【RS】AutoRec: Autoencoders Meet Collaborative Filtering - AutoRec:当自编码器遇上协同过滤
【论文标题】AutoRec: Autoencoders Meet Collaborative Filtering (WWW'15)
【论文作者】Suvash Sedhain †∗ , Aditya Krishna Menon †∗ , Scott Sanner †∗ , Lexing Xie ∗†
【论文链接】Paper(2-pages // Double column)
<札记非FY>
====================首先,AutoEncoder 是什么?[ref-1]====================

 。本质上AE是学习到了一个原始输入的一个向量表达。
。本质上AE是学习到了一个原始输入的一个向量表达。=======================关于论文内容==============================
【概要简介】- [ref-2]
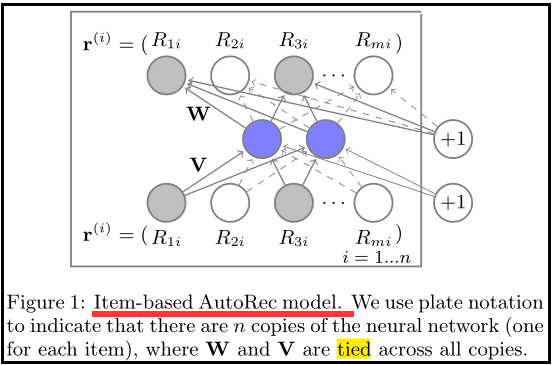

m:用户数


3、AutoRec 模型
AutoRec 在传统 AutoEncoder的基础上做了如下的变化:
- 损失函数只和观察到的元素有关
- 加上正则化项


对比实验,基线:RBM-CF
AutoRec和RBM-CF的区别:
- RBM是生成模型,AutoRec是判别模型
- RBM通过极大化对数似然来估计参数,AR直接用极小化RMSE
- 训练中,RBM需要用对比散度,AR直接用梯度下降
- RBM只能预测离散分数
- 参数量:RBM-CF:nkr(or mkr)AutoRec:nk(or mk)
实验结果:

通过对比各个模型的实验结果:
(1)item-based AutoRec胜出user-based AutoRec,比传统的FM类方法都要更好。(这可能是由于每个项目评分的平均数量是高于每个用户的输入评分数;用户评分数量的高方差导致基于用户的方法的预测不可靠)。
(2)sigmoid好于RELU。
(3)随着hidden 层节点数增加,RMSE越来越小。
【Reference】
1、https://blog.csdn.net/studyless/article/details/70880829
2、https://www.jianshu.com/p/4aadd0bdc901
3、https://blog.csdn.net/qq_40006058/article/details/87936043
【RS】AutoRec: Autoencoders Meet Collaborative Filtering - AutoRec:当自编码器遇上协同过滤的更多相关文章
- [转]-[携程]-A Hybrid Collaborative Filtering Model with Deep Structure for Recommender Systems
原文链接:推荐系统中基于深度学习的混合协同过滤模型 近些年,深度学习在语音识别.图像处理.自然语言处理等领域都取得了很大的突破与成就.相对来说,深度学习在推荐系统领域的研究与应用还处于早期阶段. 携程 ...
- 【翻译】Neural Collaborative Filtering--神经协同过滤
[说明] 本文翻译自新加坡国立大学何向南博士 et al.发布在<World Wide Web>(2017)上的一篇论文<Neural Collaborative Filtering ...
- 【RS】Sparse Probabilistic Matrix Factorization by Laplace Distribution for Collaborative Filtering - 基于拉普拉斯分布的稀疏概率矩阵分解协同过滤
[论文标题]Sparse Probabilistic Matrix Factorization by Laplace Distribution for Collaborative Filtering ...
- 【RS】Factorization Meets the Neighborhood: a Multifaceted Collaborative Filtering Model - 当因式分解遇上邻域:多层面协同过滤模型
[论文标题]Factorization Meets the Neighborhood: a Multifaceted Collaborative Filtering Model (35th-ICM ...
- 【RS】List-wise learning to rank with matrix factorization for collaborative filtering - 结合列表启发排序和矩阵分解的协同过滤
[论文标题]List-wise learning to rank with matrix factorization for collaborative filtering (RecSys '10 ...
- 【RS】Amazon.com recommendations: item-to-item collaborative filtering - 亚马逊推荐:基于物品的协同过滤
[论文标题]Amazon.com recommendations: item-to-item collaborative filtering (2003,Published by the IEEE C ...
- 【RS】:论文《Neural Collaborative Filtering》的思路及模型框架
[论文的思路] NCF 框架如上: 1.输入层:首先将输入的user.item表示为二值化的稀疏向量(用one-hot encoding) 2.嵌入层(embedding):将稀疏表示映射为稠密向量( ...
- Collaborative filtering
Collaborative filtering, 即协同过滤,是一种新颖的技术.最早于1989年就提出来了,直到21世纪才得到产业性的应用.应用上的代表在国外有Amazon.com,Last. ...
- 协同滤波 Collaborative filtering 《推荐系统实践》 第二章
利用用户行为数据 简介: 用户在网站上最简单存在形式就是日志. 原始日志(raw log)------>会话日志(session log)-->展示日志或点击日志 用户行一般分为两种: 1 ...
随机推荐
- python 学习之 基础篇三 流程控制
前言: 一. python中有严格的格式缩进,因为其在语法中摒弃了“{}”来包含代码块,使用严格的缩进来体现代码层次所以在编写代码的时候项目组要严格的统一器缩进语法,一个tab按键设置为四个空格来缩进 ...
- 设计模式之(十一)代理模式(Proxy)
软件开发行业有一个观点:任务问题都可以添加一个中间层来解决.代理模式也是这个思想下的产物. 首先看下代理模式的定义:为其他对象提供一种代理以控制对这个对象的访问.就是把类委托给另外一个类,用这个类来控 ...
- 安装gcc-c++报错解决办法
问题 每次安装依赖包gcc-c++的时候,经常会遇到包如下错误 Error: Package: libstdc++-devel--.el7_4..x86_64 (ultra-centos-7.4- ...
- group by 两个字段
group by 的简单说明: group by 一般和聚合函数一起使用才有意义,比如 count sum avg等 使用group by的两个要素: (1) 出现在select后面的字段 要么 ...
- Linux命令查找文件目录
座右铭:长风破浪会有时,直挂云帆济沧海. linux一般查看文件或者目录有几种方法. /查看文件类容--------cat/more/less/head/tail 只能查看文本型(txt) (1) ...
- 【IntelliJ IDEA新手入门】IDEA如何快速搭建Java开发环境
作为IntelliJ IDEA mac新手,IDEA如何快速搭建Java开发环境呢? 今天小编就给大家带来了IntelliJ IDEA mac使用教程,想知道IDEA如何快速搭建Java开发环境?那就 ...
- mongo find 时间条件过滤
db.order.find({"order_time":{"$gte": new Date("Tue Jan 01 2017 00:00:00 GMT ...
- Java错误体系
1.Java所有的异常错误都继承与Throwable类,只有继承了Throwable类,才能在异常传递体系中进行. 2.Throwable下有两个重要的子类,Error和Exception Error ...
- 微软源码站点-C#编程指南
地址:https://referencesource.microsoft.com/#System.Web/HttpPostedFile.cs 微软的源码可以在这里看. ---------------- ...
- 洛谷P2365 任务安排(斜率优化dp)
传送门 思路: 最朴素的dp式子很好考虑:设\(dp(i,j)\)表示前\(i\)个任务,共\(j\)批的最小代价. 那么转移方程就有: \[ dp(i,j)=min\{dp(k,j-1)+(sumT ...