定位,设置left和top为50%,再向左和向上移动负的子级一半. 父级设置display:f ...
- VMware Tools安装后设置自动挂载解决共享文件夹无法显示的问题
一. 确保成功安装了VMware Tools 二. 使用如下命令 1.apt-get install open-vm-tools 2.vmhgfs-fuse .host:/ /mnt/hgfs ...
- Python逆向(二)—— pyc文件结构分析
一.前言 上一节我们知道了pyc文件是python在编译过程中出现的主要中间过程文件.pyc文件是二进制的,可以由python虚拟机直接执行的程序.分析pyc文件的文件结构对于实现python编译与反 ...
- MSSQL数据库 1000W数据优化整理
GO SET STATISTICS TIME ON SELECT count([StyleId]) FROM [dbo].[Ky_Style] SET STATISTICS TIME OFF SET ...
- CentOS 7 上 安装 jira
步骤 .安装jdk8 https://www.cnblogs.com/sea-stream/p/10404360.html .安装mysql wget -i -c http://dev.mysql.c ...
- dedecms复制网上的带有图片的文章,图片不能自动下载到本地的解决方法
dede有时看到比较好的文章需要复制,粘贴到自己的dede后台发布,dede是有图片自动本地化的功能,就是复制过来后自动下载到你的服务器上了,这样省去了你单独去另存图片再上传的过程,尤其是遇到有很多图 ...
- EventHandler
表示将处理不包含事件数据的事件的方法 作用:这句话的意思就是把这两个事放在一起了,意思就是叫你吃完饭了喊我一声.我委托你吃完饭了,喊我一声.这样我就不用过一会就来看一下你吃完了没有了,已经委托你了.