Oracle Spatial分区应用研究之七:同等分区粒度下全局索引优于分区索引的原因分析
1、实验结论
- 同等分区粒度下,使用分区空间索引进行空间查询,比使用全局空间索引进行查询,对数据字典表的访问次数更多。假设分区数为X,则大概多3X次访问。具体说明见6实验结论。
2、实验目的
在之前的测试中,发现这样一个现象:同等分区粒度下,分区空间索引效率不如全局空间索引。可是,深层次的原因是什么呢?
3、实验方法
分别以按县分区、按省分区组织数据,按县分区表共有2531个分区,按省分区表共有43个分区。数据内容为2531个区县,共46982394条要素。分别在两个分区表上创建本地空间索引。
开启10046事件,跟踪SDO_FILTER操作。使用tkpof分析trc文件中耗时最多的SQL,对根据绑定变量的值分析不同SQL(主要是对数据字典的递归查询)查询的数据内容。比较在使用分区索引时所查询的数据字典内容,与在使用全局索引时查询的数据字典内容。
4、实验结果
在使用分区空间索引时,按县分区与按省分区对数据字典的访问次数及返回记录数如下:
- Seg$
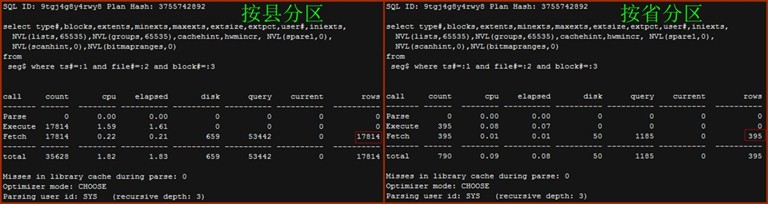
查询内容包括LOB INDEX PARTITION、LOB PARTITION、TABLE PARTITION、少量sys和mdsys用户下的表、其它表。
以按县分区表为例,包括:
INDEX PARTITION : 2531 * 3 = 7593 (此处不包括分区空间索引,仅包括LOB INDEX PARTITION)
LOB PARTITION : 2531 * 3 = 7593
TABLE PARTITION:2531
- Obj$
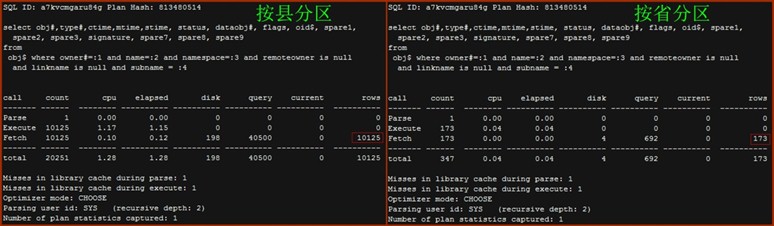
查询内容包括LOB PARTITION、SPATIAL INDEX PARTITION、相关的TABLE PARTITION
以按省分区表分为,包括:
LOB PARTITION : 43 * 3 =129
INDEX PARTITION : 43 (此处包括SPATIAL INDEX PARTITION ,不包括LOB INDEX PARTITION)
TABLE PARTITION : (仅包括与查询范围相关的分区,可忽略不计)
- Lobfrag$
查询内容与全局空间索引下一致。
- Indpart$
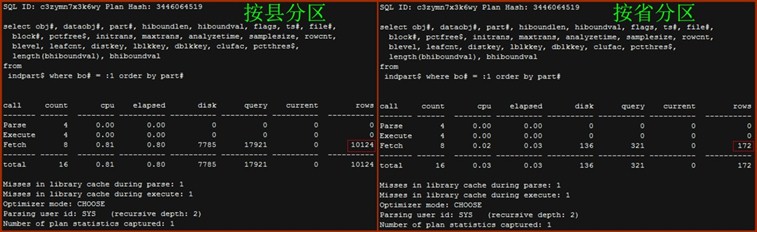
查询内容包括INDEX PARTITION,包括LOB INDEX PARTITON 以及 SPATIAL INDEX PARTITION。
以按省分区表为例,包括:
INDEX PARTITION : 43 * 4 =172
- Obj$(2)

查询内容包括LOB PARTITION、SPATIAL INDEX PARTITION,少量其它表。
以按省分区表为例,包括:
LOB PARTITION : 43 * 3 =129
INDEX PARTITION : 43 (此处包括SPATIAL INDEX PARTITION ,不包括LOB INDEX PARTITION)
其它:82个sys和mdsys用户下的表、以及test用户下的其他一些表,可忽略。
- Tabpart$
查询内容全局空间索引下一致。
5、实验结论
结合3实验结果中的说明,假设分区数以X表示,lob column个数以Y表示,在使用分区空间索引进行查询时,不同字典表的访问次数见下表:
|
数据字典表 |
访问次数 |
|
Seg$ |
(1+2Y)*X |
|
Lobfrag$ |
XY |
|
Obj$ |
(1+Y)*X |
|
Indpart$ |
(1+Y)*X |
|
Obj$(2) |
(1+Y)*X |
|
Tabpart$ |
X |
若已经获知对各数据字典表的平均访问时间,甚至可以估算查询耗时。在每例中seg$ 、lobfrag$ 、obj$ 、indpart$、obj$(2) 、tabpart$,各数据字典表的平均访问时间约为100us、240us、50us、150us、180us、120us。因此可估算时间为:
Elapsed all= 100*(1+2Y)*X+240XY+50*(1+Y)*X+150*(1+Y)X+180*(1+Y)*X+120X
=X(820Y+600)
与全局索引X(820Y+220)相比,查询数据字典多耗时380X(单位是us)。
Oracle Spatial分区应用研究之七:同等分区粒度下全局索引优于分区索引的原因分析的更多相关文章
- Oracle Spatial分区应用研究之三:县市省不同分区粒度的效率比较
在<Oracle Spatial分区应用研究之一:分区与分表查询性能对比>中已经说明:按县分区+全局空间索引效率要优于按县分区+本地空间索引,因此在该实验报告中,将不再考虑按县分区+本地空 ...
- Oracle Spatial分区应用研究之八:不同分区粒度在1.5亿要素量级下的查询性能
以土地调查地类图斑层作为测试数据,共计约1.5亿条要素.随机生成90次各比例尺的查询范围,在ORACLE 11gr2数据库中进行空间查询,记录查询耗时.最后计算平均值和第90百分位数,结果如下图所示: ...
- Oracle Spatial分区应用研究之五:不同分区粒度+本地空间索引效率对比
1.实验目的 若使用本地空间索引,不同分区粒度将产生不同索引组织,其索引分区个数.大小.R-TREE树结构均不相同.那么,在什么分区粒度下的本地空间索引效率较高呢? 2实验数据 实验数据为全国2531 ...
- Oracle Spatial分区应用研究之二:按县分区与按省分区对比测试报告
1.实验目的 在上一轮的实验中,oracle 11g r2版本下,在87县市实验数据的基础上,比较了分表与分区的效率,得出了分区+全局索引效率较高的结论(见上一篇博客).不过我们尚未比较过不同的分区粒 ...
- Oracle Spatial分区应用研究之六:全局空间索引下按县分区与按省分区效率差异原因分析
1.实验结论 全局空间索引下,不同分区粒度之所有效率会有不同,差异并不在于SDO_FILTER操作本身,而在于对于数据字典表的访问次数上: 分区越多.表上的lob column越多,对数据字典表的访问 ...
- Oracle 12C 新特性之表分区带 异步全局索引异步维护(一次add、truncate、drop、spilt、merge多个分区)
实验准备:-- 创建实验表CREATE TABLE p_andy(ID number(10), NAME varchar2(40))PARTITION BY RANGE (id)(PARTITION ...
- oracle 11g 分区表创建(自动按年、月、日分区)
前言:工作中有一张表一年会增长100多万的数据,量虽然不大,可是表字段多,所以一年下来也会达到 1G,而且只增不改,故考虑使用分区表来提高查询性能,提高维护性. oracle 11g 支持自动分区,不 ...
- Oracle分区表删除分区引发错误ORA-01502: 索引或这类索引的分区处于不可用状态
(一)问题: 最近在做Oracle数据清理,在对分区表进行数据清理时,采用的方法是drop partition,删除的过程中,没有遇到任何问题,大概过了10分钟,开发人员反馈部分分区表上的业务失败.具 ...
- Oracle同义词、索引、分区
同义词:是现有对象的一个别名 简化SQL语句 隐藏对象的名称和所有者 提供对对象的公共访问 同义词共有两种类型 私有同义词只能在其模式内访问,且不能与当前模式的对象同名 公有同义词可被所有的数据库用户 ...
随机推荐
- keywordAsVar.php
<?php //keywordAsVar.php #keywordAsVar.php $True="我是变量True"; echo($True); echo("&l ...
- MapReduce如何调优
Map阶段优化 1.在代码书写时优化,如尽量避免在map端创建变量等,因为map端是循环调用的,创建变量会增加内存的消耗,尽量将创建变量放到setup方法中 2.配置调优,可以在集群配置和任务运行时进 ...
- 在swift项目中若要通过pod引入第三方的swift项目,必须加上use_frameworks!
因为swift没法打.a https://www.jianshu.com/p/ac629a1cb8f5
- JSE,JEE,JME三者之间有什么区别
JAVA是一种面向对象语言由SUN公司出品 J针对不同的使用方向规划出J2SE,J2EE,J2ME三个版本 J2SE 指标准版一般用于用户学习JAVA语言的基础也是使用其他两个版本的基础主要用于编写C ...
- What Is React?--MVC
React is a declarative, efficient, and flexible JavaScript library for building user interfaces. It ...
- SpringBoot 之Spring Boot Starter依赖包及作用(自己还没有看)
spring-boot-starter 这是Spring Boot的核心启动器,包含了自动配置.日志和YAML. spring-boot-starter-amqp 通过spring-rabbit来支持 ...
- Python 装饰器(Decorators) 超详细分类实例
Python装饰器分类 Python 装饰器函数: 是指装饰器本身是函数风格的实现; 函数装饰器: 是指被装饰的目标对象是函数;(目标对象); 装饰器类 : 是指装饰器本身是类风格的实现; 类 ...
- Java实现PV操作 | 读者与写者(在三种情况下进行讨论)
注 :本文应结合[天勤笔记]进行学习. 1.读者优先 设置rmutex信号量来对readcount变量进行互斥访问.mutex信号量对写者与读者进行同步. static syn rmutex=new ...
- 【JZOJ5551】【20190625】旅途
题目 \(n\)个点\(m\)条边的无向图,一条路径的代价定义为路径上前\(k\)大边的边权和 对于$k = n \to 1 $,求1-n的最短路 \(n,m \le 3000 \ , \ w_i \ ...
- js字符串连接
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> </head> ...