数据库访问优化之四:减少数据库服务器CPU运算
1、使用绑定变量
绑定变量是指SQL中对变化的值采用变量参数的形式提交,而不是在SQL中直接拼写对应的值。
非绑定变量写法:Select * from employee where id=1234567
绑定变量写法:
Select * from employee where id=?
Preparestatement.setInt(1,1234567)
Java中Preparestatement就是为处理绑定变量提供的对像,绑定变量有以下优点:
1、防止SQL注入
2、提高SQL可读性
3、提高SQL解析性能,不使用绑定变更我们一般称为硬解析,使用绑定变量我们称为软解析。
第1和第2点很好理解,做编码的人应该都清楚,这里不详细说明。关于第3点,到底能提高多少性能呢,下面举一个例子说明:
假设有这个这样的一个数据库主机:
2个4核CPU
100块磁盘,每个磁盘支持IOPS为160
业务应用的SQL如下:
select * from table where pk=?
这个SQL平均4个IO(3个索引IO+1个数据IO)
IO缓存命中率75%(索引全在内存中,数据需要访问磁盘)
SQL硬解析CPU消耗:1ms (常用经验值)
SQL软解析CPU消耗:0.02ms(常用经验值)
假设CPU每核性能是线性增长,访问内存Cache中的IO时间忽略,要求计算系统对如上应用采用硬解析与采用软解析支持的每秒最大并发数:
|
是否使用绑定变量 |
CPU支持最大并发数 |
磁盘IO支持最大并发数 |
|
不使用 |
2*4*1000=8000 |
100*160=16000 |
|
使用 |
2*4*1000/0.02=400000 |
100*160=16000 |
从以上计算可以看出,不使用绑定变量的系统当并发达到8000时会在CPU上产生瓶颈,当使用绑定变量的系统当并行达到16000时会在磁盘IO上产生瓶颈。所以如果你的系统CPU有瓶颈时请先检查是否存在大量的硬解析操作。
使用绑定变量为何会提高SQL解析性能,这个需要从数据库SQL执行原理说明,一条SQL在Oracle数据库中的执行过程如下图所示:
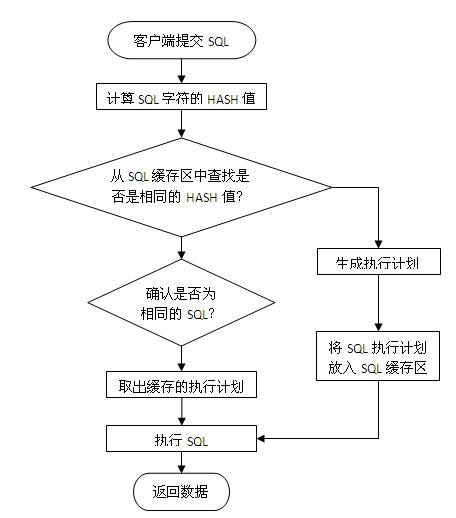
当一条SQL发送给数据库服务器后,系统首先会将SQL字符串进行hash运算,得到hash值后再从服务器内存里的SQL缓存区中进行检索,如果有相同的SQL字符,并且确认是同一逻辑的SQL语句,则从共享池缓存中取出SQL对应的执行计划,根据执行计划读取数据并返回结果给客户端。
如果在共享池中未发现相同的SQL则根据SQL逻辑生成一条新的执行计划并保存在SQL缓存区中,然后根据执行计划读取数据并返回结果给客户端。
为了更快的检索SQL是否在缓存区中,首先进行的是SQL字符串hash值对比,如果未找到则认为没有缓存,如果存在再进行下一步的准确对比,所以要命中SQL缓存区应保证SQL字符是完全一致,中间有大小写或空格都会认为是不同的SQL。
如果我们不采用绑定变量,采用字符串拼接的模式生成SQL,那么每条SQL都会产生执行计划,这样会导致共享池耗尽,缓存命中率也很低。
一些不使用绑定变量的场景:
a、数据仓库应用,这种应用一般并发不高,但是每个SQL执行时间很长,SQL解析的时间相比SQL执行时间比较小,绑定变量对性能提高不明显。数据仓库一般都是内部分析应用,所以也不太会发生SQL注入的安全问题。
b、数据分布不均匀的特殊逻辑,如产品表,记录有1亿,有一产品状态字段,上面建有索引,有审核中,审核通过,审核未通过3种状态,其中审核通过9500万,审核中1万,审核不通过499万。
要做这样一个查询:
select count(*) from product where status=?
采用绑定变量的话,那么只会有一个执行计划,如果走索引访问,那么对于审核中查询很快,对审核通过和审核不通过会很慢;如果不走索引,那么对于审核中与审核通过和审核不通过时间基本一样;
对于这种情况应该不使用绑定变量,而直接采用字符拼接的方式生成SQL,这样可以为每个SQL生成不同的执行计划,如下所示。
select count(*) from product where status='approved'; //不使用索引
select count(*) from product where status='tbd'; //不使用索引
select count(*) from product where status='auditing';//使用索引
2、合理使用排序
Oracle的排序算法一直在优化,但是总体时间复杂度约等于nLog(n)。普通OLTP系统排序操作一般都是在内存里进行的,对于数据库来说是一种CPU的消耗,曾在PC机做过测试,单核普通CPU在1秒钟可以完成100万条记录的全内存排序操作,所以说由于现在CPU的性能增强,对于普通的几十条或上百条记录排序对系统的影响也不会很大。但是当你的记录集增加到上万条以上时,你需要注意是否一定要这么做了,大记录集排序不仅增加了CPU开销,而且可能会由于内存不足发生硬盘排序的现象,当发生硬盘排序时性能会急剧下降,这种需求需要与DBA沟通再决定,取决于你的需求和数据,所以只有你自己最清楚,而不要被别人说排序很慢就吓倒。
以下列出了可能会发生排序操作的SQL语法:
Order by
Group by
Distinct
Exists子查询
Not Exists子查询
In子查询
Not In子查询
Union(并集),Union All也是一种并集操作,但是不会发生排序,如果你确认两个数据集不需要执行去除重复数据操作,那请使用Union All 代替Union。
Minus(差集)
Intersect(交集)
Create Index
Merge Join,这是一种两个表连接的内部算法,执行时会把两个表先排序好再连接,应用于两个大表连接的操作。如果你的两个表连接的条件都是等值运算,那可以采用Hash Join来提高性能,因为Hash Join使用Hash 运算来代替排序的操作。具体原理及设置参考SQL执行计划优化专题。
3、减少比较操作
我们SQL的业务逻辑经常会包含一些比较操作,如a=b,a<b之类的操作,对于这些比较操作数据库都体现得很好,但是如果有以下操作,我们需要保持警惕:
Like模糊查询,如下所示:
a like ‘%abc%’
Like模糊查询对于数据库来说不是很擅长,特别是你需要模糊检查的记录有上万条以上时,性能比较糟糕,这种情况一般可以采用专用Search或者采用全文索引方案来提高性能。
不能使用索引定位的大量In List,如下所示:
a in (:1,:2,:3,…,:n) ----n>20
如果这里的a字段不能通过索引比较,那数据库会将字段与in里面的每个值都进行比较运算,如果记录数有上万以上,会明显感觉到SQL的CPU开销加大,这个情况有两种解决方式:
a、 将in列表里面的数据放入一张中间小表,采用两个表Hash Join关联的方式处理;
b、 采用str2varList方法将字段串列表转换一个临时表处理,关于str2varList方法可以在网上直接查询,这里不详细介绍。
以上两种解决方案都需要与中间表Hash Join的方式才能提高性能,如果采用了Nested Loop的连接方式性能会更差。
如果发现我们的系统IO没问题但是CPU负载很高,就有可能是上面的原因,这种情况不太常见,如果遇到了最好能和DBA沟通并确认准确的原因。
4、大量复杂运算在客户端处理
什么是复杂运算,一般我认为是一秒钟CPU只能做10万次以内的运算。如含小数的对数及指数运算、三角函数、3DES及BASE64数据加密算法等等。
如果有大量这类函数运算,尽量放在客户端处理,一般CPU每秒中也只能处理1万-10万次这样的函数运算,放在数据库内不利于高并发处理。
数据库访问优化之四:减少数据库服务器CPU运算的更多相关文章
- 数据库访问优化漏斗法则- 四、减少数据库服务器CPU运算
数据库访问优化漏斗法则这个优化法则归纳为5个层次:1.减少数据访问次数(减少磁盘访问)2.返回更少数据(减少网络传输或磁盘访问)3.减少交互次数(减少网络传输)4.减少服务器CPU开销(减少CPU及内 ...
- 架构-数据库访问-SQL语言进行连接数据库服务器:SQL语言进行连接数据库服务器
ylbtech-架构-数据库访问-SQL语言进行连接数据库服务器:SQL语言进行连接数据库服务器 数据库和应用服务器的连接. 在基于三层构架的信息系统开发中,应用服务器要利用SQL语言进行连接数据库服 ...
- 架构-数据库访问-SQL语言进行连接数据库服务器-OLE:OLE
ylbtech-架构-数据库访问-SQL语言进行连接数据库服务器-OLE:OLE Object Linking and Embedding,对象连接与嵌入,简称OLE技术.OLE 不仅是桌面应用程序集 ...
- 架构-数据库访问-SQL语言进行连接数据库服务器-DAO:DAO
ylbtech-架构-数据库访问-SQL语言进行连接数据库服务器-DAO:DAO DAO(Data Access Object) 数据访问对象是一个面向对象的数据库接口,它显露了 Microsoft ...
- 【SQL server初级】数据库性能优化一:数据库自身优化(大数据量)
数据库优化包含以下三部分,数据库自身的优化,数据库表优化,程序操作优化.此文为第一部分 数据库性能优化一:数据库自身优化 优化①:增加次数据文件,设置文件自动增长(粗略数据分区) 1.1:增加次数据文 ...
- 「Django」数据库访问优化
先做性能分析 - 两个工具 django.db.connection from django.db import connection# contextprint connection.queries ...
- 架构-数据库访问-SQL语言进行连接数据库服务器-DB-Library:DB-Library
ylbtech-数据库访问-SQL语言进行连接数据库服务器-DB-Library:DB-Library 1.返回顶部 1. 在基于三层构架的信息系统开发中,应用服务器要利用SQL语言进行连接数据库服务 ...
- 数据库SQL优化百万级数据库优化方案
1.对查询进行优化,要尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索 ...
- c#数据库访问服务(综合数据库操作)
前面给大家说封装了常用的数据库,并且整理了使用.最近我再次把项目整合了.做成比较完善的服务. 还是重复的说下数据库操作封装. berkeley db数据库,Redis数据库,sqlite数据库. 每个 ...
随机推荐
- 『Go基础』第7节 变量
1. 什么是变量? 我们应该怎么去理解变量? 在这里我要举一个例子: 大家应该都知道王者荣耀这个游戏. 当我们在玩王者荣耀的时候, 我们操控的英雄的血量是不断变化的, 这个血量是存在内存中的. 那么这 ...
- 作为一个纯粹数据结构的 Redis Streams
来源:antirez 翻译:Kevin (公众号:中间件小哥) Redis 5 中引入了一个名为 Streams 的新的 Redis 数据结构,吸引了社区极大的兴趣.接下来,我会在社区里进行调查,同用 ...
- NGINX 配置本地HTTPS(双向认证)
一.SSL协议加密方式 SSL协议即用到了对称加密也用到了非对称加密(公钥加密),在建立传输链路时,SSL首先对对称加密的密钥使用公钥进行非对称加密,链路建立好之后,SSL对传输内容使用对称加密. 1 ...
- 查看线程CPU利用率
查看线程CPU利用率 方法1:利用ps命令查看对应的线程 1. ps -ef | grep 进程名称 2. ps -mp 进程ID -o THREAD,pid,tid,cmd,time,%cpu,%m ...
- windows 查看端口占用以及解决办法
windows 下查看所有端口程序1 netstat -ano 查看所有的端口占用情况2 netstat -ano|findstr "443" 查看端口为443的程序占用情况3 t ...
- C#判断字符串中包含某个字符的个数
//定义字符串 var Email= "humakesdkj@idsk@"; //获取@字符出现的次数 int num = Regex.Matches(Email, "@ ...
- .net core使用ocelot---第六篇 负载均衡
简介 .net core使用ocelot---第一篇 简单使用 .net core使用ocelot---第二篇 身份验证 .net core使用ocelot---第三篇 日志记录 .net core ...
- 实现负载均衡的小demo
首先我们先来了解负载均衡: 负载均衡是为了缓解网络压力的,服务器端进行扩容的重要手段 实现有两种方式:硬件F5 . 软件nginx.Dubbo 为了实现负载均衡的原理,我们基于以下两篇随笔继 ...
- 【阿里云开发】- 安装MySQL数据库
我用的机器配置是 阿里云轻量服务器,系统:CentOS7.3,内存:2G,系统盘40G,1核. 在CentOS中默认安装有MariaDB,这个是MySQL的分支,但为了需要,还是要在系统中安装MySQ ...
- 0.UML图入门——学习《大话设计模式》笔记
<大话设计模式>中讲述了UML类图的基本用法,做此笔记加深理解. 注:上图来源于<大话设计模式> 上图中设计的关键术语为:继承.实现.聚合.组合.关联.依赖. 要想弄清楚UML ...